架构师眼中的CRUD:分库分表下的数据查询那些事(上)
声明
下面的故事,记录的技术要点,是真实发生在我身上的。为了记录下这些知识点,同时让大家以一个放松的心态去进行阅读,将其改编成诙谐幽默的小故事。
故事人物介绍:
S君:我们的产品爸爸,提的需求一般没有商量的余地~
H兄:我们的项目总监、技术负责人,老大哥的形象,一般也是问题的最后裁判员
C大:我们的架构师,技术涉猎面广,考虑问题全面
小L:刚入职公司的应届毕业生开发,对技术有着无比的热情~
KK:喜欢独自研究冷门技术的开发,不太喜欢凑热闹,2年java开发经验~
Q姐:别看是女生,技术上可是独当一面,能独立带项目,5年java开发经验~
如有雷同,纯属巧合。
前言
看似很简单的一个需求,有时候背后会有很大的学问,只有当你头脑中有各种各样条件下的解决方案,才能够想到你认知范围内的最优解,以及当前限制条件下的最优解;
这个案例,是我们作为开发人员会遇到的最基本的一项需求(写CRUD)。下面,就让我们一起来走进这个案例。
故事的背景
这是一个忙碌的下午,一个面向日活500万用户的XX APP的优惠券系统在评审完产品爸爸的需求之后,小L觉得挺简单的,不就是做一个简单的CRUD嘛,表也设计好了,现在都是SpringBoot的时代了,集成个mybatis,搞个mybatis-generator生成个样板代码,直接就搞定了。但是,既然我发了这篇博客,就意味着事情其实远没有这么简单。

言归正传,让我们来看一下产品爸爸的原型:
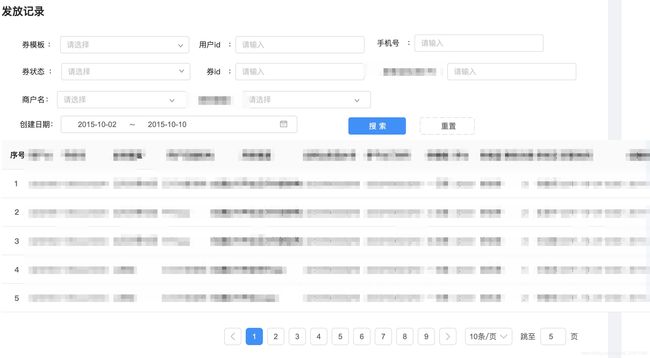
看到这个原型以后,刚入职的小L同学,马上自告奋勇的举手了,拍着胸脯说,看我半小时搞定!
KK听了以后,露出了诡异的笑容。然后说了句:“小L,这个需求就交给你了,最近测试环境的Quartz最近总是锁住,我得去看看那个问题先。bye~”
小L的第一个版本
他的实现方案是这样的。。。让我们一起来看一下:
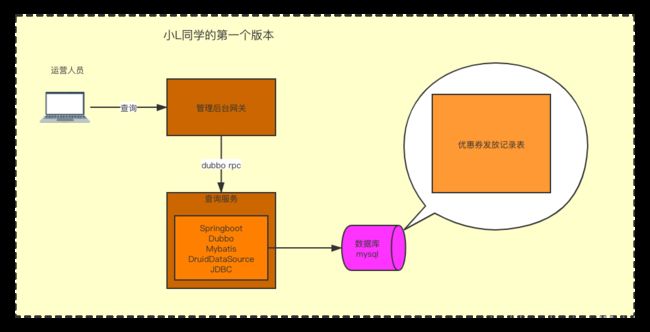
看着服务里面的东西挺多,由于大部分都可以通过springboot的starter,直接通过配置完成,所小L同学只用了半小时一顿咔咔。
小L:“我搞完了,接口文档马上补充好!前端搞一下就完事了。”
看着似乎像是那么回事,理论上来说,这套方案,确实是可以实现原型上的所有功能。
就在这时候,我们的架构师C大拖着疲惫的身体从外面回来了。

C大回来就是一个葛优躺,但是屁股还没坐热,小L就很激动的拿了他的方案和代码给C大看。
小L很期待能得到C大的认可

可是,C大看了一眼,都不到5秒钟,就问了小L一句话, “这个是我们现在接的XX APP优惠券这个项目吗?”
小L给了肯定答案,然后C大就皱起了眉头。
C大为什么会皱眉头?原因有下面几个:
- 优惠券发放表属于流水表,记录会不断累加,加之平台是面向日活500万用户的App,不能不考虑上线以后表数据量的问题
- 小L只考虑了管理后台做查询的业务,并没有考虑到前台用户看自己优惠券的问题,回头前台需求过来了,还得再写一套查询
小L立即明白自己的问题是出在哪里了。立即动手,不一会儿,第二个版本就出现了。
小L的第二个版本
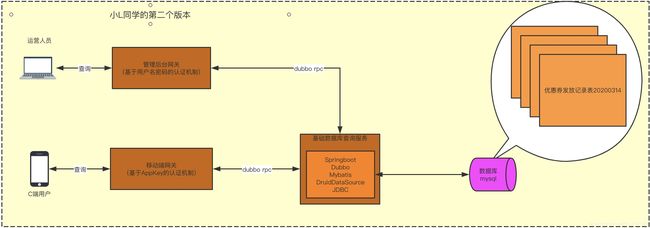
C大一看,有进步,但是还是存在问题,就问了下面两个简单的问题:
- 后台系统查询10天的数据,你怎么实现?
- 用户券列表页面,如果要展示1个月的数据,你怎么实现?
小L有些着急,马上回答说:
- 那就十表联查。
- 那。。。三十张表联查?不不不,产品的需求有问题吧,就限制他只能一天一天看咯。
产品爸爸S君倒水从边上走过,恰好听到产品需求有问题这句话,把小L是好一顿教育啊,

S君过完瘾就走了,C大马上安慰了小L,“能想到数据量大要分表,这个思路值得表扬,那么看看你的分表方式是否有问题?”
敲黑板
传统的按时间分表,确实非常适合流水表的可按照时间追溯特性。
但是在这么一个ToC的场景下,基于用户维度的查询,会非常头疼。
与此同时,每天的数据量并不一定会如此地均匀,可能会造成数据长尾(有的表数据特别多,有的特别少)。
所以在这种场景下,我们的主数据库(实时业务数据库)往往采用基于用户标识的分表策略。
小L的第三个版本
小L听了C大一番耐心细致的讲解,马上意识到自己刚才设计的问题在哪里了,第三版就这么出现了:
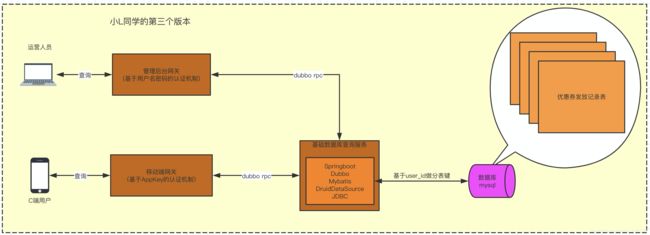
C大:嗯,这个版本,看起来,像是那么回事了。但是就主库来说还有一点点瑕疵,刚才我提到了数据长尾,那么如果直接根据user_id来做分表键的话,user_id如果分配不平均怎么办?
小L:这。。。有办法了!跟HashMap的原理一样,我们对user_id作一致性hash之后的作为分表键就可以解决这个问题啦!
C大:不错嘛!正是这样!
敲黑板
所谓的一致性hash,简单来说,就是对类似于一个单输入单输出的函数,对输入做一个计算
得到另一个均匀分布的输出,而且每次同样输入得到的输出是具有一致性的,而不是随机的
也就是说,一致行hash得到的结果,针对特定输入,一定是能得到相同输出结果的
一致性hash在分布式复杂均衡上,有着极为重要的应用
基于这个项目,我们的分表键计算公式就是下面这样了:
ShardingKey = Hash(user_id) & (tableNum - 1)
为什么一般用位与不用取余,这个大家看下这两个算子的效率即可。有过C/C++开发经验的同学,应该会很清楚,C++ STL源码里面,很多地方也都是使用位与运算来代替取余的。
常用的字符串一致性hash算法,一般是BKDRHash,这个算法这里就不给出了,网上很多,实现也很简单的。
C大接着说: “目前为止,C端用户的查询,应该说是问题不大了。但是,不要高兴太早哦,我们还漏掉了一个东西!”
那么,上面的解决方案真的就没问题了吗?C大说的漏掉的内容是哪一块呢?且听下回分解。