在我们身边,到处都有人脸识别的技术,像我们平时使用的iPhone手机,照片里面有一个“人物”的功能,它能够将照片里面的人物识别出来,然后进行分类,iPhoneX还可以扫脸解锁手机。再比如,家里面的智能电视,当你看到某个片段某个人时,电视就可以告诉你这个人是谁,演过些什么电影。这些背后都离不开人脸识别的技术。
这篇文章将详细介绍,怎样安装和使用Python语言,利用百度大脑提供的AI接口,从0开始,一步一步来做一个人脸识别的功能,通过人脸识别分析人物的年龄、性别和颜值,以及在人脸上描出72个特征点,最后我们将在浏览器查看效果。
先来看一下最终实现的效果:

准备
电脑与windows系统
第一步 安装开发环境
我们选择用Python语言,Python目前是机器学习中比较流行的语言,入门简单,功能强大。安装Python的方式有很多种,我们选择用anaconda的方式,anaconda相当于一个工具包,将Python和一些常用的包打包一起,下载好就可以直接使用,非常方便,而且是免费的。
1.1 下载anaconda
直接登录anaconda官网下载 https://www.anaconda.com/download/

下载完,双击安装文件,开始安装anaconda
点击“Next”

点击“I Agree”

点击“Next”

选择安装位置(可以默认不变),点击“Next”

点击“Install”开始安装
点击“Finsh”,安装完成。
1.2 安装 spyder
打开anaconda

进入anaconda首页
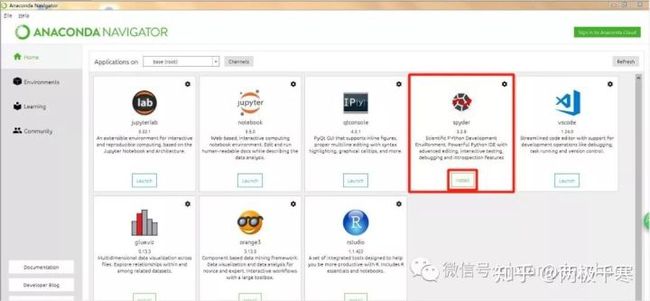
在anaconda首页,上图红框spyder这里点击“install”,spyder是Python的一个简单的集成开发环境。如果是已安装的话,“install”的按钮会显示“Launch”,点击就可以启动spyder,我们可以在spyder里面编写代码。
1.3 检查Python环境是否正常
打开anaconda,点击左侧“Environments”,然后点击“base(root)”右边的小三角,在弹出的内容里面,选择“Open with Python”

弹出系统命令窗口,如显示下面内容,则表示Python安装成功。

第二步 注册获取百度AI接口
要实现人脸识别有很多方式,可以自己写算法,也可以利用一些AI平台提供的开放接口,我们选择用百度大脑提供的人脸识别接口来实现。
2.1 登录百度AI开放平台
打开 http://ai.baidu.com/

点击页面右上角“控制台”,选择“人脸识别”
PS:需要先登录百度账号,如果没有百度账号需要注册一个。
2.2 创建应用
进入“人脸识别”后,点击“创建应用”按钮

进入创建应用页面

填写好点击下面的“立即创建”,提示创建成功。
点击“查看应用详情”
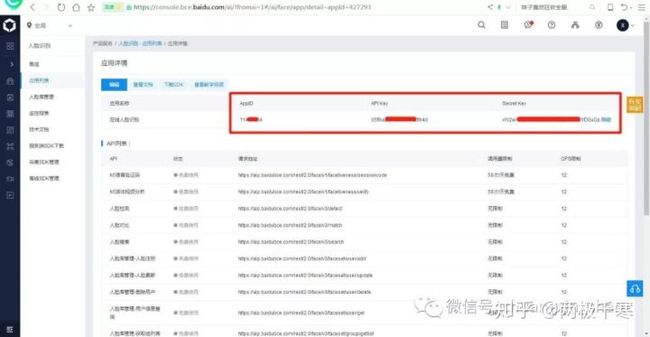
如上截图,红框里面的 AppID、API Key 和 Secret Key 这三个内容很重要,等下调用接口时候,需要它们做签名验证。
第三步 安装web应用框架
在开始编写代码之前,为了让我们编写的代码,可以通过网页的形式展示出来,方便我们浏览效果,我们还需要做多一步。我们需要搭建一个简单的Web应用,对于Python来说,有很多Web框架可以让我们快速搭建Web应用,这里我们选择Django框架。
3.1 安装Django框架
打开anaconda,点击左侧“Environments”,然后点击“base(root)”右边的小三角,在弹出的内容里面,选择“Open Terminal”

弹出命令窗口

在弹出的这个命令窗口,我们使用pip来安装django框架
PS:pip是一个安装和管理 Python 包的工具,在我们使用python开发项目的过程,很多时候需要下载一些包,都可以通过pip来安装,非常简单,也很方便。我们安装anaconda后,默认都会安装pip的工具,所以我们直接使用就可以。
在上面的命令窗口输入以下命令:
pip install django
然后按回车开始安装

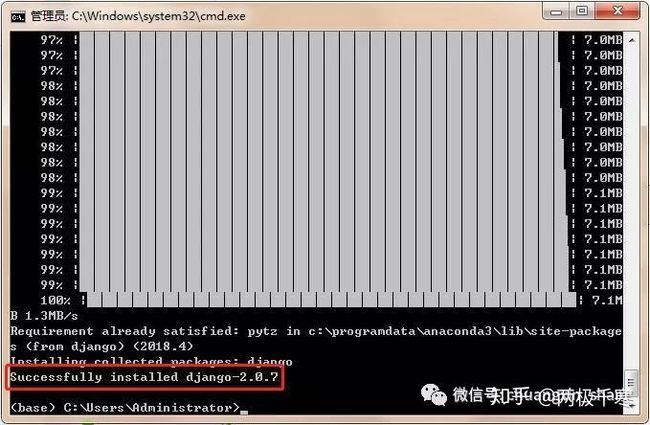
按回车后,大概需要几分钟时间,就会自动安装好,中间不需要任何操作,直到出现上面这个提示,就代表已经安装成功!
第四步 编写代码
好了,该准备的工作我们都准备好了,接下来就可以创建项目,然后正式编写代码。这一步其实没大家想的复杂,只需要几十行代码就可以实现我们要的效果,当然,如果要完全熟悉代码,甚至了解背后更深的逻辑,需要付出更多时间去学习。
4.1 创建项目
我们先创建一个web项目,通过anaconda打开命令窗口(参考上一步)

然后切换路径,切换到我们想创建项目的位置,注意,我这里是放在电脑的F盘里面的test文件夹,所以先在上面的命令窗口中,输入f: 按回车切换到F盘

再输入 cd test 按回车进入test文件夹
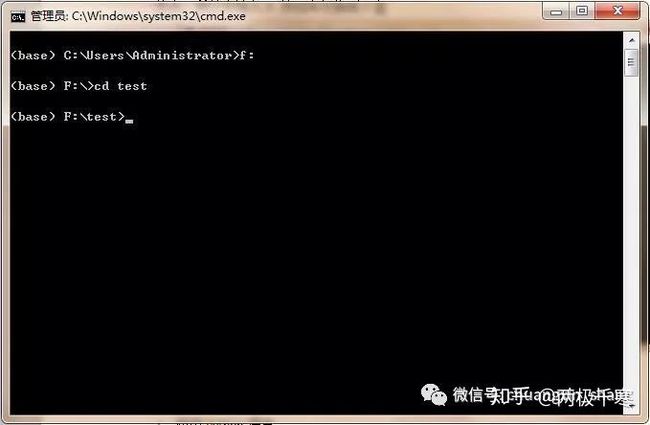
如上截图,我们现在已经进入F盘的test文件夹目录下了,在这里我们创建一个名称为 Face_Recognition 的项目,直接输入以下命令创建项目,然后按回车:
django-admin.py startproject Face_Recognition

创建后我们打开电脑对应的目录,如果看到 Face_Recognition 的文件夹,就说明创建成功了
PS:如果没看到 Face_Recognition 的文件夹,说明创建失败,可以将创建命令改成:
django-admin startproject Face_Recognition
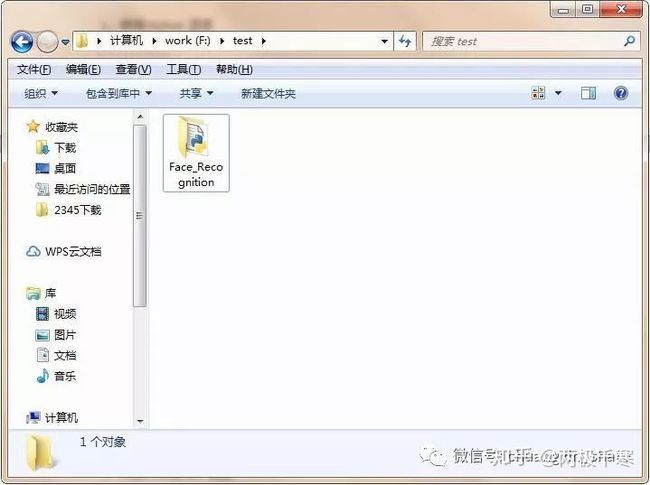
双击打开Face_Recognition这个文件夹,里面有一个文件夹和一个py的文件

然后我们启动服务器,启动后,我们就可以通过浏览器来访问这个项目。
回到刚才的命令窗口,先进入到Face_Recognition的目录里面,然后输入以下命令,按回车:
python manage.py runserver 0.0.0.0:8000

这样我们就启动服务器了,接下来我们打开浏览器,在浏览器地址栏输入:
127.0.0.1:8000
如果正常启动,浏览器会显示下面的页面
PS:服务器启动后,这个命令窗口不要关掉哦,让它运行着就可以,如果关掉的话,浏览器将无法访问页面。后面需要使用命令窗口,可以重新打开一个。
4.2 创建页面
项目创建成功后,接下来,我们就可以打开spyder,新建页面,然后开始编写代码了。
我们需要新建两个页面,分别是:
recognition.py 用来处理人脸识别
view.html 模板文件,用来处理页面展示
我们先了解下这两个页面的逻辑:
1)首先,我们在 view.html 里面选择图片,提交给 recognition.py 处理;
2)recognition.py 接收到图片后,进行人脸识别,然后将分析结果返回给 view.html;
3)view.html 将 recognition.py 返回的分析结果展示出来。
PS:新建这两个页面的时候,需要注意文件所放的目录。
recognition.py 是放在 F:\test\Face_Recognition\Face_Recognition,即跟urls.py 在同个目录。
view.html 是放在 templates 文件夹里面,我们需要在 F:\test\Face_Recognition 创建 templates 文件夹,即跟 manage.py 在同个目录。
好了,我们开始动手做吧
首先打开 spyder

点击上图左上角的按钮,新建页面
新建后,我们先点击左上角红框位置的保存按钮,把它保存为 recognition.py,然后再新建和保存 view.html

4.3 编写代码
按照两个页面逻辑顺序,我们先编写view.html页面,让它可以选择图片传给recognition.py,打开刚才新建的view.html,并输入下面代码:
人脸识别demo
{{ pic }}
上面这段代码通过表单提交图片,然后传给 /recognition路径去处理
为了让django框架知道这个模板文件的路径,我们需要修改 F:\test\Face_Recognition\Face_Recognition\settings.py 文件,修改 TEMPLATES 中的 DIRS 为 [BASE_DIR+"/templates",],如下所示:

接下来,我们打开 recognition.py 文件,输入以下代码:
from django.shortcuts import render
def recognition_post(request):
context ={}
if request.POST:
context['pic'] = request.FILES['pic']
return render(request, "view.html", context)
这段代码创建 recognition_post 函数,用来接收表单提交的照片,提交数据给 view.html
为了让 view.html 这个页面和 recognition_post 函数能够完成这样的操作,我们需要配置URL,打开 F:\test\Face_Recognition\Face_Recognition\urls.py,删除原来代码,将以下代码复制粘贴到 urls.py 文件中:
from django.conf.urls import url
from . import recognition
urlpatterns = [
url(r'^recognition$', recognition.recognition_post),
]
OK,我们可以在浏览器输入 http://127.0.0.1:8000/recognition,浏览下效果

PS:为了解决在django里面图片路径显示的问题,我们需要创建一个和templates同级的文件夹static,在static下创建images文件夹,然后将用来测试的图片存在images里面。
然后,打开 settings.py 文件文件,在末尾添加如下代码:
STATIC_URL = '/static/'
STATICFILES_DIRS = ( os.path.join(BASE_DIR, 'static').replace('\\', '/'), )
接下来,我们在 recogniton.py 使用百度人脸识别的接口,来识别提交的图片,在调用接口前,我们需要先安装一下Python SDK,在anaconda中打开命令窗口(参考前面第三步),在命令窗口输入:
pip install baidu-aip

出现红框的 Successfully installed baidu-aip-2.2.5.2 提示安装成功。
我们重新编辑 recognition.py,完整代码如下:
# -*- coding: utf-8 -*-
from django.shortcuts import render
from aip import AipFace
import base64
import json
# 需要安装PIL,它是一个图像处理库。安装语句:pip install pillow 安装方法参考上面安装django
import PIL
from PIL import Image
from PIL import ImageDraw
## 百度接口信息
APP_ID = '1******7'
API_KEY = 'y7VFQ**********0wRiplh'
SECRET_KEY = '2zLjGOD***********roqFg6ViHrpa'
client = AipFace(APP_ID, API_KEY, SECRET_KEY)
imageType = "BASE64"
# 定义参数变量
options = {}
options["max_face_num"] = 1
options["face_field"] = "age,beauty,gender,landmark"
## 百度接口信息
def recognition_post(request):
content ={}
if request.POST:
with open("./static/images/"+str(request.FILES['Photo']),"rb") as f:
base64_data = base64.b64encode(f.read())
image = str(base64_data, encoding='utf-8');
result = client.detect(image, imageType, options)
content['Photo'] = "/static/images/"+str(request.FILES['Photo'])
# 将百度接口返回的数据转成json对象
json_str = json.dumps(result)
# 对数据进行解码
json_data = json.loads(json_str)
content['age'] = json_data['result']['face_list'][0]['age']
content['beauty'] = json_data['result']['face_list'][0]['beauty']
gender = json_data['result']['face_list'][0]['gender']['type']
if gender == 'female':
content['gender'] = "女性"
else:
content['gender'] = "男性"
landmark72 = json_data['result']['face_list'][0]['landmark72']
im1=Image.open("./static/images/"+str(request.FILES['Photo']))
draw = ImageDraw.Draw(im1)
for index in range(72):
xy = landmark72[index]
draw.text((xy['x'], xy['y']),"o",(255,255,0))
draw = ImageDraw.Draw(im1)
im1.save("static/images/target_img.jpg")
content['target_img'] = "/static/images/target_img.jpg"
return render(request, "view.html", content)
以上代码,主要是通过接口来识别照片里面的人物,分析人物的年龄和性别,给人物的颜值打分,以及标记人脸的72个特征点,然后通过最后一句代码将这些内容传给 view.html
PS:代码中APP_ID、API_KEY和SECRET_KEY就是我们在第二步创建百度AI应用时获取的,请填写自己获取的对应内容。
然后我们再打开 view.html,将 recognition.py 识别后传过来的分析结果呈现出来,完整代码如下:
人脸识别
{% if Photo %}
 {% if target_img %}{% endif %}
{% if target_img %}{% endif %}
年龄:{{ age }}岁
颜值:{{ beauty }}分
性别:{{ gender }}{{ face_type }}
{% endif %}
好了,以上就是所有的代码了,接下来,我们打开浏览器,看一下整个效果吧
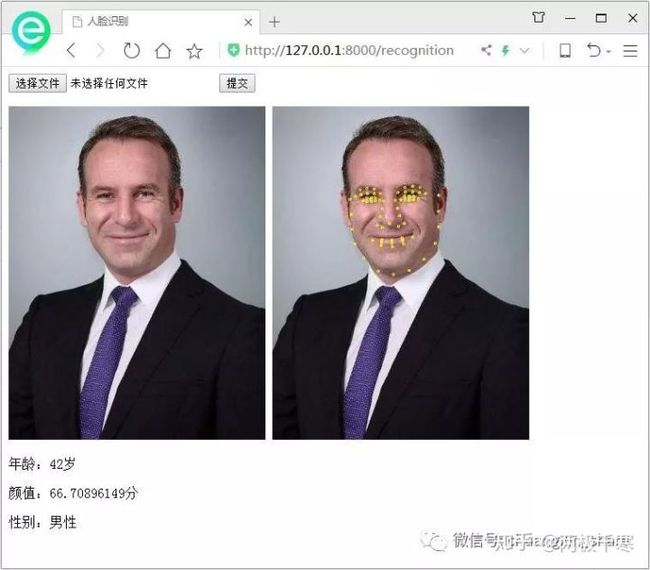
恭喜,走到这一步,我们就完成了人脸识别的效果,是不是有点激动,呵呵!
从开始安装环境到通过浏览器访问效果,对于熟悉代码的人来说,其实很简单,但对于刚接触的小白来说,却是挺不容易,整个过程必然会遇到很多坑,希望通过这篇文章,大家尽量少走些坑。