数据仓库与数据挖掘
同事从家里带来两本老书:一本《数据仓库与数据挖掘教程》,06年出版的数据处理高校教材;另一本《网络科学导论》,12年出版的复杂网络教材。
美名其曰:交流学习。

两本都是非常基础的理论入门教材,但网络科学这一块实在是一点概念都没有,什么网络拓扑性质、网络动力学、网络控制等看不明白,再一次感叹术业有专攻,就不挣扎了!

而《数据仓库与数据挖掘教程》是老本行,拿起这本书就有一种亲切感,虽然书里的概念写的很基础,现在看来就是一些科普性的东西。俗话说温故而知新,当你再回过头来理一些基础知识,对于当初刚接触时又多了一些不同的理解,所以这篇文章也是对数据仓库与数据挖掘做的基础知识小结。
数据仓库与数据挖掘之所以兴起,在于它们能够从丰富的数据资源中提供效果显著的决策支持。数据仓库、数据挖掘、联机分析处理(on line analytical processing,OLAP)等结合起来也称为商业智能(business intelligence,BI)。
商业智能是一种新的智能技术,区别于人工智能(artificial intelligence,AI)和计算智能(computationalintelligence,CI)。
人工智能采用的技术是符号推理,符号推理过程形成了概念的推理链。
计算智能采用的技术是计算推理,模拟人和生物的模糊推理、神经网络计算和遗传进化过程。

数据仓库体系
数据仓库系统结构由数据仓库、仓库管理和分析工具3部分组成。
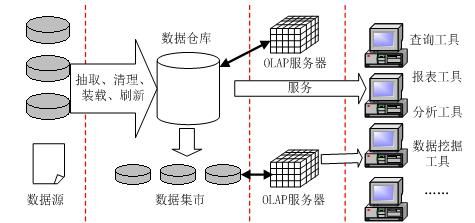
(数据仓库系统结构图)
仓库管理包括数据建模,数据抽取、转换、装载(ETL),元数据,系统管理4部分。
-
数据建模是建立数据仓库的数据模型,常见的有星型模型、雪花模型和星网模型;
-
元数据描述了数据仓库中有什么数据以及数据之间的关系。
分析工具包括查询工具、多维数据分析工具(OLAP工具)、数据挖掘工具(DM工具)、客户/服务(client/server,C/S)工具等。
数据仓库的开发主要围绕数据仓库功能展开的,包括数据获取、数据存储和决策分析。随着决策需求的扩大,数据仓库的数据将迅速增长。数据仓库为了适应这种变化,采用螺旋式周期性的开发方法较为合适,分为4个阶段12个具体步骤,如下:
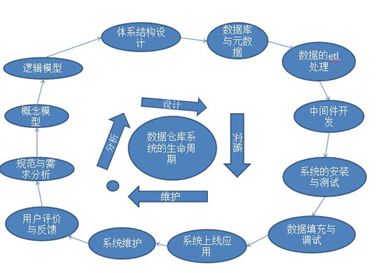
(数据仓库开发过程图)
数据仓库搭建后用户分两类:信息使用者和探索者。
信息使用者是数据仓库的大量用户,他们以一种可预测的、重发性的方式使用数仓,通常查看概括数据或聚集数据,查看相同的商业维度和指标随时间的发展趋势,很少使用元数据,他们的工作相对来说属于战术性的。
探索者在数仓上的使用模式是完全不可预测的、非重复性的。他们经常查看历史数据,任务是寻找公司数据内隐含的价值并且根据过去事件努力预测未来决策的结果,是典型的数据挖掘者。
数据仓库本身存储着大量数据,随着时间的延伸又会涌进大量的数据。不仅要对大量存储数据进行有效管理,同时需要对元数据进行管理。
数据管理中要处理两大类数据:休眠数据和脏数据。发现这两类数据都需要监视器。
-
休眠数据表示那些存在于数据仓库中当前不使用、将来也很少使用或不使用的数据。
-
脏数据指在数据源中抽取、转换和装载到数据仓库的过程中出现的多余数据和无用数据。
管理大量数据的最好办法就是删除休眠数据和脏数据,为了识别出这些数据需要利用数据使用跟踪器(活动跟踪器)。监视活动分为3个级别:表格级、表格/列级和表格/列/值级,一般开销较大。
建立数据仓库的目的不只是为了存储更多的数据,而是对这些数据进行处理并转换成商业信息和知识,利用这些信息来支持企业进行正确的商业行动,并最终获得效益。数仓提供的决策支持一般包括查询与报表、多维分析与原因分析、预测未来、实时决策和自动决策等5种。
数据挖掘理论
数据挖掘的一种更广义说法是知识发现(knowledge Discovery inDatabase,KDD),知识发现被认为是从数据中发现有用知识的整个过程,数据挖掘作为它的一个特定步骤,用专门算法从数据中抽取模式,仅占KDD部分的15%~25%。
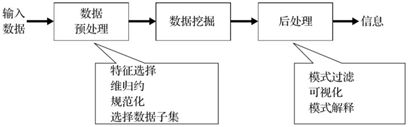
(KDD过程图)
数据挖掘任务:关联分析、时序模式、聚类、分类、偏差检测、预测。
数据挖掘涉及学科:数据库、统计学、机器学习三大主要技术。
数据挖掘方法和技术分类:归纳学习类、仿生物技术类、公式发现类、统计分析类、模糊数学类、可视化技术类。
-
归纳学习类包含信息论和集合论方法,主要以决策树、关联规则为代表的一些方法,目前的研究成果较多,也较为实用。
-
仿生物技术典型的方法是神经网络方法和遗传算法,这两类目前也形成了独立的研究体系,在数据挖掘中发挥了巨大的作用。
-
公式发现类即对若干数据项进行一定的数学运算,求得相应的数学公式。
-
可视化数据挖掘是创建可视化的数据挖掘模型,利用这些模型发现业务数据集中存在的模式,从而辅助决策支持及预测新的商机。
数据挖掘对象:数据仓库和关系数据库、文本数据、图像与视频数据,Web数据等。
-
文本数据是半结构化数据,主要面临的问题是挖掘对象既不是完全无结构的也不是完全结构化的,而且自然语言文本中包含多层次的歧义(词汇、句法、语义、语用)等。
-
从广义上讲,Web数据也是一类特别的文本信息,文本挖掘的技术也适用于web挖掘,但由于web信息自身的特点,它们应该区别对待。Web挖掘面临的问题是数据量非常庞大且复杂,信息不断在发生着更新,面对的用户群体也各色各样,信息中的“垃圾”也非常多。
数据仓库和数据挖掘的发展
综合决策支持系统
人们通过建立一些数学模型来增强对付复杂的大规模问题的处理能力,使人们尽可能的按客观规律办事,不犯错误。随着新技术的发展,所需要解决的问题会愈来愈复杂,所设计的模型愈来来愈多,不仅是几个而是十多个,几十个,以至上百个模型来解决一个大问题。
决策支持系统(decision support systems ,DSS)的出现就是解决由计算机自动组织和协调多模型的运行及数据库中大量数据的存取和处理,达到更高层次的辅助决策能力。为达到决策支持系统有效地运行,它对语言系统的功能地要求比较高,即它应具有调用模型运行能力、数据库存取能力、数值运算能力、数据处理能力、人机交互能力5种综合能力。
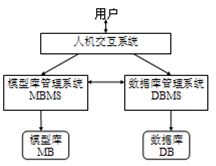
(决策支持系统结构)
智能决策支持系统(intelligence decision supportsystems,IDSS)是决策支持系统与人工智能技术相结合的系统,也是DSS的重要发展方向。人工智能技术融入决策支持系统后,增加了知识推理技术,使定量分析与定性分析结合起来,提高辅助决策和支持决策能力。这些人工智能技术可以概括为:推理机+知识库。
把数据仓库、联机分析处理、数据挖掘、模型库(MB)、数据库、知识库(KB)结合起来形成的综合决策支持系统(synthetic intelligencedecision support systems,SDSS)是更高级形式的决策支持系统。

(综合决策支持系统结构)
综合决策支持系统(SDSS)由3个主体组成:
-
模型库系统和数据库系统结合的主体,该主体完成多模型的组合与大量共享数据的处理。
-
数据仓库系统与联机分析处理结合的主体,该主体完成对数据仓库中数据的综合、预测和多维数据分析。
-
知识库系统与数据挖掘结合的主体,该主体完成推理。
可拓数据挖掘
可拓学的理论就是通过可拓变换与可拓知识来改变问题的目的或条件,去解决矛盾的问题。数据挖掘是从数据中挖掘出知识,由于数据具有静态性,代表已存在的事实,所挖掘的知识也具有静态性。而可拓数据挖掘以可拓集为理论基础,致力于挖掘可拓知识,挖掘变化知识比挖掘静态知识更有意义。
参考资料(图片来源于网络)
可拓知识=拓展式(基础知识)+变换蕴含式(变化知识)+关联函数
https://www.sohu.com/a/225194032_617676大数据与商业智能有什么区别?
https://baike.baidu.com/reference/6493200/d9c2PzEIdy7_pyyTgqmfQhl2cepWTfoUqR4wO3DAGCyCOmgc3Jiw2-7y9yv98ltemND1cC_UI-DFulOfU4UiXmismBJa可拓集与可拓数据挖掘