数据库——大规模数据架构
目的
1 了解分布式数据库技术
2 了解并行数据库技术
3 了解云数据库技术
4 了解XML数据库技术
分布式数据库
1 分布式数据库系统
分布式数据库系统与分布式数据库的区别:
分布式数据库系统——分布式存储于若干场地,并且每个场地由独立其他场地DBMS 进行数据管理,物理分散,逻辑集中的数据库系统
分布式数据库——分布式数据库系统中各场地上数据库的逻辑集合
2 分布式数据库目标与数据分布策略
分布式数据库目标
12 个目标
本地自治;非集中式管理;高可用性(最基本特征)
位置独立性;数据分片独立性;数据复制独立性(分布透明性)
分布式查询;事务管理(复杂性)
硬件独立性;操作系统独立性;网络独立性
数据库管理系统独立性
数据分布策略:
从数据分片和数据分配策略
数据分片(对关系操作)
按一定规则将某一个全局关系划分为多个片段,四种基本方法:
水平分片 —— 每一分片是原始关系所有数据行的子集合
垂直分片 —— 每一分片是原始关系所有数据列的子集合
导出分片 —— 导出水平分片
混合切片 —— 以上三种的混合

数据分配(对分片结果操作)
将分片产生的片段存储在各个场地,解决数据分配的方法:
集中式 —— 将所有数据片段安排在一个场地上
分割式 —— 所有全局数据有且只有一份,分割成若干被分派在特定场地上的片段
全复制式 ——全局数据有多个副本,每个场地上有一个完整的数据副本
混合式 ——介于分割与全复制式之间

分布透明性
分布透明性,用户无需考虑数据分片
位置透明性。用户只需要考虑数据分片情况,无需考虑数据分片位置
局部数据模型透明性,用户既要了解全局数据的分片情况,还要了解各片段的副本复制情况及其位置分配情况

分布式数据库的相关技术
分布式查询
用户与分布式数据库系统的接口。分布式查询优化需考虑:
1 操作执行的顺序
2 操作执行算法(连接操作和并操作)
3 不同场地间的数据流动的顺序
分布式事务管理
主要包括:
1 恢复控制:基于两阶段的提交协议
2 并发控制:基于封锁协议
并行数据库概述
并行数据库系统 —— 通过并行实现各种数据操作,如数据载入,索引建立,数据查询,可以提高系统的性能。
优势:曾强的可用性:当存储某个关系的场地系统崩溃时,可继续使用存储在别的场地的副本。
2 并行数据库系统结构
实现并行DBMS 的三种硬件结构
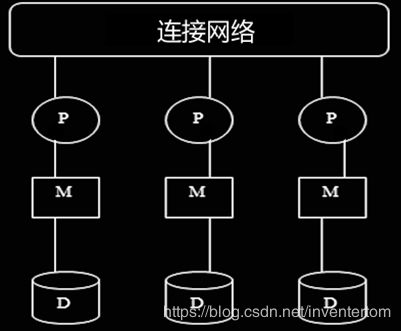
1 共享存储系统(Shared Memory)
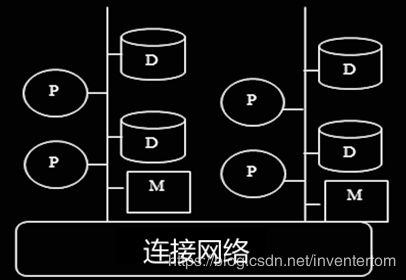
2 共享磁盘系统(Shared Disk)
3 无共享资源系统 (Shared Nothing )
4 层次结构(Hierachical)
并行数据库
(1)共享内存系统:多个cpu 通过连接网络进行通信,并能访问公共的主存
随着cpu 增加,造成内存冲突

(2)共享磁盘系统:每个cpu拥有自己私有内存,并通过连接网络直接访问所有磁盘
通过网络实现cpu之间的数据交换,增加了通信代价

(3)无共享资源系统:每个cou 拥有自己的内存和磁盘空间,并无公共区域,cpu 之间所有通信通过连接网络类完成
存在通信代价,非本地磁盘访问代价高
层次结构:前三种体系的结合。分为两层,顶层是无共享结构,底层是共享内存或共享磁盘结构
集成了以上三种结构的优缺点
3 数据划分与并行算法
一维数据划分:将大数据水平划分到多个磁盘上,可以通过并行读写有效地利用多磁盘的I/O宽带
(1)轮转法—— 如果系统有n个cpu ,将地i条记录划分到第i mod n 处理器的方法称为轮转划分方法
(2)散列法 —— 使用特定的哈希函数,作用于选定的属性,将记录花饭到不同的处理机
(3)范围划分法 —— 首先对记录进行排序,然后按照排序码将其划分成n个区域,使每个区域中近似的记录分布于处理机i
优势与劣势
(1)轮转法可有效应应用于需要访问整个关系的查询处理,当需要访问部分记录时,散列法和范围更优
(2)范围法可能会导致数据偏斜,也就是不同分区含有的记录数据差别很大,数据偏斜会造成存有大片数据分片的处理机的性能瓶颈问题
(3)散列法优点:即使数据随时间增加或减少,也能保持均匀分布
多维数据划分:
CMD 多维划分法
BERD 多维划分法
MAGIC 多维划分法
并行算法:
a.用区域划分法将关系的所有记录重新分布在进行排序
b.每个cpu使用排序算法对分配给它的记录排序,每个出路机得到分哦诶给它的所有记录的有序排序。每个处理机达到分配给它的所有记录的有序序列
c 通过按照区域划分对应次序访问处理机得到玩着呢个的有序关系
(2)并行连接
假设:对关系A 和 B 进行划分时,连接属性为age, 关系初始分布在若干磁盘上,若不是基于连接属性分布的
方法:对关系A和B 重新划分;把连接属性age 的取值分成k个区域
云计算概述
云计算是一种商业计算模型,它将计算任务在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算力,存储空间和信息服务
云计算数据库架构

云计算服务类型

云计算数据库架构
云(cloud):即云计算提供商的数据中心的软硬件设施
云分为:
公共云:即用即付的方式提供给公众
私有云:不对公众开放的云
混合云
云数据库体系结构
云数据库(CloudDB,简称云库):云 + 数据库
目前只要的云计算平台:
AWS(Amazon Web Series)
GAE (Google AppEngine)
Hadoop
云计算体系结构

谷歌云 计算基础架构模式(4个字系统)
Google File System 文件系统
Map/Reduce 分布式编程环境
Chubby 分布式锁机制
BigTable 大规模分布式数据库
云计算数据库与传统数据库比较
数据库的缺点:
数据安全问题
对云的管理问题
对因特网的依赖
1 XML 数据库系统
XML,eXtensibel Markup Language 可扩展标识语言
XML 数据库 —— 支持对XML 文档格式进行存储和查询等操作的数据库管理系统
三种类型的XML 数据库:
XML Enabled Database(XEDB)—— 能处理XML 数据库
Native XML Database(NXD) ——纯XML 数据库
Hybird XML Database (HXD) —— 混合XML 数据库
与传统数据库比较,XML 数据库优势:
能够对半结构化数据进行处理
提供对标签和路径的操作
能侵袭地表达数据的层次特征
2