数据挖掘与分析 - 用JS实现推荐系统的原理与开发
数据挖掘与分析 - 推荐系统的原理与开发
- 图表一览
- 试想一个推荐系统的应用场景
- 分析应用场景的需求
- 开始开发推荐图书系统
- 常规解决想法
- 曼哈顿距离
- 欧氏距离
- 闵可夫斯基距离
- 皮尔逊相关系数
- 余弦相似度
- 得出推荐图书
- 应该使用哪种相似度?
序言1:“你喜欢的我也喜欢”,这句话算是推荐系统最精华的提炼了。本篇文章将详细讲述推荐系统的几种算法,并尝试用js来实现它。
序言2:由于让数据形象化,我采用了JS的图表框架Chart.js(因为前几天写了几篇Chart.js的笔记)。在阅读本篇文章时,你可能会担心没有掌握Chart.js而看不懂。完全没必要!Chart.js只是我画图展示给大家的工具,大家也可以用Python库来画图。
图表一览
话不多说,上图:

目前仍然不需要看懂这些图,我会在后面一一讲解。
试想一个推荐系统的应用场景
假设,我们爬取了豆瓣的10位用户对5本图书的打分,json数据如下:
dataBase = {
"徐凤年":{"雪中悍刀行":0,"挪威的森林":3,"平凡的世界":1,"资治通鉴":3,"情书1946":5},
"裴南苇":{"雪中悍刀行":4,"挪威的森林":0,"平凡的世界":3,"资治通鉴":4,"情书1946":5},
"曹长卿":{"雪中悍刀行":5,"挪威的森林":3,"平凡的世界":0,"资治通鉴":2,"情书1946":5},
"李淳罡":{"雪中悍刀行":0,"挪威的森林":5,"平凡的世界":4,"资治通鉴":5,"情书1946":1},
"王仙芝":{"雪中悍刀行":5,"挪威的森林":5,"平凡的世界":1,"资治通鉴":1,"情书1946":2},
"温华":{"雪中悍刀行":5,"挪威的森林":3,"平凡的世界":5,"资治通鉴":4,"情书1946":1},
"姜泥":{"雪中悍刀行":0,"挪威的森林":3,"平凡的世界":4,"资治通鉴":4,"情书1946":1},
"严池集":{"雪中悍刀行":0,"挪威的森林":5,"平凡的世界":0,"资治通鉴":1,"情书1946":5},
"拓跋菩萨":{"雪中悍刀行":5,"挪威的森林":4,"平凡的世界":1,"资治通鉴":3,"情书1946":2},
"黄三甲":{"雪中悍刀行":5,"挪威的森林":3,"平凡的世界":1,"资治通鉴":4,"情书1946":2},
}
其中,0分代表该用户并未对这本书打分,打分取值为1、2、3、4、5。
现在你所在的公司有类似如下的场景需要解决:
根据这个数据集,为用户“徐凤年”推荐几本他应当喜欢的书。
分析应用场景的需求
为了解决上述问题,我们可以把这个需求分成两步解决。
- 首先,找到与用户“徐凤年”相似的用户。
- 然后,根据找到的相似用户,取相似用户评分高的,而“徐凤年”没有看过的推荐给他,这样,他应当会喜欢看。
开始开发推荐图书系统
常规解决想法
上面的数据看起来虽然比较整齐,但是看不出来任何特点,所以我开始尝试画个曲线图试试看,如图1:

似乎好看了一点,但是各种线都缠绕在了一起。
这只是5本书而已,随着应用场景的扩大,分析几万本书也是很有可能的,到时候几万跟曲线缠绕在一起,根本看不出什么规律。
所以我们尝试一些数据分析与挖掘的算法。
我发誓,我以前看书的时候也和大家一样,看到公式立马跳过。但是我可以保证接下来的几个公式都非常常见,而且很容易理解,而且大家在高中就都已经学过。现在正是学以致用的时候!
曼哈顿距离
【原理】
最简单的距离计算方式是曼哈顿距离。在二维模型中,每个人都可以用(x, y)的点来表示,这里我用下标来表示不同的人,(x1, y1)表示“徐凤年”,(x2, y2)表示“裴南苇”,那么他们之间的曼哈顿距离就是:![]()
在直角坐标系中,就是三角形的两条边长度之和。
如果拓展到多维模型,公式就是:
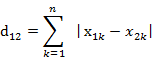
最终得出的值越小,代表两者越相似。
【实际问题分析】
对于“徐凤年”和“裴南苇”,他们对5本书的打分情况如下:
| 雪中悍刀行 | 挪威的森林 | 平凡的世界 | 资治通鉴 | 情书1946 | |
|---|---|---|---|---|---|
| 徐凤年 | 0 | 3 | 1 | 3 | 5 |
| 裴南苇 | 4 | 0 | 3 | 4 | 5 |
【注意】这里面值为0的,代表用户还没有打分,我们不应该纳入计算,因为用户如果打分,可能打1-5分,而我们用0代入计算肯定是不妥的。
试想一下,网络上假设有2000w首个,而我们每个人最多只能听1w首,而当我们计算时,如果把剩下的1900w首没听过的歌都以0值代入计算,那么得出的值会非常不准确,甚至是毫无关联。
所以,得出的曼哈顿距离为:|1-3| + |3-4| + |5-5| = 3
【JS算法代码】
/** 曼哈顿距离算法**/
let manhattan = (dataChild,dataFather) => {
let arr = [];// 用于返回距离的数组
let child = [];// 存放提取出的、被比较的子数据
let father = [];// 存放提取出的所有
/** 开始提取数据 **/
for(key in dataChild)
child.push(dataChild[key])
for(key1 in dataFather){
let arr_child = [];
for(key2 in dataFather[key1])
arr_child.push(dataFather[key1][key2])
father.push(arr_child)
}
// console.log(child,father)
/**开始计算**/
for(let i=0;i<father.length;i++){
let len = 0;
for(let j=0;j<child.length;j++){
if(child[j]!=0&&father[i][j]!=0)
len += Math.abs(child[j] - father[i][j])
}
arr.push(len);
}
return arr;
}
console.log(manhattan(dataBase["徐凤年"],dataBase));
得出的结果为:[0,3,1,11,7,9,8,4,4,4]
我们根据上述数组来作个折线图:

很容易可以看出,“曹长卿”是其他9个人里面与“徐凤年”的曼哈顿距离最小的,即他们对5本书的打分情况最相似。
欧氏距离
【原理】
也许你还隐约记得勾股定理。另一种计算距离的方式就是看两点之间的直线距离:![]()
最终得出的值越小,代表两者越相似。
【实际问题分析】
如果拓展到n维模型,同样对于下面的表:
| 雪中悍刀行 | 挪威的森林 | 平凡的世界 | 资治通鉴 | 情书1946 | |
|---|---|---|---|---|---|
| 徐凤年 | 0 | 3 | 1 | 3 | 5 |
| 裴南苇 | 4 | 0 | 3 | 4 | 5 |
对于有0值的,我们仍然不纳入计算
可以得出,欧氏距离为: Math.sqrt( (1-3)^2 + (3-4)^2 + (5-5)^2 ) = 根号5
【JS算法代码】
我们来模拟一下欧氏距离的算法:
/** 欧式距离算法**/
let euclidean = (dataChild,dataFather) => {
let arr = [];// 用于返回距离的数组
let child = [];// 存放提取出的、被比较的子数据
let father = [];// 存放提取出的所有
/** 开始提取数据 **/
for(key in dataChild)
child.push(dataChild[key])
for(key1 in dataFather){
let arr_child = [];
for(key2 in dataFather[key1])
arr_child.push(dataFather[key1][key2])
father.push(arr_child)
}
// console.log(child,father)
/**开始计算**/
for(let i=0;i<father.length;i++){
let len = 0;
for(let j=0;j<child.length;j++){
if(child[j]!=0&&father[i][j]!=0)
len += Math.pow((child[j] - father[i][j]),2)
}
arr.push(Math.sqrt(len));
}
return arr;
}
console.log(euclidean(dataBase["徐凤年"],dataBase));
得到的输出为:[0, 2.23606797749979, 13: 5.744562646538029, 4.123105625617661, 5.744562646538029 ,5.0990195135927845, 2.8284271247461903, 3.1622776601683795, 3.1622776601683795 ]
我们把数据绘制成折线图:

可以看出,与“徐凤年”喜欢相似的用户仍然是“曹长卿”。
闵可夫斯基距离
【原理】
我们可以将曼哈顿距离和欧几里得距离归纳成一个公式,这个公式称为闵可夫斯基距离:

其中:
r = 1 该公式即曼哈顿距离
r = 2 该公式即欧几里得距离
r = ∞ 极大距离
提前预告一下:r值越大,单个维度的差值大小会对整体距离有更大的影响。
【JS算法代码】
我们来模拟一下闵可夫斯基的算法:
/** 闵可夫斯基距离算法**/
let minkowski = (dataChild,dataFather) => {
let arr = [];// 用于返回距离的数组
let child = [];// 存放提取出的、被比较的子数据
let father = [];// 存放提取出的所有
/** 开始提取数据 **/
for(key in dataChild)
child.push(dataChild[key])
for(key1 in dataFather){
let arr_child = [];
for(key2 in dataFather[key1])
arr_child.push(dataFather[key1][key2])
father.push(arr_child)
}
// console.log(child,father)
/**开始计算**/
for(let i=0;i<father.length;i++){
// 计算r-即去掉等于0的组别,剩下的组数
let r = child.length;
for(let j=0;j<child.length;j++){
if(child[j]==0||father[i][j]==0)
r--;
}
let len = 0;
for(let j=0;j<child.length;j++){
if(child[j]!=0&&father[i][j]!=0)
len += Math.pow(Math.abs(child[j] - father[i][j]),r)
}
arr.push(Math.pow(len,1/r));
}
return arr;
}
console.log(minkowski(dataBase["徐凤年"],dataBase))
得出的数组为:
[0,
2.080083823051904,
1,
4.382849839122776,
3.260390438695134,
4.759149430918539,
4.287747230288912,
2.5198420997897464,
3.009216698434564,
3.009216698434564]
我们绘制成折线图:
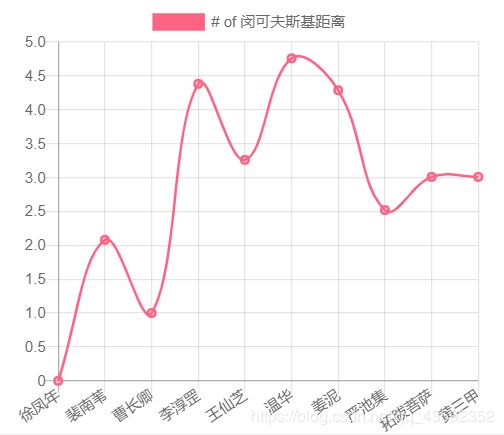
与“徐凤年”的喜好相似用户依然是“曹长卿”!
到这里,大家可以在上面的图片一览中,对比图2、图3、图4。看看他们之间的规律。我们会发现,他们的规律相似,也就是我们采用的三种算法最终指向同一种结果!
皮尔逊相关系数
我们再提出一个问题:如果一个用户A打分标准是:4分为不喜欢,5分为喜欢;用户B的打分标准为:1分为不喜欢,2分适中,3分为最喜欢。如果我们此时再用距离算法计算两者,就会不太恰当。
由于每个用户的打分标准不同,会影响推荐系统的准确性。于是我们提出皮尔逊相关系数,公式为:

这不就是高中学的回归分析里面
y = ax + b,其中a的公式嘛!
皮尔逊相关系数用于衡量两个变量之间的相关性,它的值在-1至1之间,1表示完全吻合,-1表示完全相悖。
【JS算法代码】
/** 皮尔逊相关系数算法**/
let pearson = (dataChild,dataFather) => {
let arr = [];// 用于返回距离的数组
let child = [];// 存放提取出的、被比较的子数据
let father = [];// 存放提取出的所有
/** 开始提取数据 **/
for(key in dataChild)
child.push(dataChild[key])
for(key1 in dataFather){
let arr_child = [];
for(key2 in dataFather[key1])
arr_child.push(dataFather[key1][key2])
father.push(arr_child)
}
// console.log(child,father)
/**开始计算**/
for(let i=0;i<father.length;i++){
// 计算r-即去掉等于0的组别,剩下的组数
let r = child.length;
for(let j=0;j<child.length;j++){
if(child[j]==0||father[i][j]==0)
r--;
}
// 计算x、y平均
let _x=0;
let _y = 0;
for(let j=0;j<child.length;j++)
if(child[j]!=0&&father[i][j]!=0){
_x += child[j];
_y += father[i][j];
}
_x /= r;
_y /= r;
// 计算分子
let fenzi = 0;
for(let j=0;j<child.length;j++)
if(child[j]!=0&&father[i][j]!=0){
fenzi += (child[j] - _x)*(father[i][j] - _y)
}
// 计算分母
let fenmu = 0;
let fenmux = 0;
let fenmuy = 0;
for(let j=0;j<child.length;j++)
if(child[j]!=0&&father[i][j]!=0){
fenmux += Math.pow((child[j] - _x),2);
fenmuy += Math.pow((father[i][j] - _y),2);
}
fenmu = Math.sqrt(fenmux*fenmuy)
arr.push(fenzi/fenmu);
}
return arr;
}
console.log(pearson(dataBase["徐凤年"],dataBase))
把结果绘制成折线图:
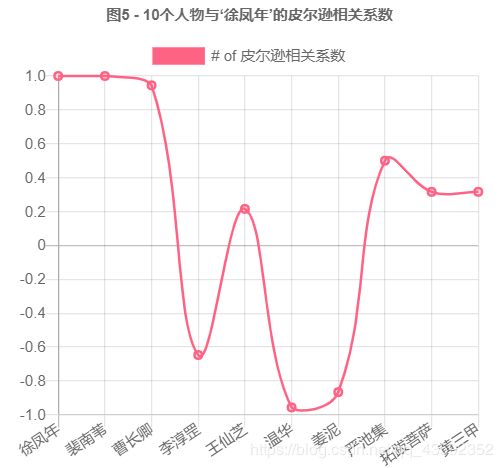
可以看出来,“裴南苇”与“曹长卿”和“徐凤年”的喜好最吻合。
余弦相似度
【原理】

其中,“·”号表示数量积。“||x||”表示向量x的模,计算公式是:

余弦相似度的范围从1到-1,1表示完全匹配,-1表示完全相悖。所以0.935表示匹配度很高。
【JS算法代码】
/** 余弦相似度算法**/
let cossimilarity = (dataChild,dataFather) => {
let arr = [];// 用于返回距离的数组
let child = [];// 存放提取出的、被比较的子数据
let father = [];// 存放提取出的所有
/** 开始提取数据 **/
for(key in dataChild)
child.push(dataChild[key])
for(key1 in dataFather){
let arr_child = [];
for(key2 in dataFather[key1])
arr_child.push(dataFather[key1][key2])
father.push(arr_child)
}
// console.log(child,father)
/**开始计算**/
for(let i=0;i<father.length;i++){
// 计算xy的和、x2的和、y2的和
let Cxy = 0;
let Cxx = 0;
let Cyy = 0;
for(let j=0;j<child.length;j++)
if(child[j]!=0&&father[i][j]!=0){
Cxy += child[j] * father[i][j];
Cxx += Math.pow(child[j],2);
Cyy += Math.pow(father[i][j],2);
}
arr.push(Cxy/(Math.sqrt(Cxx*Cyy)))
}
return arr;
}
console.log(cossimilarity(dataBase["徐凤年"],dataBase))
我们把结果绘制:
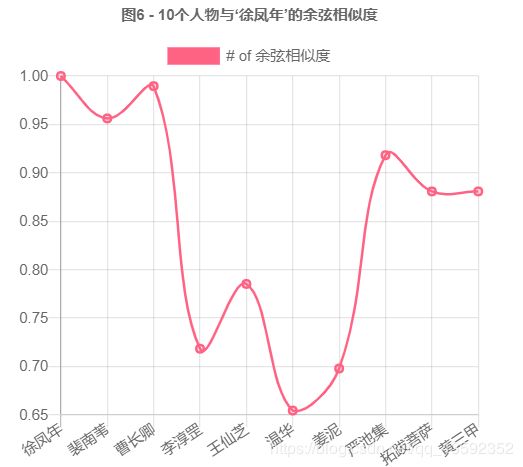
可以看出来,“曹长卿”的余弦相似度最大,与“徐凤年”最相似。
得出推荐图书
由以上5种算法,我们得出“曹长卿”是“徐凤年”的喜好相似用户。他们对图书的打分情况如下:
| 雪中悍刀行 | 挪威的森林 | 平凡的世界 | 资治通鉴 | 情书1946 | |
|---|---|---|---|---|---|
| 徐凤年 | 0 | 3 | 1 | 3 | 5 |
| 曹长卿 | 5 | 3 | 0 | 2 | 5 |
如上表,我们找一本“曹长卿”评分高,而“徐凤年”没有读过的书,推荐给“徐凤年”,他可能会喜欢。
则最终,我们给用户“徐凤年”推荐图书《雪中悍刀行》。
应该使用哪种相似度?
- 如果数据存在“分数膨胀”问题,就使用皮尔逊相关系数。
- 如果数据比较“密集”,变量之间基本都存在公有值,且这些距离数据是非常重要的,那就使用欧几里得或曼哈顿距离。
- 如果数据是稀疏的,则使用余弦相似度。
这里解释一下“分数膨胀”。形象的说,就是每个用户的评分标准不一样。系统给的标准是1-5依次递增,但是有的人认为最好的应该打4分,最差的打2分;有的人认为差的打4分,好的打5分;他们有自己的标准,而且他们的标准并不符合系统的1-5分的设定。这个时候我们就应该用皮尔逊相关系数。