增强学习简单案例实现
增强学习–斯坦福公开课(吴恩达)案例实现
增强学习作为一种重要的机器学习方法,其最显著的特点是通过与环境交互,利用环境反馈的奖惩,即增强信号来调整和改善自己的行为,最终获得最佳策略。由于该方法具有对环境的先验知识要求低,可以在实时环境中进行在线学习,因此受到许多研究者的关注,同时在智能控制,序列决策等领域也得到了广泛应用。–来自
最近看了斯课斯坦福大学公开课 :机器学习课程的第16讲,马尔科夫决策过程。链接如下(http://open.163.com/movie/2008/1/2/N/M6SGF6VB4_M6SGKSC2N.html)。
课上吴恩达老师讲了一个例子,课下我把它实现出来。
例子描述
想象你有一个机器人,它处在一个网格世界里,给它的任务是最终到达(4,3),但它不能到达(4,2),那里是个陷阱,进去了机器人就损坏了。在(2,2)处有一个柱子,碰到柱子将会停留在原地,网格世界只有4 ×3 大小,可以理解为周围都是高墙,机器人碰到墙,就会停留在原地。

现在这个机器人可以站在上图中黄色区域,它可以往东西南北走,但是由于控制精度原因,它只有0.8的概率可以走到预定位置,例如,机器人在(3,1)区域,往北(N)走,那么它有0.8的概率走到(3,2),0.1的概率走到(2,1),0.1的概率走到(4,1),再例如,机器人在(1,1),往北走,那么它有0.8的概率走到(1,2),0.1的概率走到(2,1),0.1的概率走到(1,1),因为机器人左边是高墙,它会停留在原地。
目标:在任意黄色位置,求机器人行走最佳轨迹,到达(4,3)
增强学习理论部分
理论部分请看视频教程,网上也有相应的中文课件,仔细学习,相信是不难的。这里主要说一下马尔科夫决策过程(MDP)的几个参数还有公式。
MDP由五元组构成 (S,A,Psa,γ,R) ,这里状态S就是机器人所处的各种位置,A就是东南西北(E,S,W,N), Psa 表示状态转移概率,就是上例中的0.8,0.1,0.1。 γ 是阻尼系数,给0.99。 R 是回报函数, R((4,3))=+1 , R((4,2))=−1 , R((others))=−0.02 。
这里我们采用值迭代

得到 V∗ ,之后使用公式3,得到最优策略,也就是最优ACTION
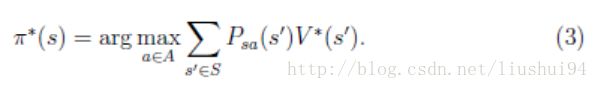
代码实现部分,纯手工
#coding:utf-8
'''
用于迭代计算V_star
案例是吴恩达的视频提供的数据
这里是值迭代,异步迭代
学习使用git
学写类
'''
import matplotlib.pyplot as plt
#初始化所有的v(s),vs[2][4] vs[3][4]接下来不更新,vs[2][2]也不更新(可以理解为柱子)
class RL(object):
def __init__(self,i):
self.i = i
def max_cal_sum_pv(self,j,k,vs):
value = 0
if j+1==1 and k+1==1:
value_N = 0.8*vs[j][k+1]+0.1*vs[j][k]+0.1*vs[j+1][k]
value_E = 0.8*vs[j+1][k]+0.1*vs[j][k]+0.1*vs[j][k+1]
value = max(value_N,value_E)
elif j+1==1 and k+1==2:
value_N = 0.8*vs[j][k+1]+0.1*vs[j][k]+0.1*vs[j][k]
value_S = 0.8*vs[j][k]+0.1*vs[j][k]+0.1*vs[j][k]
value = max(value_N,value_S)
elif j+1==1 and k+1==3:
value_E = 0.8*vs[j+1][k]+0.1*vs[j][k]+0.1*vs[j][k-1]
value_S = 0.8*vs[j][k-1]+0.1*vs[j][k]+0.1*vs[j+1][k]
value = max(value_E,value_S)
elif j+1==2 and k+1==1:
value_W = 0.8*vs[j-1][k]+0.1*vs[j][k]+0.1*vs[j][k]
value_E = 0.8*vs[j+1][k]+0.1*vs[j][k]+0.1*vs[j][k]
value = max(value_W,value_E)
elif j+1==2 and k+1==3:
value_W = 0.8*vs[j-1][k]+0.1*vs[j][k]+0.1*vs[j][k]
value_E = 0.8*vs[j+1][k]+0.1*vs[j][k]+0.1*vs[j][k]
value = max(value_W,value_E)
elif j+1==3 and k+1==1:
value_N = 0.8*vs[j][k+1]+0.1*vs[j-1][k]+0.1*vs[j+1][k]
value_W = 0.8*vs[j-1][k]+0.1*vs[j][k]+0.1*vs[j][k+1]
value_E = 0.8*vs[j+1][k]+0.1*vs[j][k]+0.1*vs[j][k+1]
value = max(value_W,value_E)
value = max(value,value_N)
elif j+1==3 and k+1==2:
value_N = 0.8*vs[j][k+1]+0.1*vs[j][k]+0.1*vs[j+1][k]
value_S = 0.8*vs[j][k-1]+0.1*vs[j][k]+0.1*vs[j+1][k]
value_E = 0.8*vs[j+1][k]+0.1*vs[j][k+1]+0.1*vs[j][k-1]
value = max(value_S,value_E)
value = max(value,value_N)
elif j+1==3 and k+1==3:
value_S = 0.8*vs[j][k-1]+0.1*vs[j-1][k]+0.1*vs[j+1][k]
value_W = 0.8*vs[j-1][k]+0.1*vs[j][k]+0.1*vs[j][k-1]
value_E = 0.8*vs[j+1][k]+0.1*vs[j][k]+0.1*vs[j][k-1]
value = max(value_S,value_E)
value = max(value,value_W)
elif j+1==4 and k+1==1:
value_N = 0.8*vs[j][k+1]+0.1*vs[j][k]+0.1*vs[j-1][k]
value_W = 0.8*vs[j-1][k]+0.1*vs[j][k]+0.1*vs[j][k+1]
value = max(value_N,value_W)
else:
pass
return value
def val_iteration(self):
RS=-0.02
GAMMA=0.99
vs=[[0,0,0],[0,0,0],[0,0,0],[0,-1,1]]
for i in range(self.i):
for j in range(4):
# print "j=",j
for k in range(3):
# print "k=",k
if not ((j+1==2 and k+1==2)or(j+1==4 and k+1==2)or(j+1==4 and k+1==3)):
# print j," ",k
vs[j][k] = RS +GAMMA*self.max_cal_sum_pv(j,k,vs)
plt.plot(i,vs[0][0],'*-')
plt.savefig("./examples.jpg")
print vs
return vs
def cal_pi_star(self,vs):
pi_star = list()
for i in range(4):#列
for j in range(3):#行
if i+1==1 and j+1==1:
pi_star_N = 0.8*vs[i][j+1]+0.1*vs[i][j]+0.1*vs[i+1][j]
pi_star_W = 0.8*vs[i][j]+0.1*vs[i][j+1]+0.1*vs[i][j]
pi_star_E = 0.8*vs[i+1][j]+0.1*vs[i][j]+0.1*vs[i][j]
pi_star_S = 0.8*vs[i][j]+0.1*vs[i][j]+0.1*vs[i+1][j]
pi_star_max = max(pi_star_N,pi_star_W,pi_star_E,pi_star_S)
if pi_star_max==pi_star_N:
pi_star.append("N")
elif pi_star_max ==pi_star_E:
pi_star.append("E")
elif pi_star_max ==pi_star_W:
pi_star.append("W")
else:
pi_star.append("S")
elif i+1==1 and j+1==2:
pi_star_N = 0.8*vs[i][j+1]+0.1*vs[i][j]+0.1*vs[i][j]
pi_star_W = 0.8*vs[i][j]+0.1*vs[i][j+1]+0.1*vs[i][j-1]
pi_star_E = 0.8*vs[i][j]+0.1*vs[i][j+1]+0.1*vs[i][j-1]
pi_star_S = 0.8*vs[i][j-1]+0.1*vs[i][j]+0.1*vs[i][j]
pi_star_max = max(pi_star_N,pi_star_W,pi_star_E,pi_star_S)
if pi_star_max==pi_star_N:
pi_star.append("N")
elif pi_star_max ==pi_star_E:
pi_star.append("E")
elif pi_star_max ==pi_star_W:
pi_star.append("W")
else:
pi_star.append("S")
elif i+1==1 and j+1==3:
pi_star_N = 0.8*vs[i][j]+0.1*vs[i][j]+0.1*vs[i+1][j]
pi_star_W = 0.8*vs[i][j]+0.1*vs[i][j-1]+0.1*vs[i][j]
pi_star_E = 0.8*vs[i+1][j]+0.1*vs[i][j]+0.1*vs[i][j]
pi_star_S = 0.8*vs[i][j-1]+0.1*vs[i][j]+0.1*vs[i+1][j]
pi_star_max = max(pi_star_N,pi_star_W,pi_star_E,pi_star_S)
if pi_star_max==pi_star_N:
pi_star.append("N")
elif pi_star_max ==pi_star_E:
pi_star.append("E")
elif pi_star_max ==pi_star_W:
pi_star.append("W")
else:
pi_star.append("S")
elif i+1==2 and j+1==1:
pi_star_N = 0.8*vs[i][j]+0.1*vs[i-1][j]+0.1*vs[i+1][j]
pi_star_W = 0.8*vs[i-1][j]+0.1*vs[i][j]+0.1*vs[i][j]
pi_star_E = 0.8*vs[i+1][j]+0.1*vs[i][j]+0.1*vs[i][j]
pi_star_S = 0.8*vs[i][j]+0.1*vs[i-1][j]+0.1*vs[i+1][j]
pi_star_max = max(pi_star_N,pi_star_W,pi_star_E,pi_star_S)
if pi_star_max==pi_star_N:
pi_star.append("N")
elif pi_star_max ==pi_star_E:
pi_star.append("E")
elif pi_star_max ==pi_star_W:
pi_star.append("W")
else:
pi_star.append("S")
elif i+1==2 and j+1==2:
pi_star.append("0")
elif i+1==2 and j+1==3:
pi_star_N = 0.8*vs[i][j]+0.1*vs[i-1][j]+0.1*vs[i+1][j]
pi_star_W = 0.8*vs[i-1][j]+0.1*vs[i][j]+0.1*vs[i][j]
pi_star_E = 0.8*vs[i+1][j]+0.1*vs[i][j]+0.1*vs[i][j]
pi_star_S = 0.8*vs[i][j]+0.1*vs[i-1][j]+0.1*vs[i+1][j]
pi_star_max = max(pi_star_N,pi_star_W,pi_star_E,pi_star_S)
if pi_star_max==pi_star_N:
pi_star.append("N")
elif pi_star_max ==pi_star_E:
pi_star.append("E")
elif pi_star_max ==pi_star_W:
pi_star.append("W")
else:
pi_star.append("S")
elif i+1==3 and j+1==1:
pi_star_N = 0.8*vs[i][j+1]+0.1*vs[i-1][j]+0.1*vs[i+1][j]
pi_star_W = 0.8*vs[i-1][j]+0.1*vs[i][j]+0.1*vs[i][j+1]
pi_star_E = 0.8*vs[i+1][j]+0.1*vs[i][j]+0.1*vs[i][j+1]
pi_star_S = 0.8*vs[i][j]+0.1*vs[i-1][j]+0.1*vs[i+1][j]
pi_star_max = max(pi_star_N,pi_star_W,pi_star_E,pi_star_S)
if pi_star_max==pi_star_N:
pi_star.append("N")
elif pi_star_max ==pi_star_E:
pi_star.append("E")
elif pi_star_max ==pi_star_W:
pi_star.append("W")
else:
pi_star.append("S")
elif i+1==3 and j+1==2:
pi_star_N = 0.8*vs[i][j+1]+0.1*vs[i][j]+0.1*vs[i+1][j]
pi_star_W = 0.8*vs[i][j]+0.1*vs[i][j+1]+0.1*vs[i][j-1]
pi_star_E = 0.8*vs[i+1][j]+0.1*vs[i][j+1]+0.1*vs[i][j-1]
pi_star_S = 0.8*vs[i][j-1]+0.1*vs[i][j]+0.1*vs[i+1][j]
pi_star_max = max(pi_star_N,pi_star_W,pi_star_E,pi_star_S)
if pi_star_max==pi_star_N:
pi_star.append("N")
elif pi_star_max ==pi_star_E:
pi_star.append("E")
elif pi_star_max ==pi_star_W:
pi_star.append("W")
else:
pi_star.append("S")
elif i+1==3 and j+1==3:
pi_star_N = 0.8*vs[i][j]+0.1*vs[i-1][j]+0.1*vs[i+1][j]
pi_star_W = 0.8*vs[i-1][j]+0.1*vs[i][j]+0.1*vs[i][j-1]
pi_star_E = 0.8*vs[i+1][j]+0.1*vs[i][j]+0.1*vs[i][j-1]
pi_star_S = 0.8*vs[i][j-1]+0.1*vs[i-1][j]+0.1*vs[i+1][j]
pi_star_max = max(pi_star_N,pi_star_W,pi_star_E,pi_star_S)
if pi_star_max==pi_star_N:
pi_star.append("N")
elif pi_star_max ==pi_star_E:
pi_star.append("E")
elif pi_star_max ==pi_star_W:
pi_star.append("W")
else:
pi_star.append("S")
elif i+1==4 and j+1==1:
pi_star_N = 0.8*vs[i][j+1]+0.1*vs[i][j]+0.1*vs[i-1][j]
pi_star_W = 0.8*vs[i-1][j]+0.1*vs[i][j]+0.1*vs[i][j+1]
pi_star_E = 0.8*vs[i][j]+0.1*vs[i][j+1]+0.1*vs[i][j]
pi_star_S = 0.8*vs[i][j]+0.1*vs[i][j]+0.1*vs[i-1][j]
pi_star_max = max(pi_star_N,pi_star_W,pi_star_E,pi_star_S)
if pi_star_max==pi_star_N:
pi_star.append("N")
elif pi_star_max ==pi_star_E:
pi_star.append("E")
elif pi_star_max ==pi_star_W:
pi_star.append("W")
else:
pi_star.append("S")
elif i+1==4 and j+1==2:
pi_star.append("-1")
else:
pi_star.append("+1")
print pi_star
def main():
a = RL(100)
vs = a.val_iteration()#计算V_STAR
a.cal_pi_star(vs)#计算最佳策略
if __name__=="__main__":
main()结果
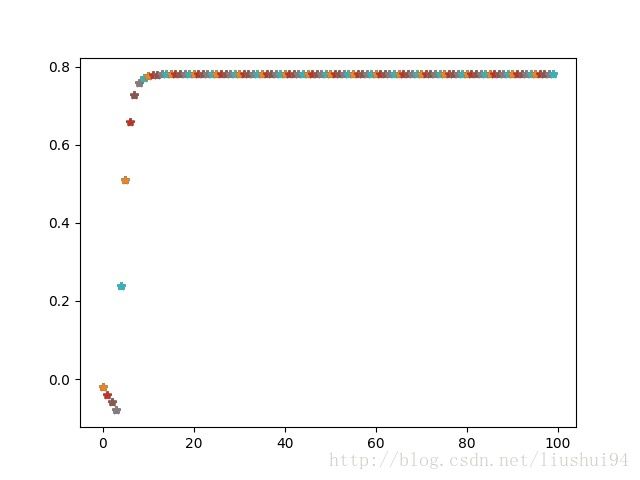
上图是值迭代时,VS[0][0]的收敛情况,可以看出十多次次迭代后就收敛了。
得到的 V∗ 为:
[[0.7802612818022052, 0.8196989158563343, 0.8553011748949244], [0.7455946822784869, 0, 0.8958032397860478], [0.7087382081926513, 0.6874963355254275, 0.9323664120055686], [0.49092193217378455, -1, 1]]
最佳策略 π∗ 为:
[‘N’, ‘N’, ‘E’, ‘W’, ‘0’, ‘E’, ‘W’, ‘N’, ‘E’, ‘W’, ‘-1’, ‘+1’]
与视频上吴恩达老师得到的结果一致。

