每天一篇论文 369/1000 D3VO: Deep Depth, Deep Pose and Deep Uncertainty for Monocular Visual Odometry
D3VO: Deep Depth, Deep Pose and Deep Uncertainty for Monocular Visual Odometry
论文阅读汇总list
摘要
我们提出D3VO作为一种新的单目视觉测程框架,它利用了深度、姿态和不确定度三个层次上的深度网络。首先,我们提出了一种基于双目视频的自监督单目深度估计网络。特别地,它利用预测亮度变换参数将训练图像对对齐到相似的光照条件。此外,我们对输入图像上像素的光度不确定性进行了建模,提高了深度估计的精度,并为直(无特征)视觉测程法中的光度残值提供了一个学习加权函数。评价结果表明,该网络的性能优于现有的自监督深度估计网络。D3VO将预测的深度、姿态和不确定性紧密地结合到一个直接的视觉测程方法中,以促进前端跟踪和后端非线性优化。我们在KITTI测程基准和EuRoC MAV数据集上用单目视觉测程来评估D3VO。结果表明,D3VO法明显优于传统单目VO法。它还实现了与最先进的立体声/激光雷达测程的KITTI和最先进的视觉惯性测程的EuRoC MAV,而只使用一个摄像头。
方法
我们首先介绍了一种新的自监督神经网络,它可以预测深度、姿态和不确定性。该网络还估计仿射亮度变换参数,以自监督的方式对齐训练图像的照明。光度不确定度是根据每个像素可能的亮度值的分布来预测的。然后,我们介绍了D3VO作为一个直接的视觉测程框架,将预测的性能纳入到跟踪前端和光度束调整后端。
1.自监督深度估计
自我监督训练是通过最小化时间和静态立体图像之间的光度重投影误差来实现的:
L s l e f = 1 ∣ V ∣ ∑ p ∈ v min t ′ r ( I t , I t ′ → t ) L_{slef}= \frac 1{|V|}\sum_{p\in v}\min_{t'}r(I_t,I_{t'\to t}) Lslef=∣V∣1p∈v∑t′minr(It,It′→t)
其中 V V V 是图像 I t I_t It上所有像素集合, t ′ t' t′是所有原图的索引。
传统的深度估计几何偏差为:
r ( I a , I b ) = α 2 ( 1 − S S I M ( I a , I b ) ) + ( 1 − α ) ∣ ∣ I a − I b ∣ ∣ r(I_a,I_b)=\frac \alpha2(1-SSIM(I_a,I_b))+(1-\alpha)||I_a-I_b|| r(Ia,Ib)=2α(1−SSIM(Ia,Ib))+(1−α)∣∣Ia−Ib∣∣
以上公式是基于光度恒定假设。然而,**由于相机的光照变化和自动曝光影响,L1和SSIM都不是固定不变的,因此可能会违反以上假设。**因此,我们建议使用预测亮度转换参数来明确地建模相机曝光变化。这也是本文的出发的核心
2.亮度转移参数

图1 在EuRoC MAV上相似亮度变换的实例。原始的源图像 I t ′ I_{t'} It′和目标图像 I t I_{t} It显示不同的亮度。在预测参数a、b的情况下,变换后的目标图像 I t a r ′ b r ′ I_{t}^{a_{r'}b_{r'}} Itar′br′与源图像具有相似的亮度,有利于基于亮度恒常性假设的自监督训练。
相机曝光调整引起的图像强度变化可以用a、b两个参数的映射变换来表示:
I a , b = a I + b I^{a,b} = aI + b Ia,b=aI+b
尽管它很简单,这个公式已经被证明在直接VO/SLAM中是有效。受一些恒定光度工作的启发,通过预测变换参数a, b,使预测图像 I t ′ I_{t'} It′与 I t I_t It 的亮度条件一致。公式(1)重新表述为:
L s l e f = 1 ∣ V ∣ ∑ p ∈ V min t ′ r ( I t a t ′ , b t ′ , I t ′ → t ) L_{slef}= \frac 1{|V|}\sum_{p\in V}\min_{t'}r(I_t^{a_{t'},b_{t'}},I_{t'\to t}) Lslef=∣V∣1p∈V∑t′minr(Itat′,bt′,It′→t)
其中:
I t a t ′ , b t ′ = a t → t ′ I t + b t → t ′ I_t^{a_{t'},b_{t'}} = a_{t\to{t'}}I_t+b_{t\to{t'}} Itat′,bt′=at→t′It+bt→t′
其中 a t → t ′ a_{t\to t'} at→t′和 b t → t ′ b_{t\to t'} bt→t′是根据 I t I_t It到 I t ′ I_{t'} It′的光度变化调整。这两个参数都能以自监督方式训练。
3.几何偏差不确定
只依赖亮度变化不足以所有亮度恒定假设的失效情况。其他情况,如非朗伯曲面和运动物体,是由相应物体的固有性质引起的,这些性质对于分析建模来说并不是微不足道的。由于这些方面可以看作是观测噪声,利用Kendall等人提出的深度神经网络的异方差任意不确定性概念。预测每个像素在真实标签y的后验概率分布参数化的均值和方差的 p ( y ∣ y ′ , σ ) p(y|y',\sigma) p(y∣y′,σ)。例如,通过假设噪声拉普拉斯算子,负对数似是最小化:
− l o g p ( y ∣ y ′ , σ ) = ∣ y − y ′ ∣ σ + l o g σ + c o n s t -logp(y|y',\sigma) = \frac{|y-y'|}\sigma+log\sigma+const −logp(y∣y′,σ)=σ∣y−y′∣+logσ+const
不需要真实标签对 σ \sigma σ进行训练。预测不确定性允许网络根据数据输入调整残差的权重,从而提高了模型对噪声数据或错误标签的鲁棒性。
加入不确定项的估计 ∑ t \sum_t ∑t对提出的亮度变化不恒定的区域进行亮度变化参数预测同时加入不确定项预测值,使得几何偏差估计更加鲁棒性。
L s l e f = 1 ∣ V ∣ ∑ p ∈ V min t ′ r ( I t a t ′ , b t ′ , I t ′ → t ) ∑ t + l o g ∑ t L_{slef}= \frac 1{|V|}\sum_{p\in V}\frac{\min_{t'}r(I_t^{a_{t'},b_{t'}},I_{t'\to t})}{\sum_t} +log{\sum}_t Lslef=∣V∣1p∈V∑∑tmint′r(Itat′,bt′,It′→t)+log∑t

总的损失函数多尺度图像上的自监督损失和正则化损失之和
L t o t a l = 1 s ∑ s ( L s e l f s + λ L r e g s ) L_{total}=\frac 1s\sum_s(L_{self}^s+\lambda L_{reg}^s) Ltotal=s1s∑(Lselfs+λLregs)
其中 s = 4 s=4 s=4是尺度数:
L r e g = L s m o o t h + β L a b L_{reg}=L_{smooth} +\beta L_{ab} Lreg=Lsmooth+βLab
其中:
L a b = ∑ t ′ ( a t ′ − 1 ) 2 + b t ′ 2 L_{ab}=\sum_{t'}(a_{t'}-1)^2+b_{t'}^2 Lab=t′∑(at′−1)2+bt′2
亮度参数的正则化和 L s m o o t h L_{smooth} Lsmooth是 D t D_t Dt上的边缘感知平滑度.
D3VO
D3VO通过Photometric energy 和 Pose energy两个方向对深度估计中投影偏差进行改进。
1.Photometric energy
D3VO的目标是小减小深度估计和位姿估计后投影的偏差photometric error E p h o t o E_{photo} Ephoto:
E p h o t o = ∑ i ∈ F ∑ p ∈ P i ∑ j ∈ o b s ( p ) E_{photo}=\sum_{i\in \mathcal F}\sum_{\mathbf p\in \mathcal P_i}\sum_{j\in obs(\mathbf p)} Ephoto=i∈F∑p∈Pi∑j∈obs(p)∑
F \mathcal F F是所有关键帧集合, P i \mathcal P_i Pi是关键帧 i i i里的可见点, o b s ( p ) obs(\mathbf p) obs(p)是 p \mathbf p p点在关键帧里可见并且当 p \mathbf p p点在投影到关键帧 j \mathbf j jphotometric energy项:
E p j : = ∑ p ∈ N p w p ∣ ∣ ( I j [ p ′ ] − b j ) − e a j e a i ( I i [ p ] − b i ) ∣ ∣ γ E_{\mathbf pj}:=\sum_{\mathbf p\in {\mathcal N}_p}w_{\mathbf p}||(I_j[\mathbf p']-b_j)-\frac {e^{a_j}}{e^{a_i}}(I_i[\mathbf p]-b_i)||_\gamma Epj:=p∈Np∑wp∣∣(Ij[p′]−bj)−eaieaj(Ii[p]−bi)∣∣γ
其中 N \mathcal N N是 p \mathbf p p点周围8个像素集, a , b a,b a,b是Direct sparse odometry中的非线性优化估计得相似亮度参数, ∣ ∣ . ∣ ∣ γ ||.||_\gamma ∣∣.∣∣γ是Huber范数。在DSO中当具有较高的图像梯度时,对小的独立几何噪声进行补偿残差加权。我们提出用学习的方法预测不确定性参数 ∑ ∼ \sum\limits^\sim ∑∼:
w p = α 2 α 2 + ∣ ∣ ∑ ∼ ( p ) ∣ ∣ 2 2 w_p=\frac{\alpha^2}{\alpha^2+||\sum\limits^\sim(\mathbf p)||_2^2} wp=α2+∣∣∑∼(p)∣∣22α2
这不仅依赖于局部图像的梯度,而且依赖于更高级别的的噪声模式。
投影点 p ’ \mathbf p’ p’由 p ’ = ∏ ( T i j ∏ − 1 ( p , d p ) ) \mathbf p’=\prod(T_i^j\prod^{-1}(\mathbf p,\mathcal d_p)) p’=∏(Tij∏−1(p,dp))计算得出其中 d p \mathcal d_\mathbf p dp是关键帧 i i i坐标 p \mathbf p p的深度值,$\prod (.) 是 相 机 内 参 已 知 的 重 投 影 方 程 。 相 比 传 统 的 直 接 匹 配 方 法 随 机 初 始 化 深 度 是相机内参已知的重投影方程。相比传统的直接匹配方法随机初始化深度 是相机内参已知的重投影方程。相比传统的直接匹配方法随机初始化深度\mathcal d_\mathbf p 我 们 提 出 初 始 化 我们提出初始化 我们提出初始化\mathcal d_\mathbf p = \tilde D_i[\mathbf p] 提 供 矩 阵 尺 度 。 本 文 在 提供矩阵尺度。本文在 提供矩阵尺度。本文在E_{\mathbf pi} 的 基 础 上 加 入 双 目 视 觉 项 的基础上加入双目视觉项 的基础上加入双目视觉项E_{\mathbf p}^+$:
E p h o t o = ∑ i ∈ F ∑ p ∈ P i ( λ E p + + ∑ j ∈ o b s ( p ) E p j ) E_{photo} = \sum_{i\in \mathcal F}\sum_{\mathbf p\in \mathcal P_i}(\lambda E_{\mathbf p}^+ +\sum_{j\in obs(\mathbf p)}E_{\mathbf pj}) Ephoto=i∈F∑p∈Pi∑(λEp++j∈obs(p)∑Epj)
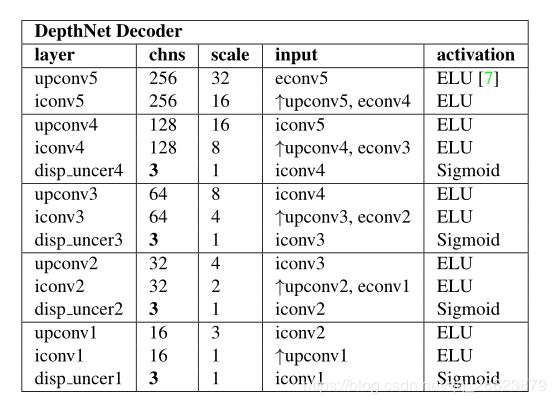
图3 深度网解码器的网络结构。所有层均为核尺寸为3、步长为1的卷积层,↑为2×2最近邻上采样。这里chns是输出通道的数量,scale是相对于输入图像的降阶因子。注意,disp_unc层有三路输出包含Dt, D t s D_t^s Dts和 ∑ t \sum_t ∑t.
2.Pose energy
与传统的直接VO方法[19,23]不同的是,该方法使用恒定速度运动模型对每个新帧初始化前端跟踪,我们利用连续帧之间的预测位姿构建非线性因子图[41,47]。具体来说,当最新的关键帧(也就是前端跟踪的参考帧)更新时,我们创建一个新的因子图。此外,从深度网络预测的相对位姿被用作当前帧和最后一帧之间的一个因子。优化完成后,我们将最后一帧边缘化,并使用因子图对后续帧进行前端跟踪。从跟踪前端估计的姿态然后用于初始化光度Bundle adjustment后端。我们在pose预测得到的位姿 T ~ i − 1 i \tilde T_{i-1}^i T~i−1i基础上得到先验位姿 T i − 1 i T_{i-1}^i Ti−1i。
E p o s e = ∑ i ∈ F − { 0 } L o g ( T ~ i − 1 i T i i − 1 ) T ∑ ξ ~ i − 1 i − 1 L o g ( T ~ i − 1 i T i i − 1 ) E_{pose}=\sum_{i\in \mathcal F-\{0\}}Log(\tilde T_{i-1}^iT_{i}^{i-1})^T\sum_{\tilde\xi_{i-1}^i}^{-1}Log(\tilde T_{i-1}^iT_{i}^{i-1}) Epose=i∈F−{0}∑Log(T~i−1iTii−1)Tξ~i−1i∑−1Log(T~i−1iTii−1)
L o g : S E ( 3 ) → R 6 Log:SE(3)\to \mathbb R^6 Log:SE(3)→R6为李代数转换矩阵, ∑ ξ ~ i − 1 i − 1 \sum_{\tilde\xi_{i-1}^i}^{-1} ∑ξ~i−1i−1通过在每个连续的帧对之间传播协方差矩阵得到,该协方差矩阵被建模为一个常数对角矩阵。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5pKajDdA-1588265995260)(C:\Users\www\AppData\Roaming\Typora\typora-user-images\image-20200429234500122.png)]
图3 深度网解码器的网络结构。所有层均为核尺寸为3、步长为1的卷积层,↑为2×2最近邻上采样。这里chns是输出通道的数量,scale是相对于输入图像的降阶因子。注意,disp_unc层有三路输出包含Dt, D t s D_t^s Dts和 ∑ t \sum_t ∑t.
3.Total energy function:
E t o t a l = E p h o t o + w E p o s e E_{total} = E_{photo}+wE_{pose} Etotal=Ephoto+wEpose
如上通过在跟踪前端和优化后端引入预测姿态作为初始化,并将其作为正则化添加到光度BA的能量函数中,从而改进了直接VO方法。
PoseNet网络结构如下表

图5 PoseNet的网络结构。除了全局平均池层(avg池),所有层都是卷积层,k为内核大小,s为步长,chns为通道,并根据输入图像缩放比例因子。
实验
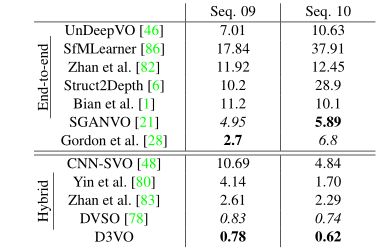
1.深度估计进度对比
结果表明,所提出的深度估计网络在所有指标上都优于Monodepth2。研究表明,相对于Monodepth2的显著改进主要来自uncer,这可能是因为在KITTI中有许多non-Lambertian的物体,如窗户,也有独立运动的物体,如汽车和树叶,它们违反了亮度恒定假设。下表显示了与目前最先进的半监督方法的比较,结果表明我们的方法可以在不使用任何深度监督的情况下获得有竞争力的性能。
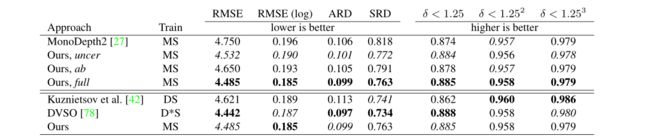
图6 在KITTI的深度评价结果。M:单目自监督;S:自监督立体监督;D:地面真深度监督;D:稀疏辅助深度监督。上半部分是与SOTA自监督网络单深度2[26]在相同设置下的对比,以及亮度变换参数(ab)和光度不确定度(uncer)的研究。下半部分是与基于深度监督和立体监督的SOTA半监督方法的比较。我们的方法在所有指标上都优于Monodepth2,也可以提供与SOTA半监督方法DVSO[78]相当的性能,该方法还额外使用了立体声DSO[74]的深度作为稀疏监督信号。*
2.亮度参数实验
首先利用原始图像对计算光度误差,然后利用PoseNet的预测参数对左侧图像进行转换计算绝对光度误差。我们还实现了一个简单的基线方法来估计仿射亮度参数通过求解线性最小二乘(LS)。我们用OpenCV[4]中实现的稠密光流方法[20]建立了正态方程。如表9所示,在进行仿射亮度变换时,平均光度误差大大降低,PoseNet的预测参数优于LS的估计参数。我们在图9中展示了更多的近似亮度变换的例子。
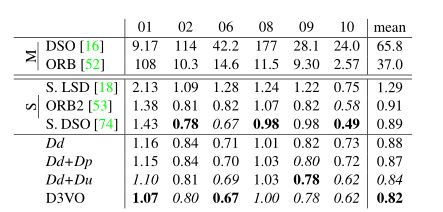
3.里程计VO结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SvGgJvoc-1588236464119)(https://i.loli.net/2020/04/30/XJ85LuyaCrV9pFo.png)]


4.训练之后的model在Cityscapes