TensorFlow学习实践(五):基于vgg-16、inception_v3、resnet_v1_50模型进行fine-tune全过程
本文基于vgg-16、inception_v3、resnet_v1_50模型进行fine-tune,完成一个二分类模型的训练。
目录
一、环境准备
二、准备数据
三、数据解析及图片预处理
四、模型定义
五、模型训练
六、模型预测
最后:完整代码
一、环境准备
我使用了TensorFlow的model库中的slim模块,路径:https://github.com/tensorflow/models/tree/master/research/slim,clone下来之后,将整个model放到了环境目录\Lib\site-packages\tensorflow\下,之后可以删掉slim目录下的BUILD文件,运行:
python setup.py build
python setup.py install此处参考https://blog.csdn.net/lgczym/article/details/79272579
二、准备数据
我使用的是猫狗大战的数据,将原始图片数据转成了TFRecord格式
def image_to_tfrecord(image_list, label_list, record_dir):
writer = tf.python_io.TFRecordWriter(record_dir)
for image, label in zip(image_list, label_list):
with open(image, 'rb') as f:
encoded_jpg = f.read()
# with tf.gfile.GFile(image, 'rb') as fid:
# encoded_jpg = fid.read()
# img = cv2.imread(image)
# height, width, channel = img.shape
# img_raw = img.tobytes()
example = tf.train.Example(features=tf.train.Features(feature={
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[label])),
'img_raw': tf.train.Feature(bytes_list=tf.train.BytesList(value=[encoded_jpg]))
}))
writer.write(example.SerializeToString())
writer.close()
def get_tfrecord_data(data_dir):
image_list = []
label_list = []
for file in os.listdir(data_dir):
name = file.split('.')
image_list.append(os.path.join(data_dir, file))
if name[0] == 'cat':
label_list.append(0)
else:
label_list.append(1)
tmp = np.array([image_list, label_list])
tmp = tmp.transpose()
# This function only shuffles the array along the first axis, so we need to transpose
np.random.shuffle(tmp)
image_list = list(tmp[:, 0])
label_list = list(tmp[:, 1])
label_list = [int(i) for i in label_list]
with open('image_label_list.txt', 'w') as f:
for i in range(len(image_list)):
f.write(image_list[i] + '\t\t' + str(label_list[i]) + '\n')
train_images = int(0.8 * len(image_list))
image_to_tfrecord(image_list[:train_images], label_list[:train_images], './data/train_img.tfrecord')
image_to_tfrecord(image_list[train_images:], label_list[train_images:], './data/validation_img.tfrecord')
return image_list, label_list首先从数据目录下读取图片名称及其对应label,做shuffle处理,并将80%的数据作为训练集,20%的数据作为验证集。然后将两部分数据转成TFRecord格式,这里遇到一个坑,我先按之前熟悉的操作:
img = cv2.imread(image)
img_raw = img.tobytes()最后发现生成的TFRecord文件有8个G,以为处理错了,但是解析出来发现没有问题,后来在网上看到,有人说这样生成的TFRecord文件确实会很大,参考https://blog.csdn.net/qian99/article/details/79939466这篇文章进行了修改,结果大小正常。
三、数据解析及图片预处理
def preprocess(image, pre_trained_model, image_size, is_training):
if ('vgg_16' in pre_trained_model) or ('resnet_v1_50' in pre_trained_model):
processed_image = vgg_preprocessing.preprocess_image(image, image_size, image_size, is_training)
elif 'inception_v3' in pre_trained_model:
# processed_image = inception_preprocessing.preprocess_image(image, image_size, image_size, is_training)
image = tf.expand_dims(image, 0)
processed_image = tf.image.resize_bilinear(image, [image_size, image_size])
processed_image = tf.squeeze(processed_image)
processed_image.set_shape([None, None, 3])
else:
print('wrong input pre_trained_model')
return
return processed_image
def parse_and_preprocess_data(example_proto, pre_trained_model, image_size, is_training):
features = {'img_raw': tf.FixedLenFeature([], tf.string, ''),
'label': tf.FixedLenFeature([], tf.int64, 0)}
parsed_features = tf.parse_single_example(example_proto, features)
image = tf.image.decode_jpeg(parsed_features['img_raw'], channels=3)
label = tf.cast(parsed_features['label'], tf.int64)
image = tf.cast(image, tf.float32)
processed_image = preprocess(image, pre_trained_model, image_size, is_training)
return processed_image, label数据解析时,调用的是tf.image.decode_jpeg进行解析的,需要注意一下。
数据预处理采用的是各个模型的预处理模块,vgg_16和resnet_v1_50的预处理相同。在训练inception_v3时,如果用inception_v3的预处理过程,训练准确率一直不变,保持在50%左右,然后我换成直接进行resize,结果准确率就上去了。
四、模型定义
数据经过预处理后,就可以送入模型了。
def inference(pre_trained_model, processed_images, class_num, is_training):
if 'vgg_16' in pre_trained_model:
print('load model: vgg_16')
with slim.arg_scope(vgg.vgg_arg_scope()):
net, endpoints = vgg.vgg_16(processed_images, num_classes=None, is_training=is_training)
net = tf.squeeze(net, [1, 2])
logits = slim.fully_connected(net, num_outputs=class_num, activation_fn=None)
# fc6 = endpoints['vgg_16/fc6']
# net = tf.squeeze(fc6, [1, 2])
# logits = slim.fully_connected(net, num_outputs=class_num, activation_fn=None)
elif 'inception_v3' in pre_trained_model:
print('load model: inception_v3')
with slim.arg_scope(inception_v3.inception_v3_arg_scope()):
net, endpoints = inception_v3.inception_v3_base(processed_images)
kernel_size = inception_v3._reduced_kernel_size_for_small_input(net, [8, 8])
net = slim.avg_pool2d(net, kernel_size, padding='VALID',
scope='AvgPool_1a_{}x{}'.format(*kernel_size))
net = tf.squeeze(net, [1, 2])
logits = slim.fully_connected(net, num_outputs=class_num, activation_fn=None)
elif 'resnet_v1_50' in pre_trained_model:
with slim.arg_scope(resnet_v1.resnet_arg_scope()):
logits, endpoints = resnet_v1.resnet_v1_50(processed_images, class_num, is_training=is_training)
else:
print('wrong input pre_trained_model')
return
return logits
def loss(logits, labels):
tf.losses.sparse_softmax_cross_entropy(labels, logits)
loss = tf.losses.get_total_loss()
return loss这里都只修改了最后一层,vgg_16的模型图如下:
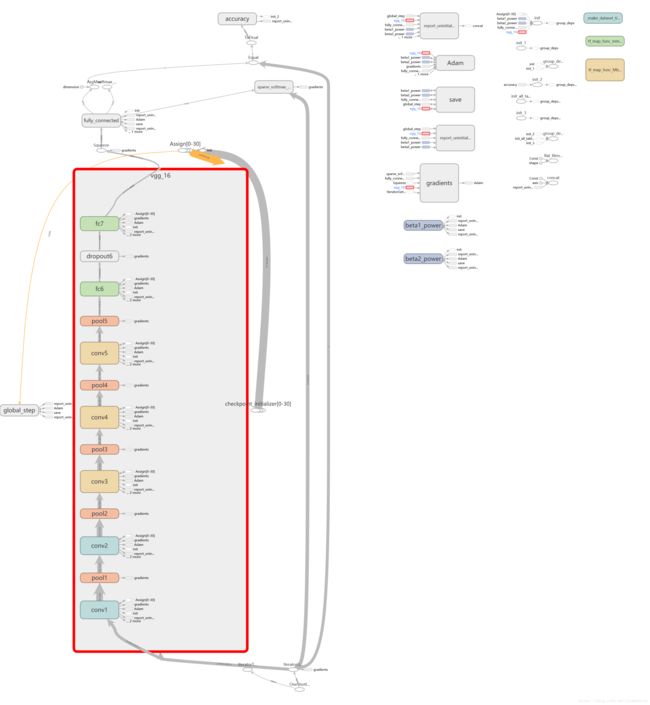
我们也可以多修改几层,上面注释部分的代码:
# fc6 = endpoints['vgg_16/fc6']
# net = tf.squeeze(fc6, [1, 2])
# logits = slim.fully_connected(net, num_outputs=class_num, activation_fn=None)这里可以通过endpoints获取之前某一层的输出,然后基于该层继续搭建模型,修改之后的模型图如下:
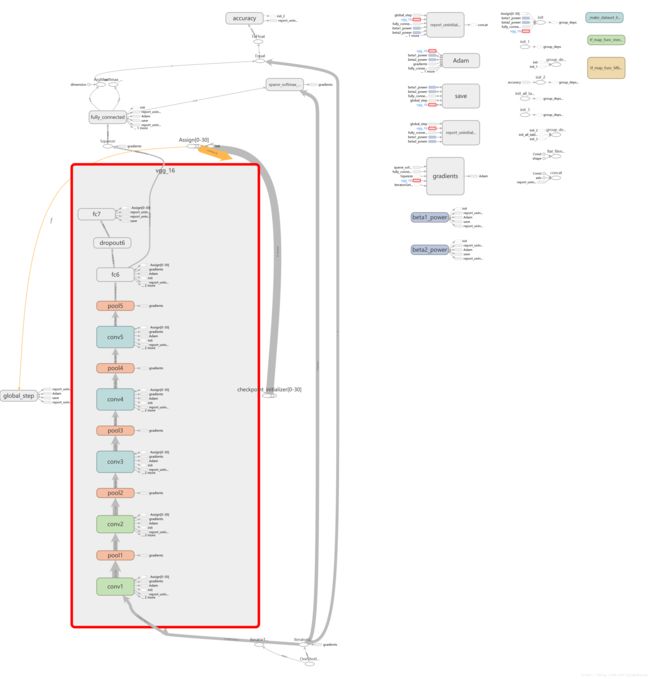
可以看到fc6的输出会连接到最后的全连接层。
五、模型训练
1、通过底层API进行训练
def evaluate(sess, top_k_op, training, examples):
iter_per_epoch = int(math.ceil(examples / FLAGS.batch_size))
# total_sample = iter_per_epoch * FLAGS.batch_size
correct_predict = 0
step = 0
while step < iter_per_epoch:
predict = sess.run(top_k_op, feed_dict={training: False})
correct_predict += np.sum(predict)
step += 1
precision = correct_predict / examples
return precision
def train(model_path, image_size):
training_dataset = tf.data.TFRecordDataset(['./data/train_img.tfrecord'])
training_dataset = training_dataset.map(
lambda example: model_input.parse_and_preprocess_data(example, model_path, image_size, True))
# dataset = dataset.shuffle(20000).batch(FLAGS.batch_size).repeat()
training_dataset = training_dataset.batch(FLAGS.batch_size).repeat()
validation_dataset = tf.data.TFRecordDataset(['./data/validation_img.tfrecord'])
validation_dataset = validation_dataset.map(
lambda example: model_input.parse_and_preprocess_data(example, model_path, image_size, False))
validation_dataset = validation_dataset.batch(FLAGS.batch_size)
iterator = tf.data.Iterator.from_structure(output_types=training_dataset.output_types,
output_shapes=training_dataset.output_shapes)
training_init_op = iterator.make_initializer(training_dataset)
validation_init_op = iterator.make_initializer(validation_dataset)
images, labels = iterator.get_next()
is_training = tf.placeholder(dtype=tf.bool)
logits = model_input.inference(model_path, images, 2, is_training)
pred = tf.nn.softmax(logits)
top_k_op = tf.nn.in_top_k(logits, labels, 1)
loss = model_input.loss(logits, labels)
variables_to_train, variables_to_restore = model_input.variables_to_restore_and_train(model_path)
global_step = tf.train.get_or_create_global_step()
train_op = model_input.get_train_op(loss, variables_to_train, variables_to_restore, FLAGS.batch_size,
FLAGS.learning_rate, global_step)
with tf.Session() as sess:
# sess = tf_debug.LocalCLIDebugWrapperSession(sess)
# 先初始化所有变量,避免有些变量未读取而产生错误
init = tf.global_variables_initializer()
sess.run(init)
# 建立一个从预训练模型checkpoint中读取上述列表中的相应变量的参数的函数
init_fn = slim.assign_from_checkpoint_fn(model_path, variables_to_restore, ignore_missing_vars=True)
# restore模型参数
init_fn(sess)
saver = tf.train.Saver()
sess.run(training_init_op)
print('begin to train!')
ckpt = os.path.join(FLAGS.log_dir, 'model.ckpt')
saver.save(sess, ckpt, 0)
train_step = 0
while train_step < FLAGS.max_step:
_, train_loss, logits_op, pred_op, labels_op = sess.run([train_op, loss, logits, pred, labels],
feed_dict={is_training: True})
# print('logits: {}, pred:{}, labels:{}, loss: {}'.format(logits_op, pred_op, labels_op, train_loss))
train_step += 1
if train_step % 100 == 0:
saver.save(sess, ckpt, train_step)
# print('step: {}, loss: {}'.format(train_step, train_loss))
sess.run(validation_init_op)
precision = evaluate(sess, top_k_op, is_training, model_input.VALIDATION_EXAMPLES_NUM)
print('step: {}, loss: {}, validation precision: {}'.format(train_step, train_loss, precision))
sess.run(training_init_op)
if train_step == FLAGS.max_step and train_step % 100 != 0:
saver.save(sess, ckpt, train_step)
print('step: {}, loss: {}'.format(train_step, train_loss))我们可以每训练一定步数后,对验证集进行验证,看准确率如何。我对模型的最后一层和其他层采取了不同的学习率,并使用了学习率衰减,上面代码中的variables_to_restore_and_train()和get_train_op()接口如下:
def variables_to_restore_and_train(pre_trained_model):
if 'vgg_16' in pre_trained_model:
exclude = ['fully_connected']
train_sc = ['fully_connected']
elif 'inception_v3' in pre_trained_model:
exclude = ['InceptionV3/Logits', 'InceptionV3/AuxLogits', 'fully_connected']
train_sc = ['fully_connected']
elif 'resnet_v1_50' in pre_trained_model:
exclude = ['resnet_v1_50/logits']
train_sc = ['resnet_v1_50/logits']
else:
exclude = []
train_sc = []
variables_to_restore = slim.get_variables_to_restore(exclude=exclude)
variables_to_train = []
for sc in train_sc:
variables_to_train += slim.get_trainable_variables(sc)
return variables_to_train, variables_to_restore
def get_train_op(total_loss, variables_to_train, variables_to_restore, batch_size, learning_rate, global_step):
num_batches_per_epoch = TRAINING_EXAMPLES_NUM / batch_size
decay_steps = int(num_batches_per_epoch)
# Decay the learning rate exponentially based on the number of steps.
lr = tf.train.exponential_decay(learning_rate=learning_rate,
global_step=global_step,
decay_steps=decay_steps,
decay_rate=0.9,
staircase=True)
opt1 = tf.train.GradientDescentOptimizer(lr)
opt2 = tf.train.GradientDescentOptimizer(0.01 * lr)
grads = tf.gradients(total_loss, variables_to_train + variables_to_restore)
grads1 = grads[:len(variables_to_train)]
grads2 = grads[len(variables_to_train):]
train_op1 = opt1.apply_gradients(zip(grads1, variables_to_train), global_step)
train_op2 = opt2.apply_gradients(zip(grads2, variables_to_restore))
train_op = tf.group(train_op1, train_op2)
return train_op这里的global_step只给了train_op1,如果两个都给,训练一次,值会加2.
训练:
train(model_path=FLAGS.vgg16_model_path, image_size=FLAGS.vgg16_image_size)训练结果(差不多训练了3个epoch,每继续训练,太费时):
vgg_16:
INFO:tensorflow:Restoring parameters from ./model/vgg_16.ckpt
begin to train!
step: 100, loss: 0.8198038935661316, validation precision: 0.9704
step: 200, loss: 0.6483752727508545, validation precision: 0.9764
step: 300, loss: 0.6680800914764404, validation precision: 0.9786
step: 400, loss: 0.8907914161682129, validation precision: 0.981
step: 500, loss: 0.6301467418670654, validation precision: 0.9816
step: 600, loss: 0.6316057443618774, validation precision: 0.9824
step: 700, loss: 0.7699689269065857, validation precision: 0.9832
step: 800, loss: 0.6809943914413452, validation precision: 0.983
step: 900, loss: 0.6184366941452026, validation precision: 0.9842
step: 1000, loss: 0.7078092098236084, validation precision: 0.9846
step: 1100, loss: 0.6511037945747375, validation precision: 0.9846
step: 1200, loss: 0.6385995149612427, validation precision: 0.9846
step: 1300, loss: 0.7935382723808289, validation precision: 0.9834
step: 1400, loss: 0.7359528541564941, validation precision: 0.9854
step: 1500, loss: 0.8134479522705078, validation precision: 0.9858
step: 1600, loss: 0.6411004066467285, validation precision: 0.9854
step: 1700, loss: 0.6960980892181396, validation precision: 0.9854
step: 1800, loss: 0.6473729610443115, validation precision: 0.9846
step: 1900, loss: 0.7272547483444214, validation precision: 0.986
step: 2000, loss: 0.6058229207992554, validation precision: 0.9854
Process finished with exit code 0resnet_v1_50:
INFO:tensorflow:Restoring parameters from ./model/resnet_v1_50.ckpt
begin to train!
step: 100, loss: 0.6119031310081482, validation precision: 0.946
step: 200, loss: 0.50667405128479, validation precision: 0.9726
step: 300, loss: 0.5590540766716003, validation precision: 0.9784
step: 400, loss: 0.5202317237854004, validation precision: 0.9802
step: 500, loss: 0.4584849178791046, validation precision: 0.9814
step: 600, loss: 0.5502616763114929, validation precision: 0.9828
step: 700, loss: 0.5359719395637512, validation precision: 0.9836
step: 800, loss: 0.40234002470970154, validation precision: 0.9844
step: 900, loss: 0.4581795334815979, validation precision: 0.9862
step: 1000, loss: 0.49176734685897827, validation precision: 0.986
step: 1100, loss: 0.46082034707069397, validation precision: 0.9868
step: 1200, loss: 0.47317391633987427, validation precision: 0.9862
step: 1300, loss: 0.44403091073036194, validation precision: 0.9872
step: 1400, loss: 0.4815652370452881, validation precision: 0.9872
step: 1500, loss: 0.46716445684432983, validation precision: 0.987
step: 1600, loss: 0.4464472532272339, validation precision: 0.987
step: 1700, loss: 0.4649442136287689, validation precision: 0.9872
step: 1800, loss: 0.3995895981788635, validation precision: 0.9872
step: 1900, loss: 0.5506092309951782, validation precision: 0.9872
step: 2000, loss: 0.4343818426132202, validation precision: 0.9876
Process finished with exit code 0inception_v3:
INFO:tensorflow:Restoring parameters from ./model/inception_v3.ckpt
begin to train!
step: 100, loss: 0.4040524959564209, validation precision: 0.9712
step: 200, loss: 0.42345717549324036, validation precision: 0.9678
step: 300, loss: 0.3110312223434448, validation precision: 0.9662
step: 400, loss: 0.2400171458721161, validation precision: 0.973
step: 500, loss: 0.23369356989860535, validation precision: 0.975
step: 600, loss: 0.23103873431682587, validation precision: 0.9754
step: 700, loss: 0.22999879717826843, validation precision: 0.975
step: 800, loss: 0.22969551384449005, validation precision: 0.9742
step: 900, loss: 0.2295011281967163, validation precision: 0.974
step: 1000, loss: 0.22936184704303741, validation precision: 0.974
step: 1100, loss: 0.2292592078447342, validation precision: 0.974
step: 1200, loss: 0.2291814535856247, validation precision: 0.9742
step: 1300, loss: 0.2291458696126938, validation precision: 0.9746
step: 1400, loss: 0.22910399734973907, validation precision: 0.9748
step: 1500, loss: 0.22906532883644104, validation precision: 0.9748
step: 1600, loss: 0.22902897000312805, validation precision: 0.9744
step: 1700, loss: 0.22899401187896729, validation precision: 0.9746
step: 1800, loss: 0.22895951569080353, validation precision: 0.9748
step: 1900, loss: 0.22894582152366638, validation precision: 0.975
step: 2000, loss: 0.2289157211780548, validation precision: 0.975
Process finished with exit code 02、使用estimator训练
定义模型和输入函数:
def model_fn(features, labels, mode, params):
logits = inference(params['model_path'], features, params['class_num'], mode == tf.estimator.ModeKeys.TRAIN)
predictions = {
# Generate predictions (for PREDICT and EVAL mode)
"classes": tf.argmax(input=logits, axis=1),
# Add `softmax_tensor` to the graph. It is used for PREDICT and by the `logging_hook`.
"probabilities": tf.nn.softmax(logits, name="softmax_tensor")
}
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
accuracy = tf.metrics.accuracy(labels=labels, predictions=predictions["classes"])
tf.summary.scalar('accuracy', accuracy[1])
if mode == tf.estimator.ModeKeys.TRAIN:
variables_to_train, variables_to_restore = variables_to_restore_and_train(params['model_path'])
tf.train.init_from_checkpoint(params['model_path'], {v.name.split(':')[0]: v for v in variables_to_restore})
global_step = tf.train.get_or_create_global_step()
train_op = get_train_op(loss, variables_to_train, variables_to_restore,
params['batch_size'], params['lr'], global_step)
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)
# Add evaluation metrics (for EVAL mode)
eval_metric_ops = {"eval_accuracy": accuracy}
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, eval_metric_ops=eval_metric_ops)
def input_fn(filenames, batch_size, pre_trained_model, image_size, is_training):
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(lambda example:
parse_and_preprocess_data(example, pre_trained_model, image_size, is_training))
dataset = dataset.batch(batch_size)
if is_training:
dataset = dataset.repeat()
iterator = dataset.make_one_shot_iterator()
features, labels = iterator.get_next()
return features, labels进行训练:
def train(model_path, image_size):
my_checkpoint_config = tf.estimator.RunConfig(save_checkpoints_steps=100, keep_checkpoint_max=5)
mnist_classifier = tf.estimator.Estimator(model_fn=model_input.model_fn,
model_dir=FLAGS.log_dir,
config=my_checkpoint_config,
params={'class_num': 2,
'model_path': model_path,
'lr': FLAGS.learning_rate,
'batch_size': FLAGS.batch_size})
# tensor_to_log = {'probabilities': 'softmax_tensor'}
# logging_hook = tf.train.LoggingTensorHook(tensors=tensor_to_log, every_n_iter=100)
mnist_classifier.train(
input_fn=lambda: model_input.input_fn(['./data/train_img.tfrecord'],
FLAGS.batch_size, model_path, image_size, True),
steps=FLAGS.max_step)
# eval_results = mnist_classifier.evaluate(
# input_fn=lambda: model_input.input_fn(['.data/validation_img.tfrecord'],
# FLAGS.batch_size, model_path, image_size, False))
# print('validation acc: {}'.format(eval_results))训练的代码其实就三行。最后注释掉的几行,是estimator的验证代码。本想像之前文章TensorFlow学习实践(三):使用TFRecord格式数据和tf.estimator API进行模型训练和预测 中那样,每训练一定步数验证一次,结果出错:Process finished with exit code -1073741819 (0xC0000005)。。网上搜了一下,错误原因五花八门,暂时不清楚,同样的环境,同样的代码逻辑。
模型验证:
def validation(model_path, image_size):
images, labels = model_input.input_fn(['./data/validation_img.tfrecord'],
FLAGS.batch_size, model_path, image_size, False)
logits = model_input.inference(model_path, images, 2, False)
prediction = tf.argmax(tf.nn.softmax(logits), axis=1)
# Choose the metrics to compute:
value_op, update_op = tf.metrics.accuracy(labels, prediction)
num_batchs = math.ceil(model_input.VALIDATION_EXAMPLES_NUM / FLAGS.batch_size)
print('Running evaluation...')
# Only load latest checkpoint
checkpoint_path = tf.train.latest_checkpoint(FLAGS.log_dir)
metric_values = slim.evaluation.evaluate_once(
num_evals=num_batchs,
master='',
checkpoint_path=checkpoint_path,
logdir=FLAGS.log_dir,
eval_op=update_op,
final_op=value_op)
print('model: {}, acc: {}'.format(checkpoint_path, metric_values))训练结果:
vgg_16:
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Saving checkpoints for 0 into ./log\model.ckpt.
INFO:tensorflow:loss = 2.2186143, step = 0
INFO:tensorflow:Saving checkpoints for 100 into ./log\model.ckpt.
INFO:tensorflow:global_step/sec: 1.42496
INFO:tensorflow:loss = 0.18707708, step = 100 (70.176 sec)
INFO:tensorflow:Saving checkpoints for 200 into ./log\model.ckpt.
INFO:tensorflow:global_step/sec: 1.43128
INFO:tensorflow:loss = 0.1977885, step = 200 (69.868 sec)
INFO:tensorflow:Saving checkpoints for 300 into ./log\model.ckpt.
INFO:tensorflow:Loss for final step: 0.3762597.
Process finished with exit code 0Running evaluation...
model: ./log\model.ckpt-300, acc: 0.9315999746322632
Process finished with exit code 0resnet_v1_50:
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Saving checkpoints for 0 into ./log\model.ckpt.
INFO:tensorflow:loss = 0.9740275, step = 0
INFO:tensorflow:Saving checkpoints for 100 into ./log\model.ckpt.
INFO:tensorflow:global_step/sec: 3.04915
INFO:tensorflow:loss = 0.6660491, step = 100 (32.796 sec)
INFO:tensorflow:Saving checkpoints for 200 into ./log\model.ckpt.
INFO:tensorflow:global_step/sec: 3.09199
INFO:tensorflow:loss = 0.7206874, step = 200 (32.342 sec)
INFO:tensorflow:Saving checkpoints for 300 into ./log\model.ckpt.
INFO:tensorflow:global_step/sec: 3.03805
INFO:tensorflow:loss = 0.8522668, step = 300 (32.916 sec)
INFO:tensorflow:Saving checkpoints for 400 into ./log\model.ckpt.inception_v3:
INFO:tensorflow:loss = 0.027508494, step = 1500 (35.271 sec)
INFO:tensorflow:Saving checkpoints for 1600 into ./log\model.ckpt.
INFO:tensorflow:global_step/sec: 2.8491
INFO:tensorflow:loss = 0.37406808, step = 1600 (35.100 sec)
INFO:tensorflow:Saving checkpoints for 1700 into ./log\model.ckpt.
INFO:tensorflow:global_step/sec: 2.83445
INFO:tensorflow:loss = 0.014903389, step = 1700 (35.280 sec)
INFO:tensorflow:Saving checkpoints for 1800 into ./log\model.ckpt.
INFO:tensorflow:global_step/sec: 2.82986
INFO:tensorflow:loss = 0.0763669, step = 1800 (35.336 sec)
INFO:tensorflow:Saving checkpoints for 1900 into ./log\model.ckpt.
INFO:tensorflow:global_step/sec: 2.82245
INFO:tensorflow:loss = 0.0583717, step = 1900 (35.431 sec)
INFO:tensorflow:Saving checkpoints for 2000 into ./log\model.ckpt.
INFO:tensorflow:Loss for final step: 0.027828213.
load model: inception_v3
Running evaluation...
INFO:tensorflow:Starting evaluation at 2018-09-11-06:04:11
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from ./log\model.ckpt-2000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
model: ./log\model.ckpt-2000, acc: 0.9764000177383423
INFO:tensorflow:Finished evaluation at 2018-09-11-06:04:41
Process finished with exit code 0在参数一样的情况下,vgg_16训练100步耗时70s左右,resnet_v1_50训练100步耗时32s,inception_v3耗时35s左右。
3、使用slim进行训练
def train_slim(model_path, image_size):
images, labels = model_input.input_fn(['./data/train_img.tfrecord'], FLAGS.batch_size, model_path, image_size, True)
logits = model_input.inference(model_path, images, 2, True)
loss = model_input.loss(logits, labels)
optimizer = tf.train.AdamOptimizer(learning_rate=FLAGS.learning_rate)
train_op = slim.learning.create_train_op(loss, optimizer, summarize_gradients=True)
variables_to_train, variables_to_restore = model_input.variables_to_restore_and_train(model_path)
init_fn = slim.assign_from_checkpoint_fn(model_path, variables_to_restore, ignore_missing_vars=True)
slim.learning.train(train_op=train_op, logdir=FLAGS.log_dir,
log_every_n_steps=100, number_of_steps=FLAGS.max_step,
init_fn=init_fn, save_summaries_secs=120,
save_interval_secs=600)实际训练过程中,slim训练很慢,比用estimator慢几倍,但是看代码实现,并没有看出太大差别,一个用Supervisor,一个用MonitoredTrainingSession。
小结:
从三种模型训练结果来看,训练相同步数,结果差不多,vgg_16和resnet_v1_50比inception_v3稍微高些。
六、模型预测
def pred(test_data, log_dir, model_path, image_size):
images = tf.placeholder(tf.float32, shape=[None, image_size, image_size, 3])
logits = model_input.inference(model_path, images, 2, False)
predict = tf.nn.softmax(logits)
saver = tf.train.Saver()
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(log_dir)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
else:
print('no checkpoint file')
return
count = 0
for f in os.listdir(test_data):
if count >= 10:
break
file = os.path.join(test_data, f)
img = cv2.imread(file)
image = tf.cast(img, tf.float32)
image = model_input.preprocess(image, model_path, image_size, False)
imgs = tf.expand_dims(image, axis=0)
imgs = imgs.eval()
pre = sess.run(predict, feed_dict={images: imgs})
if np.argmax(pre[0]) == 0:
label = 'cat'
else:
label = 'dog'
print('model:{}, file:{}, label: {}-{} ({:.2f}%)'.
format(ckpt.model_checkpoint_path, file, np.argmax(pre[0]), label, np.max(pre[0]) * 100))
text = '{} {}({:.2f}%)'.format(f, label, np.max(pre[0]) * 100)
cv2.putText(img, text, (0, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow('image', img)
cv2.waitKey()
count += 1结果:





最后:完整代码
https://github.com/buptlj/tf_finetune