Hadoop完全分布式 -- HA配置
以3台机器配置 hadoop HA 为例
hadoop CDH版本:hadoop-2.6.0-cdh5.15.0.tar.gz
zookeeper CDH版本:zookeeper-3.4.5-cdh5.15.0.tar.gz
一、配置好3台虚拟机 hosts
$ vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.211.212 bigdata01
192.168.211.213 bigdata02
192.168.211.214 bigdata03
二、关闭防火墙(root用户下)
# service iptables status(查看防火墙状态)
iptables: Firewall is not running. (防火墙已关闭)
# service iptables stop(关闭防火墙)
#chkconfig iptables off(开机不自启动)
三、配置所有节点的ssh免密码登录设置
ssh-keygen -t rsa
然后发送给每一台,也要发送自己
ssh-copy-id bigdata01
ssh-copy-id bigdata02
ssh-copy-id bigdata03
或者 ssh-copy-id bigdata01;ssh-copy-id bigdata02;ssh-copy-id bigdata03
四、3台机器时间同步
1、模拟内网环境
在集群中找一台服务器作为:时间服务器
bigdata01 时间服务器
bigdata02和bigdata03同步01这台机器
2、查看Linux中的ntpd时间服务(这里只要开启第一台机器的ntpd服务,其他的不用开)
$ sudo service ntpd status
$ sudo service ntpd start
3、开机设置(在第一台设置,其他不要设置)
$ sudo chkconfig ntpd on
4、修改系统文件
# vi /etc/ntp.conf
【第一处】修改为自己的网段,注意将前面的#去掉,生效
# Hosts on local network are less restricted.
restrict 192.168.163.0 mask 255.255.255.0 nomodify notrap
【第二处】由于是内网环境不用添加服务,前面加上注释
#server 0.centos.pool.ntp.org
#server 1.centos.pool.ntp.org
#server 2.centos.pool.ntp.org
【第三处】开启本地服务,注意将前面的#去掉,生效
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
保存文件(:wq)
5、修改完配置文件,建议重启ntpd服务,重新读取配置
$ sudo service ntpd restart
6、查看时间服务相关的命令
rpm -qa | grep ntp
ntpdate-4.2.4p8-3.el6.centos.x86_64 同步
ntp-4.2.4p8-3.el6.centos.x86_64 将某台选为时间服务器
7、可以先执行同步操作测试下
sudo /usr/sbin/ntpdate bigdata-01
误差在两三分钟内,是可以接受的
8、编写crontab定时任务,在需要同步的节点上编写(第二台和第三台)
$ sudo crobtab -e
#同步 bigdata01 时间
0-59/10 * * * * /usr/sbin/ntpdate bigdata-01
9、报错整理:
1)报错:11 Sep 09:04:55 ntpdate[2022]: the NTP socket is in use, exiting
原因:这个是你在使用2或者3的机器同步1的时候,2和3的机器的ntpd服务没关,关了就好了,
解决:service ntpd stop(先关闭服务)chkconfig ntpd off
2)报错:11 Sep 09:05:46 ntpdate[2039]: no server suitable for synchronization found
原因:1、理论上同步是要时间的,有可能它还在同步,然后你执行了这句话,所以会报异常
2、也有可能你的防火墙和子安全系统把他的端口挡住了,所以他同步不了
解决:第一种情况,只能等,一般5分钟左右
第二种情况,把防火墙和子安全系统关了(或者开放123端口)
或者可以试试 ntpdate -u bigdata-01 -u的意思是避过防火墙
vi /etc/selinux 改成disable service iptables off
博客:http://blog.csdn.net/qq_19175749/article/details/50792048
3)报错:这个就是我上课时候出的问题,明明2,3台同步成功了,时间也是正确的(跟现实的时间是一样的)
但是1的机器实际上本地时间是错的,那就很恶心了
原因:应该是我之前在那台机器上操作了什么不可言喻的东西!
解决:先查看下你的时区(+0800是正确的,就是东八区) date -R
rm -rf /etc/localtime ---如果时区不是+0800
ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
这样子你的时间应该就是正常的了
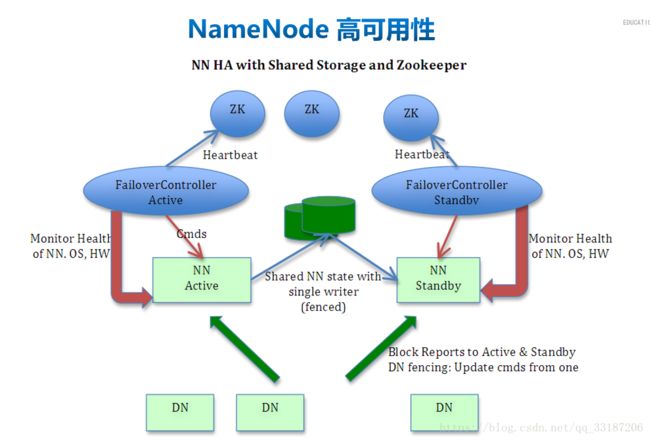
【Hadoop集群模式环境部署 HA】
一、服务节点的部署规划

HA 有两种状态:
1、故障,需要手动切换
2、故障,自动故障转移
ps:在下面的配置中,是完整的配置(就是包括自动故障转移的配置,但是其实操作的步骤并没有一开始就配置好自动故障转移,所以配置文件中我会标出,然后有几个属性先别配置)
二、ZooKeeper 配置--分布式模式
1、把 zookeeper-3.4.5-cdh5.15.0.tar.gz 解压到一个目录中
$ tar -zxvf zookeeper-3.4.5-cdh5.15.0.tar.gz -C /opt/modules/
2、修改conf/zoo_sample.cfg 重命名 zoo.cfg文件
3、指定ZK本地存储的数据存放目录
dataDir=/opt/modules/distribute/zookeeper-3.4.5-cdh5.15.0/data/zkData
4、指定所有ZK的节点以及端口号(内部相互通信端口号:选举端口号)
server.1=bigdata01:2888:3888
server.2=bigdata02:2888:3888
server.3=bigdata03:2888:3888
ps:
2181表示客户端端口号
2888表示ZK节点内部通信端口号
3888表示ZK内部选举端口号
5、在dataDir=/opt/modules/distribute/zookeeper-3.4.5-cdh5.15.0/data/zkData路径下创建文件
创建名为myid的文件,注意一定要这个文件名
写对应的编号,比如:1
6、将配置分发到其他节点上
scp -r zookeeper-3.4.5-cdh5.15.0/ bigdata02:/opt/modules/distribute/
scp -r zookeeper-3.4.5-cdh5.15.0/ bigdata03:/opt/modules/distribute/
7、分发完成之后需要更改其他节点上的myid对应编号
里面的值就是第一台机器写1,第二台写2,第三台写3,就可以了,要跟你的server.1这里的1
8、启动所有ZK的节点
bin/zkServer.sh start
9、查看状态
bin/zkServer.sh status
当看到 2个: follower 和 1个: leader 说明配置成功
三、配置 Hadoop 集群
1、在hadoop-env.sh和mapred-env.sh还有yarn-env.sh中写上你的jdk路径(有可能这条属性被注释掉了,记得解开,把前面的#去掉就可以了)
export JAVA_HOME=/opt/modules/jdk1.8.0_171
2、配置 /opt/modules/distribute/hadoop-2.6.0-cdh5.15.0/etc/hadoop 下的5个文件
core-site.xml
hdfs-site.xml
mapred-site.xml(重命名:mapred-site.xml.template)
yarn-site.xml
slaves
-------------------------------------------------------------
1)、core-site.xml
-------------------------------------------------------------
-------------------------------------------------------------
2)、hdfs-site.xml
-------------------------------------------------------------
-------------------------------------------------------------
3)、mapred-site.xml
-------------------------------------------------------------
-------------------------------------------------------------
4)、yarn-site.xml
-------------------------------------------------------------
-------------------------------------------------------------
5)、slaves
-------------------------------------------------------------
bigdata-01
bigdata-02
bigdata-03
-------------------------------------------------------------
3、分发文件
注:只要配置一台,配置完了,把配置分发给其他机器,使用如下命令(scp命令):
提醒下,你发送前可以把hadoop中的share/doc这个目录下的东西删掉,因为是些帮助文档,太大了,影响传输速度所以。。。
$ rm -rf share/doc
$ scp -r hadoop-2.6.0-cdh5.15.0/ bigdata02:/opt/modules/distribute/
$ scp -r hadoop-2.6.0-cdh5.15.0/ bigdata03:/opt/modules/distribute/
四、启动 Hadoop 集群
【启动过程】
1、首先zookeeper已经启动好了吧(三台都要启动)
开启命令 bin/zkServer.sh start
2、启动三台journalnode(这个是用来同步两台namenode的数据的)
$ sbin/hadoop-deamon.sh start journalnode
3、操作namenode(只要格式化一台,另一台同步,两台都格式化,你就做错了!!)
1)、格式化第一台:
$ bin/hdfs namenode -format
2)、启动刚格式化好的namenode:
$ sbin/hadoop-deamon.sh start namenode
3)、在第二台机器上同步namenode的数据:
$ bin/hdfs namenode -bootstrapStandby
4)、启动第二台的namenode:
$ sbin/hadoop-deamon.sh start namenode
4、查看web(这里应该两台都是stanby)
注意:如果用主机名登陆,必须在 C:\Windows\System32\drivers\etc 下的 hosts配置映射
http://bigdata01:50070
http://bigdata02:50070
5、然后手动切换namenode状态
手动切换namenode状态(也可以在第一台切换第二台为active,毕竟一个集群)
$ bin/hdfs haadmin -transitionToActive nn1 ##切换成active
$ bin/hdfs haadmin -transitionToStandby nn1 ##切换成standby
注: 如果不让你切换的时候,bin/hdfs haadmin -transitionToActive nn2 --forceactive
也可以直接通过命令行查看namenode状态, bin/hdfs haadmin -getServiceState nn1
--------------------------以上手动故障转移已经配置成功了-----------------------------------------
6、配置自动故障转移
1)、首先你要把你的hadoop集群完整的关闭,一定要全关了!!
zookeeper 的(QuorumPeerMain)不用关闭
2)、把 hadoop文件下 hdfs-site.xml 之前注释的打开(3台都打开)
3)、自动故障转移的配置其实要在zookeeper上生成一个节点 hadoop-ha,这个是自动生成的,通过下面的命令生成:
$ bin/hdfs zkfc -formatZK
3)、你登录zookeeper的客户端,就是bin/zkCli.sh里面通过 “ls /” 可以看到多了个节点
这时候讲道理集群应该是没问题了!
你可以直接通过sbin/start-dfs.sh去启动hdfs,默认会启动zkfc的,其实就是一个自动故障转移的进程,会在你的namenode存在的两台机器上有这么一个节点。
其中:历史服务(obHistoryServer)和yarn 的ResourceManager 在那台机器上手动开启
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/mr-jobhistory-daemon.sh start historyserver
三台机器:jps(说明配置没问题了)

等到完全启动了之后,就可以kill掉active的namenode,你就会发现stanby的机器变成active,然后再去启动那台被你kill掉的namenode(启动起来是stanby的状态),然后你再去kill掉active,stanby的机器又会变成active,到此你的HA自动故障转移已经完成了。
这是官网的帮助文档:http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
后话:其实也可以做resourcemanager的HA,但是其实你能搭出namenode的HA,对于你来说,resourcemanager的HA就很简单了。
===========================以上是自动故障转移配置完成============================
【配置 resourcemanager的HA】
官网文档:http://hadoop.apache.org/docs/r2.5.2/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html

一、集群规划
其实就跟上面一样,只是我在第三台机器上也启动一个resourcemanager的备用节点
二、配置文件
只修改yarn-site.xml文件
-------------------------------------------------------------
yarn-site.xml
-------------------------------------------------------------
-------------------------------------------------------------
发送yarn-site.xml 到其他机器
scp etc/hadoop/yarn-site.xml bigdata02:/opt/modules/distribute/hadoop-2.6.0-cdh5.15.0/etc/hadoop/
scp etc/hadoop/yarn-site.xml bigdata03:/opt/modules/distribute/hadoop-2.6.0-cdh5.15.0/etc/hadoop/
三、启动 ResourceManager
在bigdata02上:
sbin/start-yarn.sh
在bigdata03上:
sbin/yarn-daemon.sh start resourcemanager
三台机器:jps(说明配置没问题了)

观察web 8088端口
当bigdata02的ResourceManager是Active状态的时候,访问bigdata03的ResourceManager会自动跳转到PC02的web页面
测试HA的可用性
查看的状态:
bin/yarn rmadmin -getServiceState rm1 ##查看rm1的状态
bin/yarn rmadmin -getServiceState rm2 ##查看rm2的状态
然后你可以提交一个job到yarn上面,当job执行一半(比如map执行了100%),然后kill -9 掉active的rm
这时候如果job还能够正常执行完,结果也是正确的,证明你rm自动切换成功了,并且不影响你的job运行!!!
结束。。。。。。。。
后话:
其实正常情况下,主节点是不会直接坏掉的(除非机器坏掉,那我无话可说),往往是比如某个进程占用cpu或者内存极大,有可能被linux直接kill掉
这种时候,ha并没有那么灵敏,就是说,不一定能马上切换过去,可能有几分钟延迟,所以我们应该做的是避免一些主节点挂掉的情况。
所以可以使用spark或者storm做预警系统,当hadoop的日志文件里面出现warning的时候,能够实时报警(比如向维护人员发短信,发邮件之类的功能)
在事故发生之前,处理可能发生的故障!