【编译原理】实验三:预测分析表的自动生成
C语言实现预测分析表的自动生成
- 1 实验目的
- 2 实验内容
- 2.1 书中文法例题
- 2.2 自定义文法
- 2.3 文件格式要求
- 3 开发环境
- 4 主要数据结构
- 4.1 字符串数组productions
- 4.2 终结符表Table_VT和非终结符表Table_VN
- 4.3 1.4.3 LL(1)分析表矩阵Table_LL_1
- 4.4 结构体Pro_split
- 4.5 结构体First_result
- 4.6 结构体First
- 4.7 结构体Follow
- 5 实验步骤
- 5.1 分析与设计
- 5.1.1 LL(1)文法定义与要求
- (1)LL(1)文法的定义
- (2)LL(1)文法的要求
- 5.1.2 FIRST集的构造规则
- 5.1.3 FOLLOW集的构造规则
- 5.1.4 LL(1)预测分析表的建立步骤
- 5.2 分析预期结果
- 5.2.1 书中例题
- (1)FIRST集
- (2)FOLLOW集
- (3)LL(1)分析表
- 5.2.2 自定义例题
- 关于构造FIRST遇到 A → ε A→\varepsilon A→ε的问题
- 前提
- 冲鸭
- 5.3 编程
- 5.3.1 分析表预处理
- 预处理(1)
- 预处理(2)
- 预处理(3)
- 5.3.2 FIRST集构造
- 5.3.3 FOLLOW集构造
- 5.3.4 LL(1)分析表构造
- 5.3.5 结果打印
- 5.4 运行与调试
- 6 运行结果截图
- 6.1 对例题文法的分析
- 6.2 对自定义文法的分析
- 6.3 结果分析
- 6.4 实验五预备
- 7 所遇问题与解决方法
- 7.1 关于非终结符和终结符
- 7.2 关于FIRST集
- 7.3 关于FOLLOW集
- 7.4 为什么针对FIRST集和FOLLOW集分为初步构造和进一步构造
- 7.5 关于空字符
- 7.6 关于LL(1)分析表
- 7.7 警告:C6386
- 8 心得体会
- 9 完整代码
1 实验目的
掌握LL(1)预测分析法的基本分析原理,理解并实现FIRST集、FOLLOW集,并构造LL(1)预测分析表。
2 实验内容
实验要求:程序实现给定文法的预测分析表。
(1)输入:某一文法(可以使用书中的例题)
(2)输出:该文法对应的LL(1)分析表
难点在于如何迭代计算first和follow集合,及分析表对应的数据结构。
2.1 书中文法例题

用书中的例题做初步的调试验证,测试程序是否基本正确。
2.2 自定义文法
由于书中的例题没有完全体现FIRST集、FOLLOW集的构造规则,因此自定义文法进行完全测试。
【注意】当时写这个实验的时候,FIRST集构造的理解有一点小问题,临考才恍然大悟。所以关于这个文法的分析表,可能存在问题,也可能无。

2.3 文件格式要求
(1)产生式必须合并,且分隔符为|,分隔符不算终结符;
(2)文法已经了消除左递归和回溯;
(3)非终结符为大写字母,允许加一个’;
(4)e表示空字符,字母e不算作终结符;
(5)最后一个产生式的末尾必须有换行,即\n;
3 开发环境
windows 10
visual studio2019
4 主要数据结构
在介绍数据结构的同时,可能会粗略介绍FIRST集和FOLLOW集的构造规则,具体介绍见 5 实验步骤。
4.1 字符串数组productions
c语言中,没有string类型的字符串变量,因此创建字符类型的二维数组用于存放字符串。productions中以字符串的形式,按行存放每一条产生式。
经产生式预处理后,productions中的每一条产生式后没有换行符’\n’,根据分隔符’|’进行切割,且新生成的产生式按对原产生式的处理顺序,依次存放在原产生式之后。
4.2 终结符表Table_VT和非终结符表Table_VN
Table_VT为字符类型的一维数组,一个字符一个字符地存放文法中所有出现过的终结符。并设计int类型变量count_Table_VT记录数组元素个数。
Table_VN为字符类型的二维数组,因为允许非终结符带一个撇,比如A’这种形式,因此需要以字符串类型进行存取,设计非终结符的长度为VN_CHAR_SIZE。并通过int类型变量count_Table_VN记录数组元素个数。
4.3 1.4.3 LL(1)分析表矩阵Table_LL_1
Table_LL_1为int类型的二维数组,存放以非终结符为行、以终结符为列对应的产生式在字符串数组productions中的位置。
4.4 结构体Pro_split
productions数组中的产生式,其本身以字符串形式存储,之后的FIRST集和FOLLOW集如果直接根据productions中的字符串进行构造,工作量繁琐:因为终结符和非终结符的类型不同,且有分隔符、箭头标识“->”的影响。因此需要对每一条产生式的左部和右部进行分割,并且剔除分隔符、箭头标识等,将数据结果存放在Pro_split结构体类型的pro_split数组中。
由于char类型的数组变量在处理时很麻烦,比如一条产生式的右部如果既有终结符和非终结符,而终结符和非终结符的类型不同,char类型的数组存放产生式右部就会出现问题:(1)无法存放带’的非终结符;(2)FIRST集和FOLLOW集构造时检索非终结符和终结符的过程会变得很麻烦。因此,对于终结符和非终结符,在实际处理过程中,用它们在各自的字符表中的位置代替,从而方便检索和处理。
结构体具体项目如下:
/*****************************************************************************
*结构体:Pro_split
*变量:pro_split
*存储信息:分开存放每个产生式的左部和右部
*****************************************************************************/
struct Pro_split{ //产生式
int pro_pos_left; //左部非终结符在非终结符表中的位置
_Bool pro_has_epsilon; //是否有空字符
int pro_pos_right[MAXSIZE]; //右部字符在非终结符表/终结符表中的位置
int pro_isVN_right[MAXSIZE]; //区分右部字符是非终结符还是终结符
int pro_pos_first_right_VN; //指向当前产生式右部第一个未分析的非终结符
int pro_pos_seperation[MAXSIZE]; //指明分割符所在位置
}pro_split[MAXSIZE];
其中,pro_pos_seperation变量是为了productions中的产生式依次进行分割预处理,得到新的字符串顺序存放在productions中。
4.5 结构体First_result
如果同一个非终结符对应多条产生式,那么在构建LL(1)预测分析表时,需要根据FIRST集中的每一个终结符,选取它们对应所在的产生式填入分析表中的相应位置。如果仅靠给每一个FIRST集创建一个int类型数组来存放集中的终结符在终结符表中的位置,那么如何根据终结符来找寻对应的产生式将成为一个复杂的过程。并且在中间处理某个FIRST集FIRST(A)时,FIRST(A)可以还包含其他非终结符的FIRST集FIRST(B)等,FIRST(A)中还会存在FIRST(B)中的终结符,造成了产生式检索的困难。
比如A->a|Bc,B->b,FIRST(A)包含FIRST(B)/{ε},那么FRIST(A)中含有b,根据b这个终结符需要找到A->Bc这条产生式,需要先找到非终结符B,再根据B找到A->Bc,造成了二级检索,十分麻烦。
因此建立First_result结构体,将FIRST构造过程中得到的终结符和其他待分析的非终结符,与它们所在的产生式的位置对应起来。当进行其他非终结符的分析时,只改变First_result结构体中first_result_pos_char中的值,而不改变产生式的位置first_result_pos_pro。
结构体具体项目如下:
/*****************************************************************************
*结构体:First_result
*变量:first_result_VT first_temp_analysis_VN
*存储信息:存放FIRST集中的终结符在终结符表中的位置,和其对应的产生式的位置
*****************************************************************************/
struct First_result { //分析结果
int first_result_pos_char; //FIRST集中字符在终结符表/非终结符表中的位置
int first_result_pos_pro; //FIRST集中字符对应的产生式位置
};
4.6 结构体First
创建First结构体类型的数组first,存放每一个非终结符对应的FIRST集结果。实际分析中,根据FIRST集的构造规则,可能出现空字符、终结符和非终结符等中间结果。其中,终结符直接填入相应的FIRST集比如FIRST(A)中;而出现其他非终结符比如B,需要对FIRST(B)进行分析,那么就要暂存非终结符B;当出现空字符ε时,需要对A当前对应的产生式右部紧接着B的字符进行判断。所以分别建立终结符结果集first_result_V和待分析的非终结符结果集first_result_other_VN是有必要的,为了方便,单独设置空字符ε判断位first_has_epsilon。
而一个非终结符对应的产生式可能有多条,此时可能出现多个待分析的非终结符:类似于对A->BCa|Db的分析,FIRST(A)还包含FIRST(B)和FIRST(D)的分析结果。设置first_count_other_VN记录当前待分析的非终结符个数。
设置first_success位判断当前FIRST集是否已完全分析完。
结构体具体项目如下:
/*****************************************************************************
*结构体:First
*变量:first
*存储信息:构造FIRST集
*****************************************************************************/
struct First { //构造FIRST集
int first_pos_VN; //非终结符在非终结符表中的位置
_Bool first_has_epsilon; //是否含有空字符
struct First_result first_result_VT[MAXSIZE]; //FIRST(非终结符)的分析结果
int first_count_VT; //FIRST集中包含的终结符总数
struct First_result first_result_other_VN[MAXSIZE]; //FIRST集中包含的其他待分析非终结符
int first_count_other_VN; //FIRST集中包含的其他待分析非终结符总数
_Bool first_success; //first集是否构造完成
}first[MAXSIZE];
4.7 结构体Follow
创建Follow结构体类型的数组follow,存放每一个非终结符对应的FOLLOW集结果。与FIRST集相类似,在对某一个终结符进行FOLLOW集构造的时候,比如构造FOLLOW(A),中间的分析结果可能是终结符、非终结符B或是空字符ε的一种。
当中间分析结果为非终结符B时,如果是需要添加FIRST(B)/{ε},由于FIRST集在FOLLOW集构造之前就构造完成,那么直接添加结果到FOLLOW(A)中;如果是空字符或是达到产生式末尾,需要添加FOLLOW(B)时,此时要暂存B在follow_pos_VN_next中,以便完成对FOLLOW(B)的构造后,将FOLLOW(B)加入FOLLOW(A)。
同样地,同一个非终结符对应的产生式可能不止一条,所以待分析的其他非终结符不止一个,设置follow_count_VN_next记录当前待分析的非终结符个数。
设置follow_success标志位,判断FOLLOW集是否完成了对所有中间结果的分析。
结构体具体项目如下:
/*****************************************************************************
*结构体:Follow
*变量:follow
*存储信息:构造FOLLOW集
*****************************************************************************/
struct Follow { //构造FOLLOW集
int follow_pos_VN; //非终结符在非终结符表中的位置
int follow_pos_VT[MAXSIZE]; //终结符在终结符表中的位置
int follow_count_VT; //FOLLOW集中终结符总数
int follow_pos_VN_next[MAXSIZE]; //follow(follow_VN)包含的下一个follow(follow_VN_next)
int follow_count_VN_next; //包含的follow集总数
_Bool follow_success; //分析成功标志
}follow[MAXSIZE];
5 实验步骤
5.1 分析与设计
5.1.1 LL(1)文法定义与要求
(1)LL(1)文法的定义
LL(1)文法:分析表M不含多重定义入口的文法G[S],它所定义的语言恰好就是它的分析表所能识别的全部句子。
(2)LL(1)文法的要求
(1)文法不含左递归(直接或间接);
(1)对于文法中每一个非终结符A的各个产生式的候选符首符集两两不相交,避免在分析表的同一栏目内出现多个产生式的情况。
即,若 A → α 1 ∣ α 2 ∣ … ∣ α n A→α_1|α_2|…|α_n A→α1∣α2∣…∣αn
F I R S T ( α i ) ∩ F I R S T ( α j ) = ∅ ( i = 1 , 2 , ⋯ , n 且 i ≠ j ) FIRST(α_i )∩FIRST(α_j )=∅(i=1,2,⋯,n且i≠j) FIRST(αi)∩FIRST(αj)=∅(i=1,2,⋯,n且i=j)
对于文法中的每一个非终结符A,若它存在某个候选首符集包含ε,则
F I R S T ( α i ) ∩ F O L L O W ( A ) = ∅ ( i = 1 , 2 , ⋯ , n ) FIRST(α_i )∩FOLLOW(A)=∅(i=1,2,⋯,n) FIRST(αi)∩FOLLOW(A)=∅(i=1,2,⋯,n)
避免在分析表的同一栏目内出现
{ A → a A → ε \left\{ \begin{aligned} A→a\\ A→ε\\ \end{aligned} \right. {A→aA→ε
的情况。
5.1.2 FIRST集的构造规则
FIRST集:确定了每一个非终结符在扫描输入串时所允许遇到的输入符号及所应采用的推导产生式。即该非终结符所对应的产生式中的哪一个候选式。

5.1.3 FOLLOW集的构造规则
FOLLOW集:针对“A→ε”,即在使用A的产生式进行推导时,面临输入串中哪些输入符号时则此时有一空字匹配而不出错。此时的扫描指针仍指向当前扫描的输入符号上,并不向前推进。

5.1.4 LL(1)预测分析表的建立步骤
(1)对文法G[S]的每个产生式 A → α A→α A→α执行以下(2)、(3)步。
(2)对每个终结符 a ϵ F I R S T ( A ) aϵFIRST(A) aϵFIRST(A),把 A → α A→α A→α加入到M[A,a]中,其中α为含有首字符a的候选式或为唯一的候选式。
(3)若 ε ϵ F I R S T ( A ) εϵFIRST(A) εϵFIRST(A)(即 A → ε A→ε A→ε),则对 ∀ b ∈ F O L L O W ( A ) ∀b∈FOLLOW(A) ∀b∈FOLLOW(A),将 A → ε A→ε A→ε加入到M[A,b]。
(4)把所有无定义的M[A,a]标记为“出错”。
5.2 分析预期结果
通过手工计算,验证程序结果是否正确。
分别对书中例题和自定义题目进行分析。
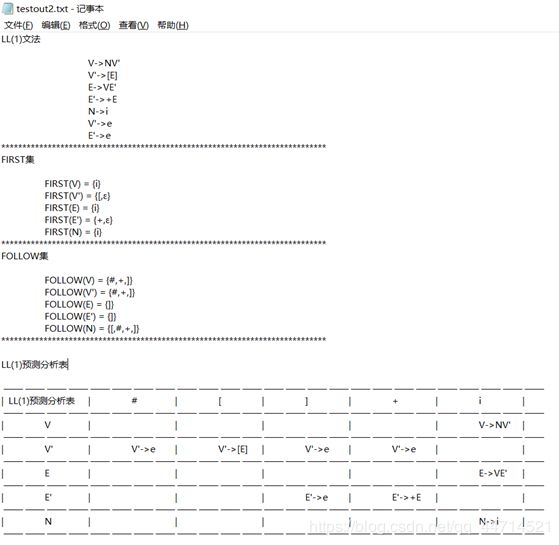
5.2.1 书中例题
(1)FIRST集

(2)FOLLOW集

(3)LL(1)分析表
| [ | ] | + | i | # | |
|---|---|---|---|---|---|
| V | V->NV’ | ||||
| N | N->i | ||||
| V’ | V’->[E] | V’->e | V’->e | V’->e | |
| E | |||||
| E’ | E’->e | E’->+E |
5.2.2 自定义例题
自己分析吧
这里说一下,在实验时没有理解透的关于FIRST集的一个点(也就是说,程序有个缺陷我没改)
关于构造FIRST遇到 A → ε A→\varepsilon A→ε的问题
干脆文字讲讲FIRST集的构造吧。
前提
文法:正规文法,即产生式左部只有一个非终结符,右部至多有一个非终结符(知道的吧,挠头,到时候整理一下0、1、2、3型文法)
冲鸭
首先,要对每一条产生式进行分析。也就是说,遇到合并的产生式要拆开分析
A->α|aβ|γ|ε \\这里有四条产生式(应该知道的吧,挠头)
\\分析这四条产生式都是为了求FIRST(A)
针对一个非终结符A,求其FIRST集,需要对它所在的产生式的右部第一个字符X进行分析
1° 如果X是终结符,那么直接将X放入FIRST(A),分析结束
2° 如果X是空字符ε,也将ε放入FIRST(A),分析结束(即A->ε的情况)
3° 麻烦的是如果X是非终结符的情况,求FIRST(A)即求FIRST(X)
① FIRST(X)中没有空字符ε,那么FIRST(A)=FIRST(X) \ {ε}
② FIRST(X)中有该死的空字符ε,根据2°有X->ε,哦豁,麻烦(不知道能不能讲清,我尽量),看X后一个字符Y
举几个例子
【例1】
A->X
X->a|ε
FIRST(A)={a,ε}
【例2】
A->XY
x->a|ε
Y->b
FIRST(A)={a,b}
【例3】
A->XY
x->a|ε
Y->b|ε
FIRST(A)={a,b,ε}
【例4】
A->Xb
x->a|ε
FIRST(A)={a,b}
5.3 编程
5.3.1 分析表预处理
对原始的文法进行以下处理:
(1) 统计非终结符个数,将非终结符填入非终结符表,获得每一条产生式中分隔符的位置;
(2) 根据分隔符所在位置分割产生式;
(3) 获得每个非终结符所对应的产生式的右部字符,包括终结符和非终结符。统计终结符个数,将终结符填入终结符表。
以流程图和伪代码的形式作为说明:
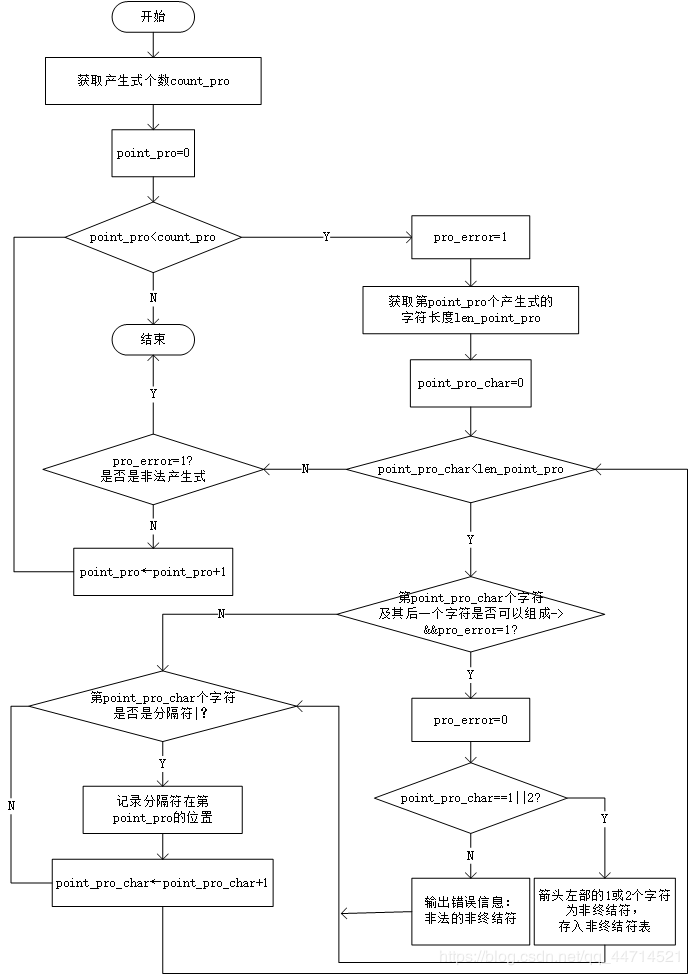
预处理(1)
预处理(2)
for(point_pro指针遍历经预处理(1)后的count_pro条产生式){
获得第point_pro个产生式分隔符表中的第一个分隔符point_seperation;
获得第point_pro个产生式分隔符表中的第一个分隔符point_seperation_next;
if(point_seperation有效,即第point_pro个产生式有分隔符){
获得第point_pro个产生式的的左部scan_pos_point_seperation_next;
while(point_seperation有效){
建立新的第count_pro条产生式;
(1)左部为scan_pos_point_seperation_next;
(2)右部为:
if(point_seperation_next有效,即第point_pro个产生式不止一个分隔符)
第count_pro个产生式的右部为:两个分隔符之间的字符串;
else
第count_pro个产生式的右部为:
分隔符point_seperation~第point_pro个字符串结尾之间的字符串;
}
//为下一次分割做准备
point_seperation=point_seperation_next;
获得第point_pro个产生式的第point_seperation个分隔符
后面一个分隔符point_seperation_next;
}
获得第point_pro个产生式右部第一个出现的分隔符所在的字符位置
置字符串结束标志;
}
else
将第point_pro个产生式结尾的换行符去掉,置字符串结束标志;
}
预处理(3)

5.3.2 FIRST集构造
(1)先进行初步构造,非终结符表中元素的个数count_Table_VN即为要分析的FIRST集总数。遍历count_Table_VN个非终结符,获得它们所在的每一个产生式的右部第一个字符,判断这个字符是终结符、非终结符还是空字符。
如果是终结符,那么直接放入当前分析的FIRST集中。
如果是非终结符,那么保存这个非终结符,并且置当前分析的FIRST集分析成功标志为FALSE(默认为TRUE)。
如果是空字符,因为分隔符已经去除,所以只可能是A→ε形式,将当前分析的FIRST集空字符标志置TRUE(默认为FALSE)。由于空字符不在终结符表中,因此它的位置假设为-1。
将分析的字符所在的产生式对应保存在当前分析的FIRST集中。
(2)然后对分析成功标志为FALSE的FIRST集进行进一步的构造。此时对当前分析的FIRST集包含的其他FIRST集的存取操作模拟栈操作。
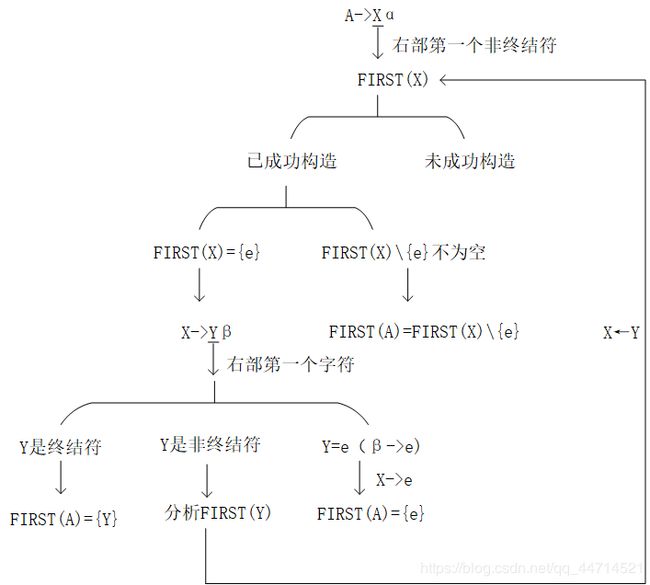

5.3.3 FOLLOW集构造
和FIRST集的构造一样,分为初步构造和进一步构造两步。
(1)先进行初步构造。
首先将字符’#’置入文法开始符的FOLLOW集。扫描每一个产生式右部的每一个字符,如果这个字符是非终结符A,就看紧跟它后面的字符是什么类型的字符X。
<1> 如果X是终结符,且FOLLOW(A)中没有X,那么把X加到FOLLOW(A)。
<2> 如果X是非终结符,且FOLLOW(X)还没有添加进FOLLOW(A)中,就分析X:若FIRST(X)有空字符,则将X所在产生式的左部B的FOLLOW集FOLLOW(B)加入到FOLLOW(A)(除非B=A,就不加入,构造成功标志仍为TRUE),置非终结符A的FOLLOW集的构造成功标志为FALSE。然后将FIRST(X){ε}加入FOLLOW(A)。
<3> 如果X是空字符,则将X所在产生式的左部B的FOLLOW集FOLLOW(B)加入到FOLLOW(A),置非终结符A的FOLLOW集的构造成功标志为FALSE。(除非B=A)。
(2)然后对分析成功标志为FALSE的FOLLOW集进行进一步的构造。
此时对当前分析的FOLLOW集包含的其他FOLLOW集的存取操作模拟栈操作。如果第point_VN个FOLLOW集A的构造成功标志为FALSE,说明FOLLOW(A)没有构造完成,含有其他非终结符的FOLLOW集。此时FOLLOW(A)中包含的这些非终结符的FOLLOW集放在同一个数组里,设置栈顶指针point_push指向这个数组的栈顶,取栈顶非终结符对其FOLLOW集B进行分析。
如果FOLLOW(B)没有构造完成,需要将FOLLOW(B)里包含的其他不是FOLLOW(A)的FOLLOW集加入FOLLOW(A)中,更新栈顶指针point_push;如果FOLLOW(B)里只包含FOLLOW(A),FOLLOW(A)对FOLLOW(B)中的FOLLOW集就分析完成。
无论FOLLOW(B)是否构造完成,如果FOLLOW(B)中有终结符,就将这些终结符添加到FOLLOW(A)中。
当FOLLOW(A)中没有其他需要分析的FOLLOW集后,将FOLLOW(A)的构造成功标志置TRUE。
5.3.4 LL(1)分析表构造
根据LL(1)分析表的构造步骤进行代码编程。
5.3.5 结果打印
打印的结果分为四个部分:
(1)去除分隔符之后的文法;
(2)FIRST集结果;
(3)FOLLOW集结果;
(4)LL(1)分析表。
将结果输出至txt文件中。
5.4 运行与调试
根据调试情况进行相应的代码修改。逐语句、逐过程进行调试,设计断点,观察局部变量窗,设置监视器。
6 运行结果截图
6.1 对例题文法的分析
6.2 对自定义文法的分析


6.3 结果分析
可以看出,运行结果与预期结果相同。并拿令一例题再做测试:
先进行文法分析:

输入无回溯和左递归的文法:(最后一个产生式也必须有换行)

程序测试结果:

结果一致,程序正确。
6.4 实验五预备



经比照,程序正确。
7 所遇问题与解决方法
在调试过程中遇到了很多问题。
7.1 关于非终结符和终结符
一开始是想整个程序的存取操作,都是直接针对char进行操作。当已经初步实现了构造FIRST集和FOLLOW集的函数后,发现这样实在是麻烦。考虑到非终结符可能带撇,所以肯定不可以用char类型去表示非终结符。一开始终结符也和非终结符一样,用char*类型表示,通过比较字符串是否相同来进行程序判断。这样做无疑增加了时间复杂度,浪费了存储空间,并且不利于LL(1)分析表的构造。心想,不行,于是悬崖勒马,推倒重来。
灵感突如其来,将终结符以char类型存储,并建立非终结符表和终结符表,因为需要随机存取,所有存储结构选用为数组。这样对非终结符和终结符的操作就可以利用它们在各自表中的位置进行。
由于都是int类型,那么怎么区别此时指的是非终结符在非终结符表中的位置还是终结符在终结符表中的位置呢?首先考虑到这个问题可能出现在对产生式的右部分析过程中。那么针对每一个产生式设置一个_Bool类型数组(bool在VS 2019环境下不能用),判断右部每一位上的字符究竟是非终结符还是终结符。区别非终结符和终结符的问题可能还会出现在构造FIRST集和FOLLOW集的过程中。考虑到FIRST集和FOLLOW集对非终结符和终结符的操作过程不同,遂单独设置VT和VN数组存放。
7.2 关于FIRST集
FIRST集的构造难点在于逻辑,当前究竟是对哪个产生式里的哪个非终结符进行操作,结果存放在哪个FIRST集中。
以及还有一个问题,就是当一条产生式不止一个分隔符时,如何将每一个部分分析得到的终结符与相应的产生式对应起来呢?比如对A->sb|Qd,Q->c,如何知道[A,c]位置填上A->Qd呢?针对这个问题,考虑建立一个存放结果的结构体,这个结构体中,将终结符与对应产生式联系起来,做到字符更新位置不更新。比如A->Qd所在的位置为3,Q->c所在的位置为5,对A->Qd进行分析时保存位置3,之后分析位置5的产生式Q->c得到c也在FIRST(A)中,那么c对应的产生式位置为3。这样便于之后LL(1)分析表的建立。
7.3 关于FOLLOW集
由于FIRST集已构造完成,FOLLOW集的构造过程其实也差不多。需要注意的是,FOLLOW集分析过程中可能会出现“死锁”,比如FOLLOW(E)中包含FOLLOW(E),或者FOLLOW(E)中包含FOLLOW(E’),而FOLLOW(E’)中又包含FOLLOW(E)。解决方案是:
针对FOLLOW集自身包含自身的情况(即FOLLOW(E)包含FOLLOW(E)),在分析过程中,判断FOLLOW(A)包含的FOLLOW(B),B是否与A相同,如果相同就跳过不分析。
针对两个FOLLOW集互相包含的情况(即FOLLOW(E)中包含FOLLOW(E’),FOLLOW(E’)中包含FOLLOW(E)),在分析FOLLOW(E)的过程中,将FOLLOW(E’)的结果无论是待分析的FOLLOW集还是终结符,全部放进FOLLOW(E)中,这样可以FOLLOW集自身包含自身情况的解决方法进行问题的消除。即FOLLOW(E)中添加FOLLOW(E’)=FOLLOW(E)+(其他FOLLOW集+终结符),判断FOLLOW(E’)中的FOLLOW(E)与FOLLOW(E)相同,跳过不分析。当FOLLOW(E)分析完成后,FOLLOW(E’)自然也就能分析完成了。
还有一个问题就是,比如在构建FOLLOW(A)时,可能存在对一个非终结符重复分析或重复添加非终结符的情况,这个时候就要与FOLLOW(A)中的结果进行比较,从而删除重复的结果。
7.4 为什么针对FIRST集和FOLLOW集分为初步构造和进一步构造
因为无论是FIRST集还是FOLLOW集,以FIRST集为例,必然存在有一个FIRST集中肯定是不包括其他FIRST集的,否则构造过程将会是一个死循环。那么总有这么一个出口,理论上来讲,不断地递归也可以实现。但问题在于,在递归过程中分析完成的FIRST集也要保存,那么递归的时间复杂度就太高。
算法思想是,不如先找出所有可能的出口,然后不断地迭代更新由于这些出口而打通的路,这样不断地有新路出现,直到大家都通了为止。
初步构造就是找出所有出口的过程,进一步构造就是在这些出口的基础上打通路的过程。
7.5 关于空字符
空字符是一个特殊的字符,处于一个不尴不尬的位置。如何对其进行操作也是一个需要考虑的重要的问题。在这里,经查阅资料借用了别人的想法,就是设置一个专门表示有没有空字符的_Bool类型的变量。FOLLOW集没有空字符。
主要是在处理FIRST集时,空字符也对应某一条产生式,这个某位置pos如何和空字符联系呢?在之前的第3点关于FIRST集中提到,是建立了一个结果结构体去联系终结符和产生式,本质就是终结符在终结符表中的位置和产生式在产生式表中的位置之间的联系。关键在于,空字符不在终结符表中,这个值也不能瞎设,不然可能会和终结符表中的某一个终结符值相冲。解决方法:考虑空字符的值设置-1。
空字符的值确定了,但是在处理过程中,空字符在哪条产生式的哪个位置出现是不定的。针对这两个哪,在产生式预处理过程中,已经将带分隔符的产生式切割,所以只可能是A->e形式的产生式才会有空字符。但为了分析方便,尤其是空字符在FIRST集的结果数组中保存的位置可能是不同的,所以设立是否有空字符的标志位,等于单独把空字符拎出来,这样就不需要遍历数组了。
7.6 关于LL(1)分析表
LL(1)分析表中如果直接存放产生式,那么浪费空间不说,操作也不是很容易。因此考虑建立int类型二维数组,分别对应哪个FIRST集/FOLLOW集的哪个终结符进行操作。因为哪个FIRST集/FOLLOW集对应的肯定是哪个非终结符,那么就是(非终结符,终结符)形式,位置固定,不需要额外去判断存放的int类型的数据是非终结符还是终结符了。
7.7 警告:C6386
一开始没有这个警告来着,后来突然出现了,提示数组可能会发生越界,拟判断是否超出数组范围,如果超出了,作错误处理。
实际实现代码过程中,没有消除这个警告。
8 心得体会
对LL(1)预测分析表的构造有了更深的理解。在实际设计和实现过程中,个人感觉虽然理论上FIRST集更易理解,但是实现起来反而更复杂。跟FIRST集的构造实现相比,FOLLOW集相对简单。
以上是一开始我的想法,后来发现对FOLLOW集的理解出现了一点问题,漏了一种情况,而且FOLLOW集会出现重复分析的问题(FIRST集由于已消除左递归,并不存在重复分析的情况),所以FOLLOW集还是挺复杂的。
由于之前一段时间一方面是比较忙,另一方面是思路还不清晰,在老师详细讲了例题之后,对LL(1)预测分析法有了更好的理解,在查阅资料的基础上,也有了大概的实现思路。大概写了有4天左右的时间吧,从早写到晚,大概改了有4版左右,其中大改过一次(直接对字符的操作,改成对字符数据指针的操作),之后思路逐渐清晰,针对各种问题有了相应的思路,大概流程有了明确的想法。所以即使每一次都是重新去写一个函数吧,但是整体走向是确定的。
由于课堂练习没有囊括FIRST集和FOLLOW集的所有构造规则,但为了完善程序必须有相对完成的测试文件才行。于是自己在例题基础上根据理解作出修改,以期达到构建相对完善的测试环境。中途遇到了几个小插曲,一个是自己改的文法由于粗心,在写FOLLOW集的时候漏分析了,然后调试程序的时候发现怎么某个FOLLOW集里多了字符呢,想了半天发现是自己的问题。以及在动手写这篇报告的时候,发现了一个大问题,就是在1.7中提到的关于FOLLOW集“死锁”问题。其实这个问题在构造之前是考虑到的,但是实现的时候还是漏了,只实现了初步分析FOLLOW集时出现的自锁情况,在对FOLLOW进行进一步分析时的互锁问题没有解决。也怪自己粗心,在最后调试时发现,怎么有FOLLOW集的构造成功标志为FALSE,但程序也成功运行了呢?此时才发现这个问题,然后修改了判断条件和相关语句,最后实现的结果还是很好的。
本程序实现的是针对无回溯和左递归的文法的LL(1)预测分析表构造。其中,包括FIRST集和FOLLOW集的构造。可以看出,对输入的文法还是有限制要求的,程序有改进的空间:比如实现对文法回溯和左递归的消除,允许输入文法的产生式允许左部相同,输出到txt文件的表格格式问题等。
由于实践跟不上实际吧,应该有更好的数据结构去实现这个程序,我只用了比较容易实现的数据结构,比如数组、栈之类。针对编程方面的弱势,还是需要勤加练习。
程序目前还是不错的,很漂亮,注释也很详细,个人还是很满意的。
2020.6.26打脸啊,这个程序FIRST集出了一点小问题没改
9 完整代码
我会贴吗,并不会,因为太多了,纯自己想的,看上去很复杂,实际上没有什么复杂数据结构的基础代码。代码链接实现预测分析表的自动生成