sklearn中tfidf的计算与手工计算不同详解
sklearn中tfidf的计算与手工计算不同详解
引言:本周数据仓库与数据挖掘课程布置了word2vec的课程作业,要求是手动计算corpus中各个词的tfidf,并用sklearn验证自己计算的结果。但是博主手动计算的结果无论如何也与sklearn中的结果无法对应,在查阅大量资料无果的情况下,只好自己去阅读源码了,最后成功解决了这一问题。
题目背景:
作业:
1. corpus=["我 来到 北京 清华大学",
"他 来到 了 网易 杭研 大厦",
"小明 硕士 毕业 于 中国 科学院",
"我 爱 北京 天安门"]
手工计算完成BOW向量化和tfidf向量化,并 用python及sklearn实现,看下手工计算和程序输出结果一样吗 。
TF-IDF手工计算
(tf-idf计算这里网络上的其他文章基本都有,这里只给出基本的定义)
简介:TF-IDF(Term Frequency-InversDocument Frequency)是一种常用于信息处理和数据挖掘的加权技术。该技术采用一种统计方法,根据字词的在文本中出现的次数和在整个语料中出现的文档频率来计算一个字词在整个语料中的重要程度。它的优点是能过滤掉一些常见的却无关紧要本的词语,同时保留影响整个文本的重要字词。
计算步骤:
1.计算TF
简介:TF,是Term Frequency的缩写,就是某个关键字出现的频率,即词库中的某个词在当前文章中出现的频率。
计算公式:
词频TF = 某个词在文章中出现的次数 / 本篇文章中词的总数
考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。
其中如果一个词在文中出现的频率越多,说明这个词TF就越大。
2.计算IDF
英文全称:Inverse Document Frequency,即“逆文档频率”。计算IDF需要一个语料库,用来模拟语言的使用环境。文档频率DF就是一个词在整个文库词典中出现的频率,如一个文件集中有100篇文章,共有10篇文章包含“机器学习”这个词,那么它的文档频率就是10/100=0.1,逆文档频率IDF就是这个值的倒数,即10。
计算公式:
IDF(N) = log(文档总数 / 出现N这一词汇的文档数目)
其中如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。
log表示对得到的值取对数。
3.计算TF-IDF=TF*IDF
Sklearn中的TFIDF
(下面引用一段sklearn源码中的注释,可以帮助不了解的读者直接使用)
Examples
--------
>>> from sklearn.feature_extraction.text import TfidfTransformer
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> from sklearn.pipeline import Pipeline
>>> import numpy as np
>>> corpus = ['this is the first document',
... 'this document is the second document',
... 'and this is the third one',
... 'is this the first document']
>>> vocabulary = ['this', 'document', 'first', 'is', 'second', 'the',
... 'and', 'one']
>>> pipe = Pipeline([('count', CountVectorizer(vocabulary=vocabulary)),
... ('tfid', TfidfTransformer())]).fit(corpus)
>>> pipe['count'].transform(corpus).toarray()
array([[1, 1, 1, 1, 0, 1, 0, 0],
[1, 2, 0, 1, 1, 1, 0, 0],
[1, 0, 0, 1, 0, 1, 1, 1],
[1, 1, 1, 1, 0, 1, 0, 0]])
>>> pipe['tfid'].idf_
array([1. , 1.22314355, 1.51082562, 1. , 1.91629073,
1. , 1.91629073, 1.91629073])
>>> pipe.transform(corpus).shape
(4, 8)
现在进入正题,在本次作业中,以上面的corpus和程序范例为背景运行程序会得出以下的结果
from sklearn.feature_extraction.textimport TfidfTransformer
from sklearn.feature_extraction.textimport CountVectorizer
if __name__ =="__main__":
corpus = ["我 来到 北京 清华大学", # 第一类文本切词后的结果,词之间以空格隔开
"他 来到 了 网易 杭研 大厦", # 第二类文本的切词结果
"小明 硕士 毕业 于 中国 科学院", # 第三类文本的切词结果
"我 爱 北京 天安门"]# 第四类文本的切词结果
vectorizer = CountVectorizer()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
print(tfidf)
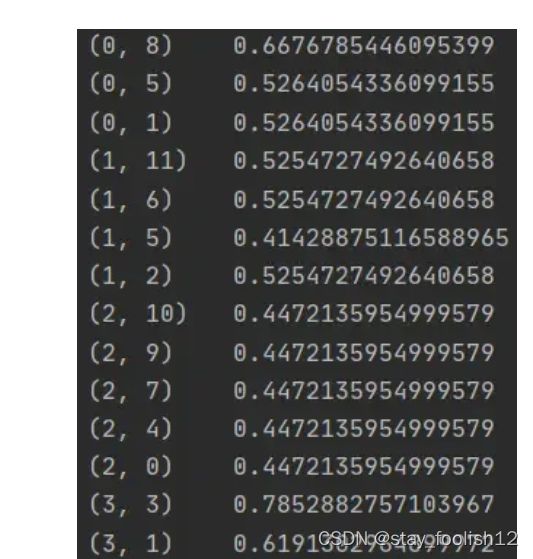
程序运行结果
我相信绝大多数的朋友得到的也是上图的结果,这与手工计算的结果大相径庭。不止结果不一样,甚至词汇数目都对不上,这实在令人难以接受。那么究竟是怎么一回事呢?
先说结论:
1.更改CountVectorizer的初始化参数token_pattern=r"(?u)\b\w+\b"
2.更改TfidfTransformer的初始化参数norm=None,smooth_idf=False.
3.更改手工idf计算方式:由lg(以10为底)改为ln(以e为底)
经过以上步骤的处理,手工计算的tfidf和程序计算的tfidf就是相同的了,那么为什么会出现这样的问题呢?
还是从源码说起吧
1.更改CountVectorizer的初始化参数
源码中的注释部分这样解释token_pattern
token_pattern : str, default=r"(?u)\\b\\w\\w+\\b"
Regular expression denoting what constitutes a "token", only used
if ``analyzer == 'word'``. The default regexp select tokens of 2
or more alphanumeric characters (punctuation is completely ignored
and always treated as a token separator).
If there is a capturing group in token_pattern then the
captured group content, not the entire match, becomes the token.
At most one capturing group is permitted.
个人理解:CountVectorizer类在初始化时会默认词汇辨认形式为r"(?u)\b\w\w+\b",这是一个双字符以上的字符串,这样就导致了在原题目中"我",“他”,“了”,“于"的丢失,这就是导致我们词汇数目不匹配的元凶!因为他们是单字符,所以我们把这个类的接受形式改为单字符即可(r”(?u)\b\w+\b")。
2. 更改TfidfTransformer的初始化参数
源码中的norm解释部分,以及smooth_idf解释部分
norm : {'l1', 'l2'}, default='l2'
Each output row will have unit norm, either:
* 'l2': Sum of squares of vector elements is 1. The cosine
similarity between two vectors is their dot product when l2 norm has
been applied.
* 'l1': Sum of absolute values of vector elements is 1.
See :func:`preprocessing.normalize`
smooth_idf : bool, default=True
Smooth idf weights by adding one to document frequencies, as if an
extra document was seen containing every term in the collection
exactly once. Prevents zero divisions.
norm很好理解,sklearn自动为我们做了l2正则化,所以我们的结果和他的不同。因此只要不使用正则化即可(norm=None)
那下面的smooth_idf又是什么情况呢?(这里网上的各种资料简直是迷惑行为大赏,抄来抄去,说的全都含混不清)
首先我们要牢记,最基础的idf定义就是文章上面写的定义!!!
那其他的idf定义是正确的吗?比如idf = log(N + 1/ N(x) + 1),以及该式子的各种变形?
如果你使用了smooth_idf,那么上式正确。
那么什么是smooth_idf呢,举个栗子:
corpus_no_smooth=["我 来到 北京 清华大学",
"他 来到 了 网易 杭研 大厦",
"小明 硕士 毕业 于 中国 科学院",
"我 爱 北京 天安门"]
corpus_with_smooth=["我 来到 北京 清华大学",
"他 来到 了 网易 杭研 大厦",
"小明 硕士 毕业 于 中国 科学院",
"我 爱 北京 天安门",
"我 来到 北京 清华大学 他 了 网易 杭研 大厦 小明 硕士 毕业 于 中国 科学院 爱 天安门 " ]
其实就是将出现过的所有词汇放入一个新生成的文章之中,确保idf初始定义中的分母不为0。
3.用ln来计算自己的idf
其实这是一个很搞的问题,sklearn中使用的是numpy库中的log函数,这个函数就是ln函数,在源码中所有的计算都是用的numpy.log(),这同样导致了我们的结果与程序完全不同。
虽然这个问题事后看来并不是一个非常困难的问题,但是因为这个问题需要更改好几个参数甚至要更改自己,也因为某些垃圾博主只会抄袭,根本不深入研究,导致我根本找不到一个解决这个问题的博客,最后只能自己动手解决。尽管浪费了很多时间,但还是比较值得的,也希望对其他被这个问题困扰的同学有帮助吧 。