tensorflow.python.framework.errors_impl.OutOfRangeError? GitHub上andabi/ deep-voice-conversion/ 的解决方法
本例程序是用于人声转换的,将任意说话人的语音转换为特定说话人(English actress Kate Winslet)的声音。
GitHub地址: https://github.com/andabi/deep-voice-conversion
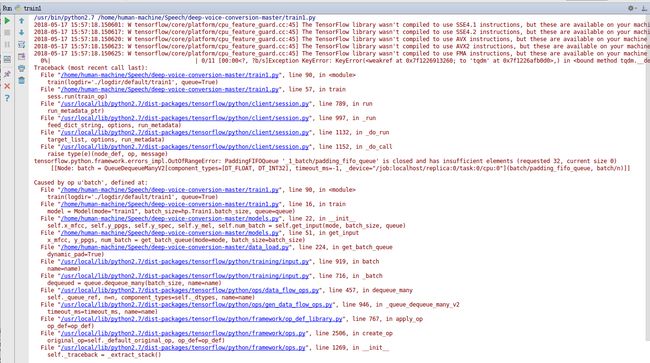
设置 train(logdir='./datasets/timit/TIMIT/TRAIN', queue=True),程序报错如:
Traceback (most recent call last):
File "/home/human-machine/Speech/deep-voice-conversion-master/train1.py", line 90, intrain(logdir='./logdir/default/train1', queue=True)
File "/home/human-machine/Speech/deep-voice-conversion-master/train1.py", line 57, in train
sess.run(train_op)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/client/session.py", line 789, in run
run_metadata_ptr)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/client/session.py", line 997, in _run
feed_dict_string, options, run_metadata)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/client/session.py", line 1132, in _do_run
target_list, options, run_metadata)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/client/session.py", line 1152, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.OutOfRangeError: PaddingFIFOQueue '_1_batch/padding_fifo_queue' is closed and has insufficient elements (requested 32, current size 0)
[[Node: batch = QueueDequeueManyV2[component_types=[DT_FLOAT, DT_INT32], timeout_ms=-1, _device="/job:localhost/replica:0/task:0/cpu:0"](batch/padding_fifo_queue, batch/n)]]
我的相关博客: https://blog.csdn.net/qq_34638161/article/details/80387829
*********************************************************************************分 割 线******************************************************************************************
解决方法:
sess.run(tf.global_variables_initializer()) 前面加上一行:
sess.run(tf.local_variables_initializer())
sess.run(tf.global_variables_initializer())
注意:此处用 sess.run(tf.group(tf.local_variables_initializer(),tf.global_variables_initializer())) 不行
安装模块 ffmpeg:sudo apt install ffmpeg,安装后运行就没有报错了:tensorflow.python.framework.errors_impl.OutOfRangeError
FFmpeg:是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。
设置 train(logdir='./datasets/timit/TIMIT/TRAIN', queue=False) ,运行,出现报错,更改相应的文件:
data_load.py中的 phn_file = wav_file.replace("WAV.wav", "PHN").replace("wav", "PHN") 改为:
phn_file = wav_file.replace("WAV.wav", "phn").replace("wav", "phn")
在 train(logdir='./datasets/timit/TIMIT/TRAIN', queue=False)下运行:
图一:

但是在 train(logdir='./datasets/timit/TIMIT/TRAIN', queue=True)下运行会卡顿在第一个epoch:
附上代码 tain1.py :
# -*- coding: utf-8 -*-
# /usr/bin/python2
from __future__ import print_function
import hparams as hp
from hparams import logdir_path
from tqdm import tqdm
from modules import *
from models import Model
import eval1
from data_load import get_batch
import argparse
def train(logdir='./logdir/default/train1', queue=True):
model = Model(mode="train1", batch_size=hp.Train1.batch_size, queue=queue)
# Loss
loss_op = model.loss_net1()
# Accuracy
acc_op = model.acc_net1()
# Training Scheme
global_step = tf.Variable(0, name='global_step', trainable=False)
optimizer = tf.train.AdamOptimizer(learning_rate=hp.Train1.lr)
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
var_list = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, 'net/net1')
train_op = optimizer.minimize(loss_op, global_step=global_step, var_list=var_list)
# Summary
# for v in tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, 'net/net1'):
# tf.summary.histogram(v.name, v)
tf.summary.scalar('net1/train/loss', loss_op)
tf.summary.scalar('net1/train/acc', acc_op)
summ_op = tf.summary.merge_all()
session_conf = tf.ConfigProto(
gpu_options=tf.GPUOptions(
allow_growth=True,
),
)
# Training
with tf.Session() as sess:
# with tf.Session(config=session_conf) as sess:
# Load trained model
# sess.run(tf.local_variables_initializer())
# sess.run(tf.global_variables_initializer())
# sess.run(tf.global(tf.global_variables_initializer(), tf.local_variables_initializer())
sess.run(tf.global_variables_initializer())
model.load(sess, 'train1', logdir=logdir)
writer = tf.summary.FileWriter(logdir, sess.graph)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
# threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for epoch in range(1, hp.Train1.num_epochs + 1):
for step in tqdm(range(model.num_batch), total=model.num_batch, ncols=70, leave=False, unit='b'):
if queue:
sess.run(train_op)
else:
mfcc, ppg = get_batch(model.mode, model.batch_size)
sess.run(train_op, feed_dict={model.x_mfcc: mfcc, model.y_ppgs: ppg})
# Write checkpoint files at every epoch
if queue:
summ, gs = sess.run([summ_op, global_step])
else:
summ, gs = sess.run([summ_op, global_step], feed_dict={model.x_mfcc: mfcc, model.y_ppgs: ppg})
if epoch % hp.Train1.save_per_epoch == 0:
tf.train.Saver().save(sess, '{}/epoch_{}_step_{}'.format(logdir, epoch, gs))
# Write eval accuracy at every epoch
with tf.Graph().as_default():
eval1.eval(logdir=logdir, queue=False)
writer.add_summary(summ, global_step=gs)
writer.close()
coord.request_stop()
coord.join(threads)
def get_arguments():
parser = argparse.ArgumentParser()
parser.add_argument('case', type=str, help='experiment case name')
# parser.add_argument('case', type=str, help='timit')
arguments = parser.parse_args()
return arguments
if __name__ == '__main__':
# train(logdir='./logdir/default/train1', queue=True)
train(logdir='./datasets/timit/TIMIT/TRAIN', queue=True)
# train(logdir='./datasets/timit/TIMIT/TRAIN', queue=False)
args = get_arguments()
case = args.case
logdir = '{}/{}/train1'.format(logdir_path, case)
# train(logdir=logdir)
train(logdir=logdir, queue=False)
print("Done")