学号:1600030024 姓名:王冠雄
【嵌牛导读】:现在机器学习逐渐成为行业热门,经过二十几年的发展,机器学习目前也有了十分广泛的应用,如:数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、DNA序列测序、语音和手写识别、战略游戏和机器人等方面。
【嵌牛鼻子】:开源,机器学习,用法简介
【嵌牛提问】:GitHub上最流行的机器学习项目?项目简介?
【嵌牛正文】:
1. TensorFlow
TensorFlow 是谷歌发布的第二代机器学习系统。据谷歌宣称,在部分基准测试中,TensorFlow的处理速度比第一代的DistBelief加快了2倍之多。
具体的讲,TensorFlow是一个利用数据流图(Data Flow Graphs)进行数值计算的开源软件库:图中的节点(Nodes)代表数学运算操作,同时图中的边(Edges)表示节点之间相互流通的多维数组,即张量(Tensors)。这种灵活的架构可以让使用者在多样化的将计算部署在台式机、服务器或者移动设备的一个或多个CPU上,而且无需重写代码;同时任一基于梯度的机器学习算法均可够借鉴TensorFlow的自动分化(Auto-differentiation);此外通过灵活的Python接口,要在TensorFlow中表达想法也变得更为简单。
TensorFlow最初由Google Brain小组(该小组隶属于Google’s Machine Intelligence研究机构)的研究员和工程师开发出来的,开发目的是用于进行机器学习和深度神经网络的研究。但该系统的通用性足以使其广泛用于其他计算领域。
目前Google 内部已在大量使用 AI 技术,包括 Google App 的语音识别、Gmail 的自动回复功能、Google Photos 的图片搜索等都在使用 TensorFlow 。
开发语言:C++
许可协议:Apache License 2.0
GitHub项目地址:https://github.com/tensorflow/tensorflow
2. Scikit-Learn
Scikit-Learn是用于机器学习的Python 模块,它建立在SciPy之上。该项目由David Cournapeau 于2007年创立,当时项目名为Google Summer of Code,自此之后,众多志愿者都为此做出了贡献。
主要特点:
操作简单、高效的数据挖掘和数据分析
无访问限制,在任何情况下可重新使用
建立在NumPy、SciPy 和 matplotlib基础上
Scikit-Learn的基本功能主要被分为六个部分:分类、回归、聚类、数据降维、模型选择、数据预处理,具体可以参考官方网站上的文档。经过测试,Scikit-Learn可在 Python 2.6、Python 2.7 和 Python 3.5上运行。除此之外,它也应该可在Python 3.3和Python 3.4上运行。
注:Scikit-Learn以前被称为Scikits.Learn。
开发语言:Python
许可协议:3-Clause BSD license
GitHub项目地址:https://github.com/scikit-learn/scikit-learn
3. Caffe
Caffe 是由神经网络中的表达式、速度、及模块化产生的深度学习框架。后来它通过伯克利视觉与学习中心(BVLC)和社区参与者的贡献,得以发展形成了以一个伯克利主导,然后加之Github和Caffe-users邮件所组成的一个比较松散和自由的社区。
Caffe是一个基于C++/CUDA架构框架,开发者能够利用它自由的组织网络,目前支持卷积神经网络和全连接神经网络(人工神经网络)。在Linux上,C++可以通过命令行来操作接口,对于MATLAB、Python也有专门的接口,运算上支持CPU和GPU直接无缝切换。
Caffe的特点:
易用性:Caffe的模型与相应优化都是以文本形式而非代码形式给出, Caffe给出了模型的定义、最优化设置以及预训练的权重,方便快速使用;
速度快:能够运行最棒的模型与海量的数据;
Caffe可与cuDNN结合使用,可用于测试AlexNet模型,在K40上处理一张图片只需要1.17ms;
模块化:便于扩展到新的任务和设置上;
使用者可通过Caffe提供的各层类型来定义自己的模型;
目前Caffe应用实践主要有数据整理、设计网络结构、训练结果、基于现有训练模型,使用Caffe直接识别。
开发语言:C++
许可协议: BSD 2-Clause license
GitHub项目地址:https://github.com/BVLC/caffe
4. PredictionIO
PredictionIO 是面向开发人员和数据科学家的开源机器学习服务器。它支持事件采集、算法调度、评估,以及经由REST APIs的预测结果查询。使用者可以通过PredictionIO做一些预测,比如个性化推荐、发现内容等。PredictionIO 提供20个预设算法,开发者可以直接将它们运行于自己的数据上。几乎任何应用与PredictionIO集成都可以变得更“聪明”。其主要特点如下所示:
基于已有数据可预测用户行为;
使用者可选择你自己的机器学习算法;
无需担心可扩展性,扩展性好。
PredictionIO 基于 REST API(应用程序接口)标准,不过它还包含 Ruby、Python、Scala、Java 等编程语言的 SDK(软件开发工具包)。其开发语言是Scala语言,数据库方面使用的是MongoDB数据库,计算系统采用Hadoop系统架构。
开发语言:Scala
许可协议: Apache License 2.0
GitHub项目地址:https://github.com/PredictionIO/PredictionIO
5. Brain
Brain是 JavaScript 中的 神经网络库。以下例子说明使用Brain来近似 XOR 功能:
var net = new brain.NeuralNetwork();
net.train([{input: [0, 0], output: [0]},
{input: [0, 1], output: [1]},
{input: [1, 0], output: [1]},
{input: [1, 1], output: [0]}]);
var output = net.run([1, 0]); // [0.987]
当 brain 用于节点中,可使用npm安装:
npm install brain
当 brain 用于浏览器,下载最新的 brain.js 文件。训练计算代价比较昂贵,所以应该离线训练网络(或者在 Worker 上),并使用 toFunction() 或者 toJSON()选项,以便将预训练网络插入到网站中。
开发语言:JavaScript
GitHub项目地址:https://github.com/harthur/brain
6. Keras
Keras是极其精简并高度模块化的神经网络库,在TensorFlow 或 Theano 上都能够运行,是一个高度模块化的神经网络库,支持GPU和CPU运算。Keras可以说是Python版的Torch7,对于快速构建CNN模型非常方便,同时也包含了一些最新文献的算法,比如Batch Noramlize,文档教程也很全,在官网上作者都是直接给例子浅显易懂。Keras也支持保存训练好的参数,然后加载已经训练好的参数,进行继续训练。
Keras侧重于开发快速实验,用可能最少延迟实现从理念到结果的转变,即为做好一项研究的关键。
当需要如下要求的深度学习的库时,就可以考虑使用Keras:
考虑到简单快速的原型法(通过总体模块性、精简性以及可扩展性);
同时支持卷积网络和递归网络,以及两者之间的组合;
支持任意连接方案(包括多输入多输出训练);
可在CPU 和 GPU 上无缝运行。
Keras目前支持 Python 2.7-3.5。
开发语言:Python
GitHub项目地址:https://github.com/fchollet/keras
7. CNTK
CNTK(Computational Network Toolkit )是一个统一的深度学习工具包,该工具包通过一个有向图将神经网络描述为一系列计算步骤。在有向图中,叶节点表示输入值或网络参数,其他节点表示该节点输入之上的矩阵运算。
CNTK 使得实现和组合如前馈型神经网络DNN、卷积神经网络(CNN)和循环神经网络(RNNs/LSTMs)等流行模式变得非常容易。同时它实现了跨多GPU 和服务器自动分化和并行化的随机梯度下降(SGD,误差反向传播)学习。
下图将CNTK的处理速度(每秒处理的帧数)和其他四个知名的工具包做了比较了。配置采用的是四层全连接的神经网络(参见基准测试脚本)和一个大小是8192 的高效mini batch。在相同的硬件和相应的最新公共软件版本(2015.12.3前的版本)的基础上得到如下结果:
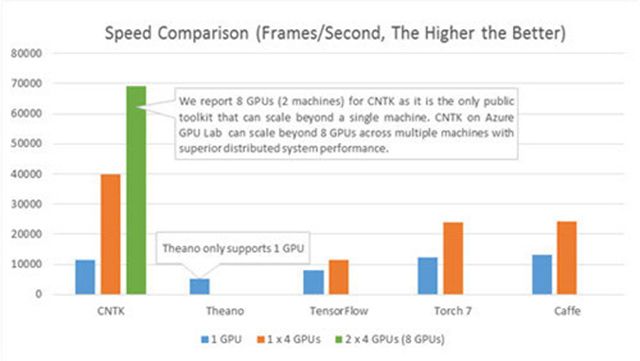
CNTK自2015年四月就已开源。
开发语言:C++
GitHub项目地址:https://github.com/Microsoft/CNTK
8. Convnetjs
ConvNetJS是利用Javascript实现的神经网络,同时还具有非常不错的基于浏览器的Demo。它最重要的用途是帮助深度学习初学者更快、更直观的理解算法。
它目前支持:
常见的神经网络模块(全连接层,非线性);
分类(SVM/ SOFTMAX)和回归(L2)的成本函数;
指定和训练图像处理的卷积网络;
基于Deep Q Learning的实验强化学习模型。
一些在线示例:
Convolutional Neural Network on MNIST digits
Convolutional Neural Network on CIFAR-10
Toy 2D data
Toy 1D regression
Training an Autoencoder on MNIST digits
Deep Q Learning Reinforcement Learning demo + Image Regression (“Painting”) + Comparison of SGD/Adagrad/Adadelta on MNIST
其他:
开发语言:Javascript
许可协议:MIT License
GitHub项目地址:https://github.com/karpathy/convnetjs
9. Pattern

Pattern是Python的一个Web挖掘模块。拥有以下工具:
数据挖掘:网络服务(Google、Twitter、Wikipedia)、网络爬虫、HTML DOM解析;
自然语言处理:词性标注工具(Part-Of-Speech Tagger)、N元搜索(n-gram search)、情感分析(sentiment analysis)、WordNet;
机器学习:向量空间模型、聚类、分类(KNN、SVM、 Perceptron);
网络分析:图形中心性和可视化。
其文档完善,目前拥有50多个案例和350多个单元测试。 Pattern目前只支持Python 2.5+(尚不支持Python 3),该模块除了在Pattern.vector模块中使用LSA外没有其他任何外部要求,因此只需安装 NumPy (仅在Mac OS X上默认安装)。
开发语言:Python
许可协议:BSD license
GitHub项目地址:https://github.com/clips/pattern