Mac下安装spark,并配置pycharm-pyspark完整教程
最近在学spark,先学习在Mac上安装spark,然后由于本人经常用Python,所以还要配置一下pyspark+pycharm,网上的教程大多不全,现将本人搭建的完整过程分享如下。
参考:
https://www.cnblogs.com/ostrich-sunshine/p/8414677.html
https://www.jianshu.com/p/31c7f6a5fc7e
https://www.jianshu.com/p/31c7f6a5fc7e
https://blog.csdn.net/ringsuling/article/details/84448369
https://www.cnblogs.com/zeppelin/p/8053795.html
1、安装Java环境
-
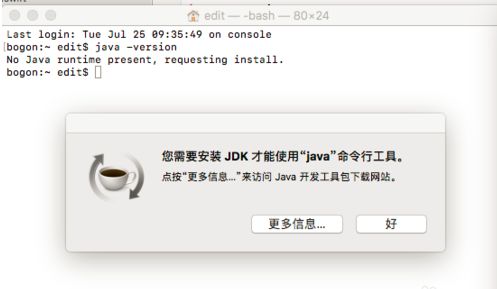
首先查看,电脑上是否装了jdk。
在终端输入 java -version
如果没有安装过jdk会提示 需要安装jdk。
-
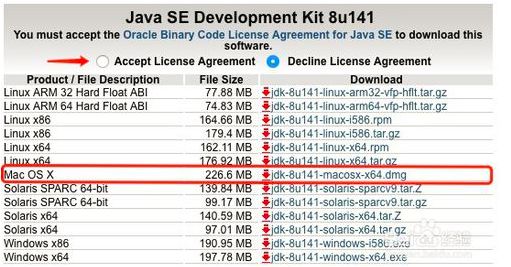
jdk下载地址是如下网址,我下的jdk8
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
-
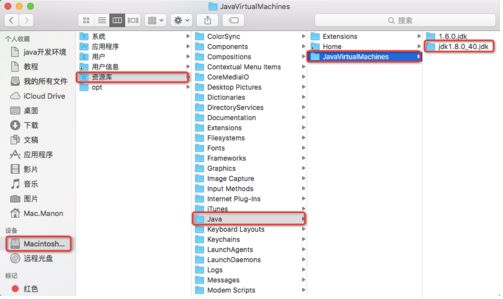
下载之后就打开dmg,安装。
在资源库下,可以查看文件的路径。
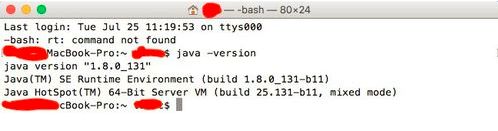
输入 java -version 查看java的版本。
如果输出版本信息,说明jdk安装成功。
2、安装软件包管理工具:brew,用于安装hadoop
执行以下命令即可安装brew最新版本(https://github.com/Homebrew/install)
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
3、配置SSH
配置ssh就是为了能够实现免密登录,这样方便远程管理Hadoop并无需登录密码在Hadoop集群上共享文件资源 。
如果你的机子没有配置ssh的话,输入ssh localhost提示需要输入你的电脑登录密码,配置好ssh之后,就不需要输入密码了。
配置ssh的步骤如下:
(1)在终端输入:ssh-keygen -t rsa,之后一路enter键就行,如果之前进行过,则会提示是否覆盖之前的key,输入y即可,会进行覆盖。
(2)终端执行:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys,用于授权你的公钥到本地可以无需密码实现登录。
此时就可以免密登录了,但是本人在执行ssh localhost后,出现了如下报错:
ssh : connect to host localhost port 22: Connection refused.

连接被拒绝。
解决方法:
选择系统偏好设置->选择共享->勾选远程登录。
之后再执行ssh localhost就可以登录成功了。如图:

4、安装hadoop
Hadoop依赖于Java环境,所以要先装Java环境
命令行执行:brew install hadoop
安装成功之后,在/usr/local/Cellar 目录下,会看到有个hadoop目录。

5、配置Hadoop
5.1配置hadoop-env.sh
进入安装目录/usr/local/Cellar/hadoop/3.0.0/libexec/etc/hadoop(注意安装目录是你自己的目录,与我的不一定相同),
找到hadoop-env.sh文件,将
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
改为:
exportHADOOP_OPTS="$HADOOP_OPTS-Djava.net.preferIPv4Stack=true -Djava.security.krb5.realm= -Djava.security.krb5.kdc="exportJAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_172.jdk/Contents/Home"
(JDK的路径,按照自己的实际情况进行配置即可)
附:查看jdk路径的方法
在控制台中输入
/usr/libexec/java_home -V
5.2配置hdfs地址和端口
进入hadoop安装目录:/usr/local/Cellar/hadoop/3.0.0/libexec/etc/hadoop,编辑core-site.xml,
将
5.3 mapreduce中jobtracker的地址和端口
仍然在hadoop的安装目录下,编辑mapred-site.xml,将
5.4 修改hdfs备份数
仍然在hadoop的安装目录下,编辑hdfs-site.xml,将
5.5 格式化hdfs
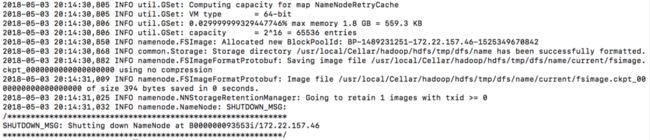
这个操作相当于一个文件系统的初始化,执行命令:hdfs namenode -format
在终端最终会显示成功
5.6 配置Hadoop环境变量
终端执行:vim ~/.bash_profile,添加hadoop的环境变量:
export HADOOP_HOME=/usr/local/Cellar/hadoop/3.0.0/libexec
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
5.7 启动关闭hadoop服务
进入目录:/usr/local/Cellar/hadoop/3.0.0/libexec/sbin下,执行如下命令:
./start-all.sh 启动hadoop命令
./stop-all.sh 关闭hadoop命令
启动成功后,在浏览器中输入http://localhost:8088,可以看到如下页面:
6、安装spark
6.1 安装spark
进入Apache Spark官网进行Spark的下载,附Spark官网下载地址:http://spark.apache.org/downloads.html
下载完之后解压,在解压文件夹所在目录下打开终端,将解压后的文件夹移动到/usr/local/目录下,并改名为spark
sudo mv ./spark-2.0.2-bin-hadoop2.7 /usr/local/spark
上述命令中用你实际解压得到的名字,与我的不一定完全相同
注意:一定要用sudo,否则没有权限
6.2 配置环境变量
命令行输入:vim ~/.bash_profile进行编辑,增加环境变量:
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
然后保存退出,执行source ~/.bash_profile,使之生效。
6.3 配置spark-env.sh
进入到Spark目录的conf配置文件中:cd /usr/local/spark/conf,执行命令:cp spark-env.sh.template spark-env.sh将spark-env.sh.template拷贝一份,然后打开拷贝后的spark-env.sh文件:vim spark-env.sh,在里面加入如下内容:
export SCALA_HOME=/usr/local/Cellar/scala/2.12.6
export SPARK_MASTER_IP=localhost
export SPARK_WORKER_MEMORY=4G
配置好之后,命令行执行:spark-shell,如果出现如下所示的画面,就表明spark安装成功了:
7、配置pycharm-pyspark
首先你要下载Python环境,pycharm
7.1 安装py4j
使用pip,运行如下命令:
pip install py4j使用conda,运行如下命令:
conda install py4j7.2 pycharm配置
使用pycharm创建一个project。
创建过程中选择python的环境。进入之后点击Run--》Edit Configurations--》Environment variables.
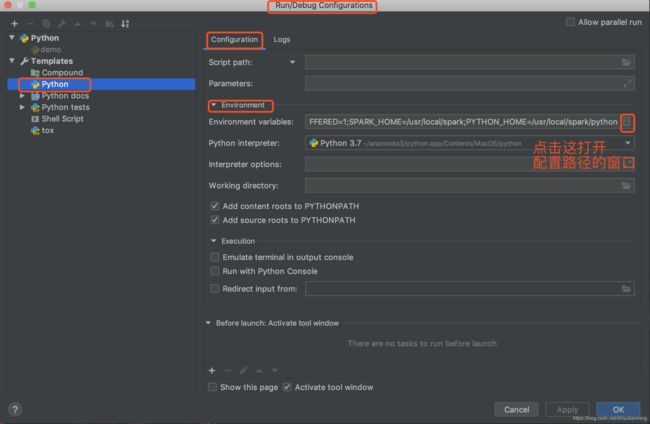
在弹出的窗口中输入两个路径
点击+,输入两个name,一个是SPARK_HOME,另外一个是PYTHONPATH,设置它们的values,
SPARK_HOME的value是安装文件夹spark-2.1.1-bin-hadoop2.7的绝对路径,例如我的SPARK_HOME的value是/usr/local/spark
PYTHONPATH的value是该绝对路径加上/python,例如我的PYTHONPATH的value是/usr/local/spark/python 。设置好了保存。(注意不管是路径的哪里,都不能有空格!!尤其是结尾!!)
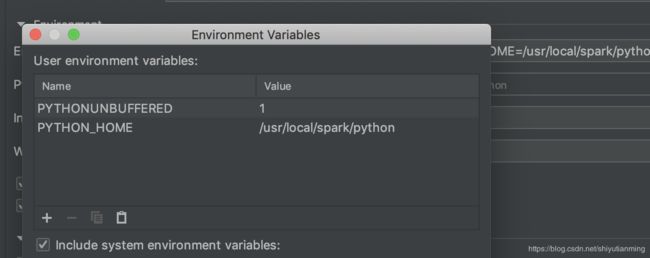
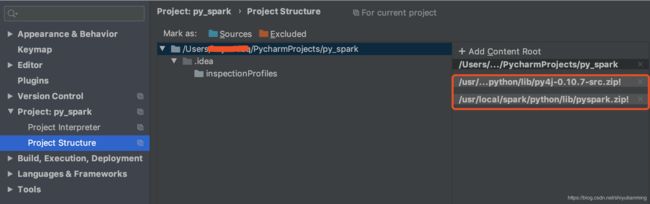
还要配置两个压缩包,否则会报错
点击Pycharm-Preference中的project structure中点击右边的“add content root”,添加py4j-some-version.zip和pyspark.zip的路径(这两个文件都在Spark中的python文件夹下)
至此,配置完成,写一个例子测试一下:
编写pyspark wordcount测试一下。我这边使用的是pyspark streaming程序。
代码如下:
WordCount.py
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# Create a local StreamingContext with two working thread and batch interval of 1 second
sc = SparkContext("local[2]", "NetWordCount")
ssc = StreamingContext(sc, 1)
# Create a DStream that will connect to hostname:port, like localhost:9999
lines = ssc.socketTextStream("localhost", 9999)
# Split each line into words
words = lines.flatMap(lambda line: line.split(" "))
# Count each word in each batch
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
# Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.pprint()
ssc.start() # Start the computation
ssc.awaitTermination() # Wait for the computation to terminate先到终端运行如下命令:
$ nc -lk 9999接着可以在pycharm中右键运行一下。然后在上面这个命令行中输入单词以空格分割:
我输入如下:
a b a d d d d 然后摁回车。可以看到pycharm中输出如下结果:
Time: 2017-12-17 22:06:19
-------------------------------------------
('b', 1)
('d', 4)
('a', 2)至此,完成。