MapReduce>分布式计算框架MapReduce(A)
文章目录
- 分布式并行计算框架MapReduce
- Hadoop为什么比传统技术方案快?
- 理解MapReduce思想
- MapReduce并行计算
- Hadoop -MapReduce设计构思
- MapReduce编程初体验
- hadoop数据类型
- MapReduce编程规范及示例编写
- Map阶段2个步骤
- shuffle阶段4个步骤(可以全部不用管)
- Shuffle阶段的Partition分区算法
- reduce阶段2个步骤
- Mapper以及Reducer抽象类介绍
- 1、Mapper抽象类的基本介绍
- 2、Reducer抽象类基本介绍
- MapReduce程序运行模式
- 本地模式运行代码设置
- 集群运行模式
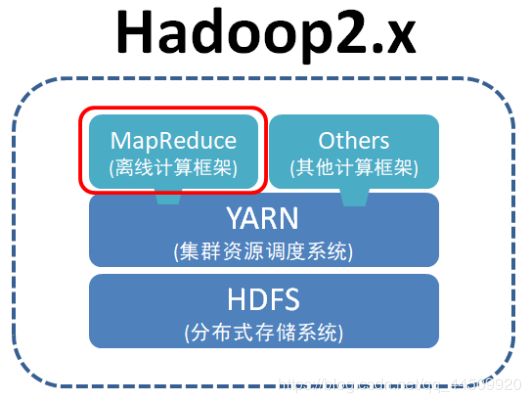
Hadoop组成
- Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统,对海量数据的存储。
- Hadoop MapReduce:一个分布式的资源调度和离线并行计算框架。
- Hadoop Yarn:基于HDFS,用于作业调度和集群资源管理的框架。
分布式并行计算框架MapReduce
- 什么是计算框架?
是指实现某项任务或某项工作从开始到结束的计算过程或流的结构。用于去解决或者处理某个复杂的计算问题
- 什么是并行计算框架?
是指为更快的计算某项任务或某项工作,将计算程序分发到多台服务器上,使每个服务器计算总任务的一部分,多台服务器同时计算的框架。
总结:(一个大的任务拆分成多个小任务,将多个小任务分发到多个节点上。每个节点同时执行计算)
- 什么是分布式计算?
分布式计算:是一种计算方法,是将该应用分解成许多小的部分,分配给多台计算机进行处理。这样可以节约整体计算时间,大大提高计算效率。

Hadoop为什么比传统技术方案快?
核心原因一:使用分布式存储。
核心原因二:使用分布式并行计算框架。
原因 三:节点横向扩展
原因 四:移动程序到数据端
原因 五:多个数据副本
理解MapReduce思想
-
需求:有一个五层的图书馆,需要获取图书馆中一共有多少本书。
只有一个人时,是能一本一本的数!工作量巨大,耗时较长。- 分配五个人由你支配。此时你怎么支配?
五个人,每个人数一层的书量,最终将五个人的量汇总求和,就是图书馆中最终书的数量。
- 分配五个人由你支配。此时你怎么支配?
-
MapReduce核心思想
“分而治之,先分后合”。即将一个大的、复杂的工作或任务,拆分成多个小的任务,并行处理,最终进行合并。 -
MapReduce由两部分组成,分别是Map 和Reduce两部分。
- Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以
并行计算,彼此间几乎没有依赖关系。例如前面例子中的分配每个人数一层楼。 - Reduce负责“合”,即对map阶段的结果进行
全局汇总。例如前面例子中将五个人的结果汇总。
- Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以
这两个阶段合起来正是MapReduce思想的体现。
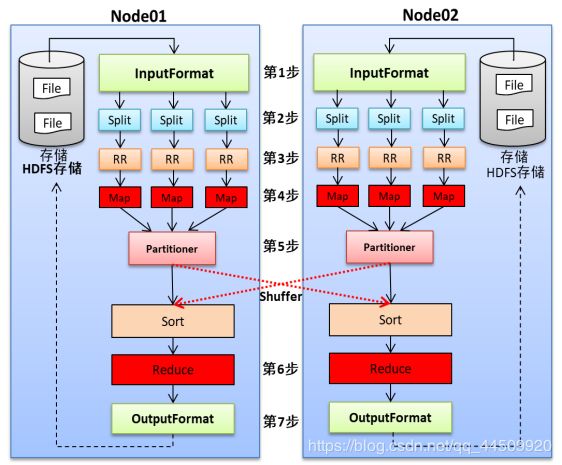
MapReduce并行计算
HDFS存储数据时对大于128M的数据会进行数据切分,每128M一个数据块,数据块会分散、分布存储到HDFS。
MapReduce在进行计算前会复制计算程序,每个数据块会分配一个独立的计算程序副本(MapTack)。计算时多个数据块几乎同时被读取并计算,但是计算程序完全相同。最终将各个计算程序计算的结果进行汇总(Reduce来汇总)

Hadoop -MapReduce设计构思
MapReduce是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在Hadoop集群上。
既然是做计算的框架,那么表现形式就是有个输入(input),MapReduce操作这个输入(input),通过本身定义好的计算模型,得到一个输出(output)。
Hadoop MapReduce构思体现在如下的三个方面:
-
如何应对大数据处理:
分而治之
对相互间不具有计算依赖关系的大数据,实现并行最自然的办法就是采取分而治之的策略。并行计算的第一个重要问题是如何划分计算任务或者计算数据以便对划分的子任务或数据块同时进行计算。不可分拆的计算任务或相互间有依赖关系的数据无法进行并行计算! -
构建抽象模型:Map和Reduce
MapReduce借鉴了函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型。
Map: 对一组数据元素进行某种重复式的处理;
Reduce: 对Map的中间结果进行某种进一步的结果整理。
MapReduce中定义了如下的Map和Reduce两个抽象的编程接口,由用户去编程实现:
map: [k1,v1] → [(k2,v2)]
reduce: [k2, {v2,…}] → [k3, v3]
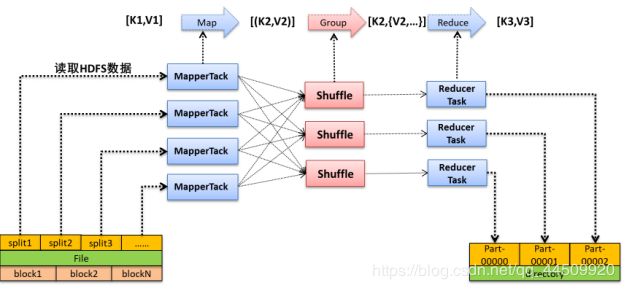
WordCount体现每个KeyValue
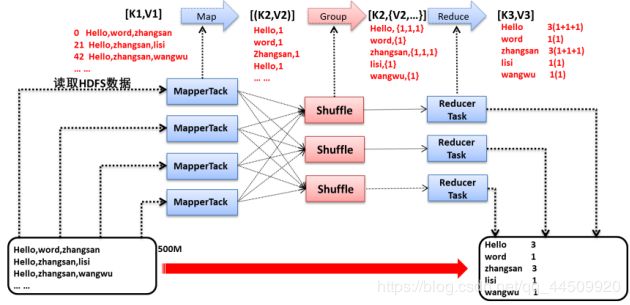
Map和Reduce为程序员提供了一个清晰的操作接口抽象描述。通过以上两个编程接口,大家可以看出MapReduce处理的数据类型是。 -
统一构架,隐藏系统层细节
- 如何提供统一的计算框架,如果没有统一封装底层细节,那么程序员则需要考虑诸如数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统层面的处理细节。
- MapReduce最大的亮点在于通过抽象模型和计算框架把需要做什么(what need to do)与具体怎么做(how to do)分开了,为程序员提供一个抽象和高层的编程接口和框架。
程序员仅需要关心其应用层的具体计算问题,仅需编写少量的处理应用本身计算问题的程序代码。如何具体完成这个并行计算任务所相关的诸多系统层细节被隐藏起来,交给计算框架去处理:从分布代码的执行,到大到数千小到单个节点集群的自动调度使用
MapReduce编程初体验
需求:在给定的文本文件中统计输出每一个单词出现的总次数
数据格式准备如下:
[root@node01 ~]# cd /export/servers
[root@node01 servers]# vim wordcount.txt
# wordcount.txt 写入以下数据
hello,world,hadoop
hello,hive,sqoop,flume
kitty,tom,jerry,world
hadoop
hdfs dfs -mkdir /wordcount/
hdfs dfs -put wordcount.txt /wordcount/
- 项目POM文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.itcast</groupId>
<artifactId>mapreduce</artifactId>
<version>1.0-SNAPSHOT</version>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-client</artifactId>
<version>2.6.0-mr1-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-common</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-hdfs</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-mapreduce-client-core</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
hadoop数据类型
`java : string int long double float boolean`
`hadoop : Text IntWritable LongWritable DoubleWritable FloatWritable BooleanWritable`
偏移量
每个字符移动到当前文档的最前面需要移动的字符个数。
- 定义一个mapper类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//A、实例一个class 继承Mapper<输入key/value的数据类型,输出key/value的数据类型>
public class WordCount_Mapper extends Mapper<LongWritable,Text,Text,LongWritable> {
//B、重写map方法 map
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//key:行首字母的偏移量
//value:一行数据
//context:上下文对象
//1 将text类型的value 转换成string
String line = value.toString();
//2 使用spline对数据进行切分
String[] split = line.split(",");
//3 遍历每一个单词,进行输出(一个单词输出一次)
for (String word : split) {
//context 上下文对象 输出数据word
context.write(new Text(word),new LongWritable(1));
}
}
}
- 定义一个reducer类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//A、实例一个class 继承Reducer<输入的key/value的数据类型,输出的key/value的数据类型>
public class WordCount_Reducer extends Reducer<Text,LongWritable,Text,LongWritable> {
/**
* 自定义reduce逻辑
* @param key 所有的key都是去重后的单词
* @param values 所有的values都是单词出现的次数
* @param context 上下文对象
*/
//B、重写reduce方法 reduce
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//求和
long sum= 0;
//遍历values 进行汇总计算
for (LongWritable value : values) {
sum+= value.get();
}
//将结果输出
context.write(key,new LongWritable(sum));
}
}
- 定义一个主类,用来描述job并提交job
//A、实例一个class 继承Configured 实现Tool
public class WordCount_Driver extends Configured implements Tool {
//B、重写run方法
@Override
public int run(String[] args) throws Exception {
//C、将自己的Map Reduce代码添加到框架中
//1 实例一个Job
Job job =Job.getInstance(new Configuration(),"随便起名");
`//打包代码到集群运行`
job.setJarByClass(WordCount_Driver.class);
//2 设置读取输入文件解析成key,value对
job.setInputFormatClass(TextInputFormat.class);
//设置读取数据的路径
TextInputFormat.addInputPath(job,new
Path("hdfs://192.168.100.201:8020/wordcount"));
//3 设置Map类
job.setMapperClass(WordCount_Mapper.class);
//设置map阶段完成之后`输出的 类型` K,V
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//4 设置reduce类
job.setReducerClass(WordCount_Reducer.class);
//设置reduce阶段完成之后`输 出的类型` K,V
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//5设置输出数据的class
job.setOutputFormatClass(TextOutputFormat.class);
//设置输出数据的路径
TextOutputFormat.setOutputPath(job,new
Path("/wordcount_out"));
#Path("hdfs://192.168.100.201:8020/wordcount_out"));
//6 等待代码执行(返回状态码)
return job.waitForCompletion(true)?0:1;
# boolean b = job.waitForCompletion(true);
# return b?0:1;
`//Map的数量不能人为设置,reduce的数量可以人为设置
//reduce数量越多,计算速度越快。`
job.setNumReduceTasks(3);
`combiner的添加:在map端局部聚和,设置reduce的class`
#job.setCombinerClass(WordCount_Reducer.class);
}
/**
* 程序main函数的入口类
*/
public static void main(String[] args) throws Exception {
//调用执行方法
Configuration configuration = new Configuration();
Tool tool = new WordCount_Driver();
int run = ToolRunner.run(configuration, tool, args);
System.exit(run);
#直接执行该方法
# ToolRunner.run(new WordCount_Driver(),args)
Map的`输出`是: key value 的 list
reduce的`输入`是:key value 的 list
}
}
错误提醒:如果遇到这个错误
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException):
Permission denied: user=admin, access=WRITE, inode="/":root:supergroup:drwxr-xr-x
直接将hdfs-site.xml当中的权限关闭即可
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
重启hdfs集群,重新运行
代码编写完毕后,将代码打成jar包放到服务器上去运行(开发main方法作为程序的入口)
运行命令如下
hadoop jar hadoop_hdfs_operate-1.0-SNAPSHOT.jar cn.itcast.hdfs.demo1.WordCount_Driver
运行过程
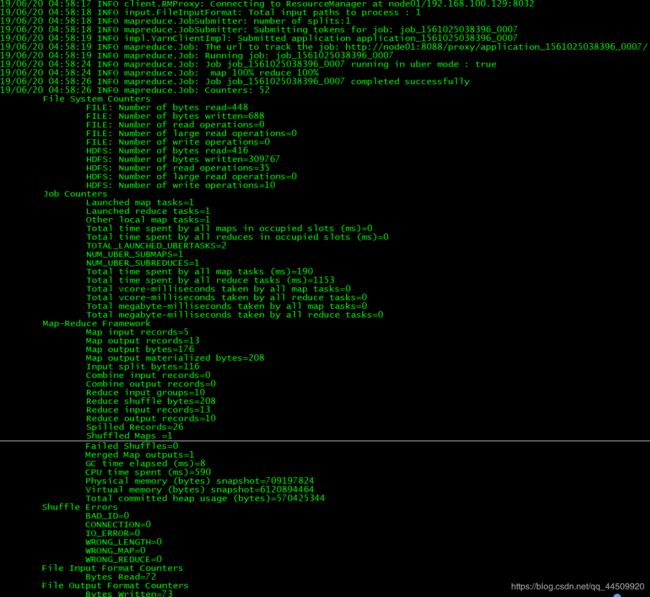
运行结果
node01服务器操作
#jps查看 node01 服务器是否开启
[root@node01 ~]# jps
4800 NodeManager
4289 NameNode
4705 ResourceManager
4563 SecondaryNameNode
4413 DataNode
33198 Jps
[root@node01 /]# hadoop fs -ls /
Found 6 items 查看HDFS 是否已存在该文件 (存在删除)
-rw-r--r-- 2 root supergroup 71 2019-10-30 05:00 /aaaa
[root@node01 /]# hadoop fs -rmr /aaaa
# 在该目录下创建文本
[root@node01 /]# cd /opt/
[root@node01 opt]# vi c.txt
hello,world,hadoop
hive,sqoop,flume,hello
kitty,tom,jerry,world
hadoop
#上传到HDFS集群
[root@node01 opt]# hadoop fs -put c.txt /aaaa
#查看集群信息
[root@node01 opt]# hadoop fs -cat /aaaa
hello,world,hadoop
hive,sqoop,flume,hello
kitty,tom,jerry,world
hadoop
# 打包代码到集群运行
[root@node01 opt]# rz
rz waiting to receive.
zmodem trl+C ȡ
100% 25984 KB 25984 KB/s 00:00:01 0 Errors...
100% 15 KB 15 KB/s 00:00:01 0 Errors
[root@node01 opt]# ll
-rw-r--r-- 1 root root 26607868 11月 14 2019 demo01-1.0-SNAPSHOT.jar
-rw-r--r-- 1 root root 16019 11月 14 2019 original-demo01-1.0-SNAPSHOT
# Hadoop运行jar命令 (包名.类名)
[root@node01 opt]# hadoop jar demo01-1.0-SNAPSHOT.jar day04.WordCount_Driver
[root@node01 opt]# hadoop fs -ls /wordcount_out
Found 4 items
-rw-r--r-- 2 root supergroup 0 2019-10-30 05:22 /wordcount_out/_SUCCESS
-rw-r--r-- 2 root supergroup 7 2019-10-30 05:21 /wordcount_out/part-r-00000
-rw-r--r-- 2 root supergroup 31 2019-10-30 05:21 /wordcount_out/part-r-00001
-rw-r--r-- 2 root supergroup 32 2019-10-30 05:22 /wordcount_out/part-r-00002
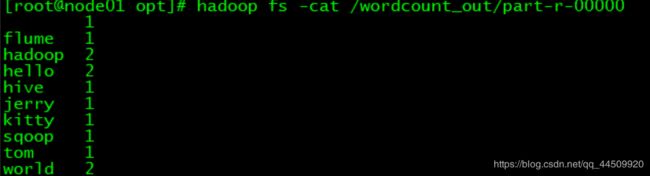
[root@node01 opt]# hadoop fs -cat /wordcount_out/part-r-00000
hive 1
flume 1
hadoop 2
MapReduce编程规范及示例编写
编程规范
mapReduce编程模型的总结
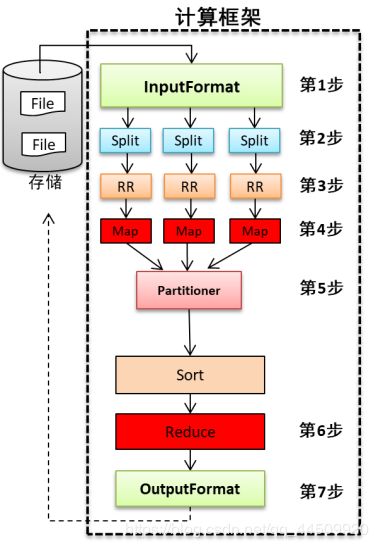
- 事实上MapReduce的开发一共有八个步骤其中map阶段分为2个步骤,shuffle阶段4个步骤,reduce阶段分为2个步骤
Map阶段2个步骤
- 第一步:设置inputFormat类,将数据切分成key,value对,输入到第二步
- 第二步:自定义map逻辑,处理第一步的输入数据,然后转换成新的key,value对进行输出
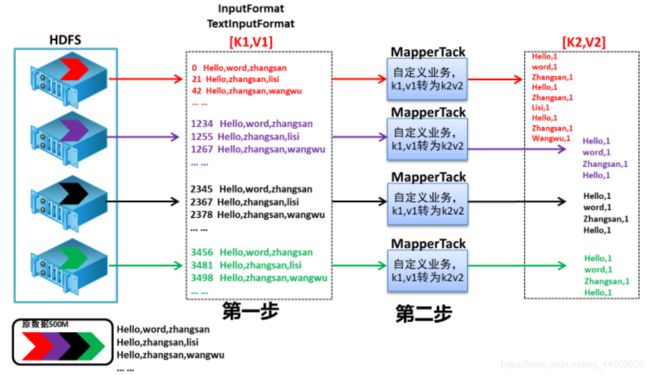
shuffle阶段4个步骤(可以全部不用管)
- 第三步:对输出的key,value对进行分区(Partition)。相同key的数据发送到同一个reduce里面去,相同key合并,value形成一个集合
- 第四步:对不同分区的数据按照相同的key进行排序
- 第五步:对分组后的数据进行规约(combine操作),降低数据的网络拷贝(可选步骤)
- 第六步:对排序后的额数据进行分组,分组的过程中,将相同key的value放到一个集合当中

Shuffle阶段的Partition分区算法
-
算法:对key 进行哈希,获取到一个哈希值,用这个哈希值与reducetask的数量取余。余几,这个数据就放在余数编 号的partition中
-
Shuffle(混洗)
shuffle `输入`是:key value的 list
shuffle `输出`是:key value的list
reduce阶段2个步骤
- 第七步:对多个map的任务进行合并,排序,写reduce函数自己的逻辑,对输入的key,value对进行处理,转换成新的key,value对进行输出
- 第八步:设置outputformat将输出的key,value对数据进行保存到文件中

八个步骤总体流程
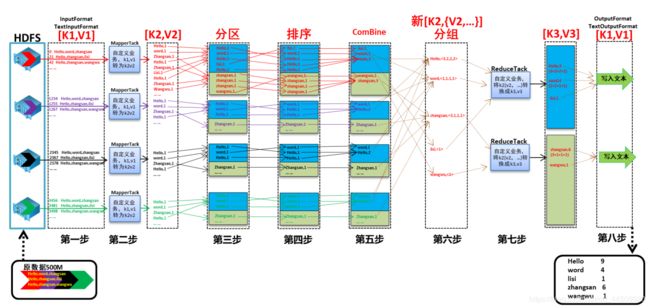
- MapReduce计算任务的步骤(全过程)
第1步:InputFormat
InputFormat 到hdfs上读取数据
将数据传给Split
第2步:Split
Split将数据进行逻辑切分,
将数据传给RR
第3步:RR
RR:将传入的数据转换成一行一行的数据,输出行首字母偏移量和偏移量对应的数据
将数据传给MAP
第4步:MAP
MAP:根据业务需求实现自定义代码
将数据传给Shuffle的partition
第5步:partition
partition:按照一定的分区规则,将key value的list进行分区。
将数据传给Shuffle的Sort
第6步:Sort
Sort:对分区内的数据进行排序
将数据传给Shuffle的combiner
第7步:combiner
combiner:对数据进行局部聚合。
将数据传给Shuffle的Group
第8步:Group
Group:将相同key的key提取出来作为唯一的key,
将相同key对应的value获取出来作为value的list
将数据传给Reduce
第9步:Reduce
Reduce:根据业务需求进行最终的合并汇总。
将数据传给outputFormat
第10步:outputFormat
outputFormat:将数据写入HDFS
Mapper以及Reducer抽象类介绍
为了开发MapReduce程序,一共可以分为以上八个步骤,其中每个步骤都是一个class类,通过job对象将程序组装成一个任务提交即可。为了简化MapReduce程序的开发,每一个步骤的class类,都有一个既定的父类,直接继承即可,因此可以大大简化MapReduce程序的开发难度,也可以快速的实现功能开发。
MapReduce编程当中,其中最重要的两个步骤就是Mapper类和Reducer类
1、Mapper抽象类的基本介绍
在hadoop2.x当中Mapper类是一个抽象类,工程师只需要覆写一个java类,继承自Mapper类即可,然后重写里面的一些方法,就可以实现特定的功能,接下来介绍一下Mapper类当中比较重要的四个方法
-
1、setup方法:
Mapper类当中的初始化方法,程序中一些对象的初始化工作都可以放到这个方法里面来实现 -
2、map方法:
读取的每一行数据,都会来调用一次map方法,这个方法也是最重要的方法,可以通过这个方法来实现每一条数据的处理。 -
3、cleanup方法:
在整个maptask执行完成之后,会马上调用cleanup方法,这个方法主要是做一些清理工作,例如连接的断开,资源的关闭等等 -
4、run方法:
如果需要更精细的控制整个MapTask的执行,那么可以覆写这个方法,实现对所有的MapTask更精确的操作控制
2、Reducer抽象类基本介绍
同样的道理,在hadoop2.x当中,reducer类也是一个抽象类,抽象类允许工程师可以继承这个抽象类之后,重新覆写抽象类当中的方法,实现逻辑的自定义控制。接下来也来介绍一下Reducer抽象类当中的四个抽象方法
- 1、setup方法:
在ReduceTask初始化之后马上调用,一些对象的初始化工作,可以在这个类当中实现 - 2、reduce方法:
所有从MapTask发送过来的数据,都会调用reduce方法,这个方法也是reduce当中最重要的方法,可以通过这个方法实现数据的处理 - 3、cleanup方法:
在整个ReduceTask执行完成之后,会马上调用cleanup方法,这个方法主要就是在reduce阶段做一些清理工作,例如连接的断开,资源的关闭等等 - 4、run方法:
如果需要更精细的控制整个ReduceTask的执行,那么可以覆写这个方法,实现对所有的ReduceTask更精确的操作控制
MapReduce程序运行模式
本地运行模式
- (1)MapReduce程序是被提交给 WordCount_Driver 在本地以单进程的形式运行
- (2)而处理的数据及输出结果可以在本地文件系统,也可以在hdfs上
- (3)怎样实现本地运行?写一个程序,不要带集群的配置文件
本质是程序的conf中是否有mapreduce.framework.name=local以及yarn.resourcemanager.hostname=local参数 - (4)本地模式非常便于进行业务逻辑的debug,只要在eclipse中打断点即可
本地模式运行代码设置
WordCount_Driver类
方式一
#Configuration conf=new Configuration();
#conf.set("mapreduce.framework.name","local");
#conf.set("yarn.resourcemanager.hostname","local");
//方式二:实例一个Job(推荐)
Job job=Job.getInstance(new Configuration(),"随便起名");
//2设置读取数据的class
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("E:\\wordcount\\input\\a.txt"));
//5 设置输出数据的class 设置输出数据的路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("F:\\wordcount\\output"));
集群运行模式
(1)将MapReduce程序提交给yarn集群,分发到很多的节点上并发执行
(2)处理的数据和输出结果应该位于hdfs文件系统
(3)提交集群的实现步骤:
将程序打成JAR包,然后在集群的任意一个节点上用hadoop命令启动
hadoop jar hadoop_hdfs_operate-1.0-SNAPSHOT.jar cn.itcast.hdfs.demo1.WordCount_Driver
打包代码到集群运行
#在代码中添加
`打包代码到集群运行`
job.setJarByClass(WordCount_Driver.class);
//2设置读取数据的class
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://192.168.100.201:8020/wordcount/a.txt"));
//5 设置输出数据的class 设置输出数据的路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("/wordcount_out"));
#Path("hdfs://192.168.100.201:8020/wordcount_out"));
`//Map的数量不能人为设置,reduce的数量可以人为设置
reduce数量越多,计算速度越快。`
job.setNumReduceTasks(3);
`combiner的添加:在map端局部聚和,设置reduce的class`
job.setCombinerClass(WordCount_Reducer.class);
-
MapReduce程序的输入:
若是一个路径,那么程序会计算路径下的所有文件。
若是一个文件,那么只计算这个文件。 -
MapReduce程序的输出:
输出的路径必须不能存在 -
Combiner的添加 在map端局部聚和,设置reduce的class
job.setCombinerClass(WordCount_Reduce.class); -
Map的数量不能人为设置,reduce的数量可以人为设置。
reduce数量越多,计算速度越快。
job.setNumReduceTasks(3);
