Python爬虫实例:测单词量并生成错词本
文章目录
- 爬虫实例:测单词量的功能、生成错词本
- 分步讲解 (╹▽╹)
- (1). 选择题库。
- (2). 根据选择的题库,获取50个单词。
- (3). 让用户选择认识的单词:此处,要分别记录下用户认识哪些,不认识哪些。
- (4). 对于用户认识的单词,给选择题让用户做:此处要记录用户做对了哪些,做错了哪些。
- (5). 生成报告:50个单词,不认识多少,认识多少,掌握多少,错了多少。
- (6). 整理代码,可以加一些修饰词,欢迎语。
爬虫实例:测单词量的功能、生成错词本
扇贝网:https://www.shanbay.com/已经有一个测单词量的功能,
我们要做的就是把这个功能复制下来,并且做点改良,搞一个网页版没有的功能 ———— 生成错词本。
分步讲解 (╹▽╹)
(1). 选择题库。
写这个程序,要用到requests模块。
先用requests下载链接,再用res.json()解析下载内容。
让用户选择想测的词库,输入数字编号,获取题库的代码。
提示:1.记得给input前面加一个int()来转换数据类型。
2.观察选择每种词库的URL,找到规律,根据用户选择的词库构造出相应题库的URL。

(2). 根据选择的题库,获取50个单词。
第1步我们已经拿到链接,这步直接用requests去下载,re.json()解析即可。
提示:在XHR里找哦。
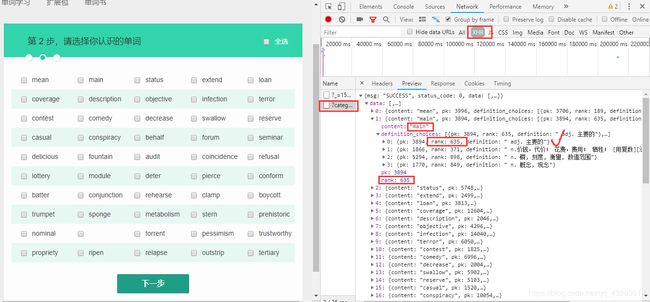
(3). 让用户选择认识的单词:此处,要分别记录下用户认识哪些,不认识哪些。
已经有了单词数据,提取出来让用户识别,并记录用户认识哪些不认识哪些,至少2个list来记录。
50个单词,记得要用循环。
用户手动输入自己的选择,用input()。
我们要识别用户的输入,并基于此决定把这个单词放进哪个list,需要用if语句。
提示:1.当一个元素特别长的时候,给代码多加一个list。
2.加个换行,优化用户视角。
(4). 对于用户认识的单词,给选择题让用户做:此处要记录用户做对了哪些,做错了哪些。
这一步是第1步和第3步的组合——涉及到第1步中的选择,也涉及到第3步的数据记录。
提示: 面对冗长的字典列表相互嵌套,可以创建字典。
(5). 生成报告:50个单词,不认识多少,认识多少,掌握多少,错了多少。
生成报告主要有三部分:
第1,是输出统计数据; 第2,是打印错题集; 第3,是把错题集保存到本地。
(6). 整理代码,可以加一些修饰词,欢迎语。
可以利用time.sleep()来暂停输出,下面是我给出的代码:
# -*- coding:utf-8 -*-
import requests,sys,time
print('Welcome to Word Detection (*^▽^*)')
time.sleep(1)
url = 'https://www.shanbay.com/api/v1/vocabtest/category/?'
word_type_json = requests.get(url).json()
word_type = word_type_json['data'] #获取词库种类
n = 0 #用于计数
for type in word_type:
print(str(n) + '. ' + type[1])
n += 1
choose_type = int(input('请输入出题范围的编号:'))
ciku = word_type[choose_type][0] #根据用户选择得到词库
test = requests.get('https://www.shanbay.com/api/v1/vocabtest/vocabularies/?category=' + ciku) #构造词库的URL
words = test.json()['data'] #获取所有单词信息
#用于存单词的list
danci = [] #认识的单词
words_knows = [] #认识的单词(所有信息)
not_knows = [] #不认识的单词(所有信息)
#time.sleep(1)
num = int(input('\n输入你想测试多少个单词呢(1-50个)(^-^)V:')) #用户可能不想直接测50个那么多呢
#time.sleep(1)
print ('\n那测试现在开始。如果你认识这个单词,请输入1后按Enter,否则直接按Enter:')
time.sleep(3)
#用户选择认识 or 不认识
n=1 #用于计数
for x in words:
print('第' + str(n) + '个:' + x['content']) #获取单个单词
answer = input('认识请输入1,否则直接敲Enter:')
if answer == '1':
danci.append(x['content']) #把选择的单词加入,只加入单词
words_knows.append(x) #这里是把整个单词的信息加入,即整个字典加入,因为后面要用到
else:
not_knows.append(x) #不认识的放这里
if n == num:
time.sleep(1)
break
n += 1
#单词检测
time.sleep(1)
if len(danci) != 0:
print('\n在上述' + str(num) +'个单词中,有' + str(len(danci)) + '个是你觉得自己认识的,它们是:')
for word in danci:
print(word, end=' ')
time.sleep(3)
#以选择题形式来检测
print ('\n\n现在来检测一下,你有没有真正掌握它们(*^▽^*):\n')
time.sleep(2)
wrong_words = [] #错词本(也是单词所有信息加入,因为保存本地会用到)
right_num = 0 #记录选择正确的个数
n = 1 #用于计数
for y in words_knows:
print('第' + str(n) + '个:')
for i in range(4): #遍历四个选项
print(str(i+1) + y['definition_choices'][i]['definition'])
choice = int(input('请选择单词\" ' + y['content'] + ' \"的正确翻译:'))
if y['definition_choices'][choice-1]['rank'] == y['rank']: #选择正确
right_num += 1
else:
wrong_words.append(y) #否则整个单词的信息加入错词list
n += 1
print('\n')
time.sleep(3)
print ('现在,到了公布成绩的时刻:')
time.sleep(1)
print ('在 ' + str(num) + ' 个' + word_type[choose_type][1] + '词汇当中,你认识其中 ' + str(len(danci)) + ' 个,')
#time.sleep(1)
print('实际掌握 ' + str(right_num) + ' 个,错误 ' + str(len(wrong_words)) + ' 个。')
#当错词个数不为0时,让用户选择是否保存到本地错词本
time.sleep(1)
if len(wrong_words) != 0:
save = input ('\n\n你是否想打印错词集并保存在本地?(输入 Y 或 N:)')
if save == 'Y':
f = open('错题集.txt', 'a+')
print ('你记错的单词有:')
n = 1
mean = ''
for z in wrong_words:
right_ans = z['rank'] #正确词意号
for i in range(4):
if z['definition_choices'][i]['rank'] == right_ans: #找到正确词意
mean = z['definition_choices'][i]['definition']
break
word = z['content'] + ' ' + mean #把单词和正确词意连起来
print (str(n) + '.' + word)
f.write(word + '\n')
n += 1
f.close()
print('\n没记住的词已保存至当前文件目录下啦♪(^∇^*)')
time.sleep(2)
else:
print('继续加油嗷!(/≧▽≦)/')
else:
print('\n居然一个也不认得,不得行!背背单词再来吧!o(╥﹏╥)o')
#如果不认识的单词个数不为0,让用户选择是否保存到本地错词本
time.sleep(1)
if len(not_knows) != 0:
save = input ('\n那你是否想打印不认识的单词并保存在本地呢?(输入Y或N:)')
if save == 'Y':
f = open('错题集.txt', 'a+')
print ('以下是你不认识的单词:')
n=0
mean = ''
for x in not_knows:
n += 1
right_ans = x['rank']
for i in range(4):
if x['definition_choices'][i]['rank'] == right_ans:
mean = x['definition_choices'][i]['definition']
break
word = x['content'] + ' ' + mean
print(str(n) + '.' + word)
f.write(word + '\n')
f.close()
print ('\n记住的词已保存至当前文件目录下,欢迎下次使用鸭(/≧▽≦)/')
time.sleep(2)
else:
print('\n欢迎下次使用鸭♪(^∇^*)')
else:
print('\n你真棒!记得多背单词鸭~ 欢迎下次使用哦(/≧▽≦)/')
#回车控制退出程序
time.sleep(1)
while input('\n(*╹▽╹*)关闭程序请按回车') == "":
sys.exit()
✿✿ヽ(°▽°)ノ✿~
————————每个人都在抱怨生活不易,可是都在默默为生活打拼————————