java——比较难和底层的面试题 多线程相关
多线程相关:
-
线程池的原理,为什么要创建线程池?创建线程池的方式;
答:线程池的大致原理:就是利用队列保存不能处理的请求,当有可用线程时再处理队列里的请求。为什么要创建线程:
-
降低资源消耗。通过重复利用已创建的线程降低线程创建、销毁线程造成的消耗。
-
提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
-
提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配、调优和监控
Java通过Executors提供四种线程池,分别为:
参考博客:https://my.oschina.net/sdlvzg/blog/2222136
- newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
- newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
- newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
- newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
阿里对于线程池的使用具有以下规范:
-
【强制】线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
说明: 使用线程池的好处是减少在创建和销毁线程上所花的时间以及系统资源的开销,解决资
源不足的问题。如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者
“过度切换”的问题。
- 【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样
的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明: Executors 返回的线程池对象的弊端如下:
1) FixedThreadPool 和 SingleThreadPool:
允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
2) CachedThreadPool 和 ScheduledThreadPool:
允许的创建线程数量为 Integer.MAX_VALUE, 可能会创建大量的线程,从而导致 OOM。
通过ThreadPoolExecutor创建线程池:参考博客:https://www.jianshu.com/p/e8dfda2a558c
上边提到啦,Executors是个静态工厂,用它可以创建一些类型的线程池。除了ThreadPoolExecutor外,还有基于ScheduledThreadPoolExecutor、ForkJoinPool之类的其他类型的线程池(这个就不记录啦,因为还没学会/(ㄒoㄒ)/~~)有兴趣ForkJoinPool可以看http://blog.dyngr.com/blog/2016/09/15/java-forkjoinpool-internals/
只看ThreadPoolExecutor的话,其实具体还是上述七个参数不同组合导致的不同分类:
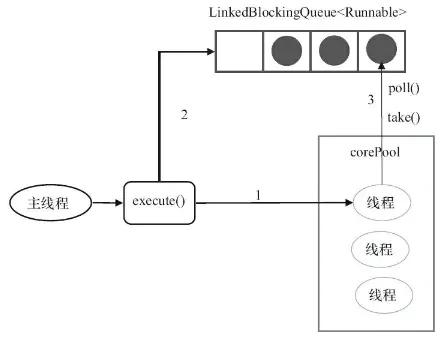
(1) newFixedThreadPool()
知乎偷图系列【https://www.zhihu.com/question/23212914】
根据参数就可以发现,这是个固定大小的线程池,核心线程数和最大线程数都是nThreads,当corePoolSize满了之后就加入到LinkedBlockingQueue无界队列中等待。
另外,加入线程池的线程属于托管状态,线程的运行不受加入顺序的影响。
还有一个重载的方法,可以设置threadFactory。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue(),
threadFactory);
}
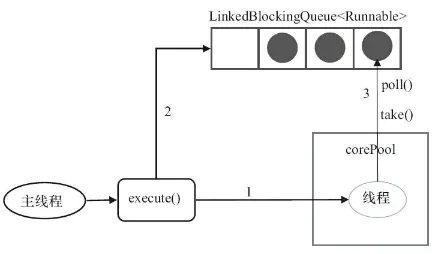
(2)newSingleThreadExecutor()
知乎偷图系列【https://www.zhihu.com/question/23212914】
这个和newFixedThreadPool差不多,就是线程数的差异,这个就一个。满了就放入队列中,执行完了就从队列取一个。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue(),
threadFactory));
}
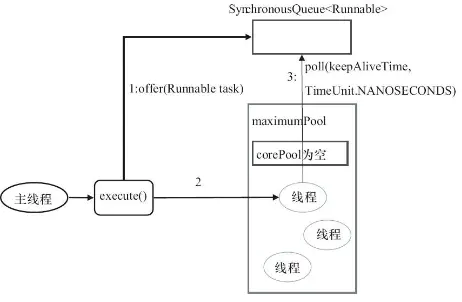
(3)newCachedThreadPool()
知乎偷图系列【https://www.zhihu.com/question/23212914】
这个从参数看的话,核心线程数是0,但是线程池大小可以认为是无限大,有60s的存活时间。而且用的SynchronousQueue装等待的任务,这个阻塞队列没有存储空间,这意味着只要有请求到来,就必须要找到一条工作线程处理他,如果当前没有空闲的线程,那么就会再创建一条新的线程。
我觉得这个主要缓存是缓存的是线程池,比方说某时间点来了10个任务,开了10个线程去跑,但跑完他不会被回收,再来5个的话就会用这10个中的5个run。这样可以减少不必要的线程创建和销毁上的消耗。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue(),
threadFactory);
}
em.. 但是看资料的时候发现:
在阿里巴巴java开发手册中明确指出,不允许使用Executors创建线程池。
-
线程的生命周期,什么时候会出现僵死进程;
答:线程的生命周期一共分为五个部分分别是:新建,就绪,运行,阻塞以及死亡;
由于某种原因导致正在运行的线程让出CPU并暂停自己的执行,即进入堵塞状态。阻塞结束后线程进入就绪状态。
堵塞的情况分三种:
(一)等待堵塞:执行的线程执行wait()方法,JVM会把该线程放入等待池中。
(二)同步堵塞:执行的线程在获取对象的同步锁时,若该同步锁被别的线程占用。则JVM会把该线程放入锁池中。
(三)其它堵塞:执行的线程执行sleep()或join()方法,或者发出了I/O请求时。JVM会把该线程置为堵塞状态。
当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完成时。线程又一次转入就绪状态。
-
说说线程安全问题,什么实现线程安全,如何实现线程安全;
答:线程安全:就是多线程访问同一代码,不会产生不确定结果。
线程安全问题的四种方法
使用同步代码块synchronized:
格式:synchronized(锁对象){
访问了共享资源的代码
}
使用同步方法:
格式:修饰符 synchronized 返回类型 方法名(参数列表){
访问了共享资源的代码
}
使用静态同步方法:
格式:修饰符(static) synchronized 返回类型 方法名(参数列表){
访问了共享资源的代码
}
使用Lock锁:
步骤:
(1)在成员位置创建一个ReentrantLock对象(该类实现了Lock接口,并添加了三个实用方法);
(2)在可能会出现安全问题的代码之前使用Lock接口的lock方法获取锁;
(3)在可能会出现安全问题的代码之后使用Lock接口的unlock方法释放锁。
发现:ReentrantLock类使用wait()和notify()会报错IllegalMonitorStateException(非法监视器状态异常),目前还不知道为啥。
-
创建线程池有哪几个核心参数?如何合理配置线程池的大小?
答:(1):corePoolSize:核心线程数。也就是该线程池的基本大小。
(2)maximumPoolSize:线程池中允许的最大线程数。
(3)keepAliveTime:空闲线程允许存活的最长时间
(4)unit : 时间单位
(5)workQueue : 任务队列。存储暂时无法执行的任务,等待空闲线程来执行任务。
(6)threadFactory : 线程工程,用于创建线程。
(7)handler:表示当拒绝处理任务时的策略。
如何合理设置线程池大小:
要想合理的配置线程池的大小,首先得分析任务的特性,可以从以下几个角度分析:
- 任务的性质:CPU密集型任务、IO密集型任务、混合型任务。
- 任务的优先级:高、中、低。
- 任务的执行时间:长、中、短。
- 任务的依赖性:是否依赖其他系统资源,如数据库连接等。
性质不同的任务可以交给不同规模的线程池执行。
对于不同性质的任务来说,CPU密集型任务应配置尽可能小的线程,如配置CPU个数+1的线程数,IO密集型任务应配置尽可能多的线程,因为IO操作不占用CPU,不要让CPU闲下来,应加大线程数量,如配置两倍CPU个数+1,而对于混合型的任务,如果可以拆分,拆分成IO密集型和CPU密集型分别处理,前提是两者运行的时间是差不多的,如果处理时间相差很大,则没必要拆分了。
若任务对其他系统资源有依赖,如某个任务依赖数据库的连接返回的结果,这时候等待的时间越长,则CPU空闲的时间越长,那么线程数量应设置得越大,才能更好的利用CPU。
当然具体合理线程池值大小,需要结合系统实际情况,在大量的尝试下比较才能得出,以上只是前人总结的规律。
-
Synchronized、volatile与ThreadLocal区别及使用场景
答:1.Synchronized
Synchronized关键字保证了数据读写一致和可见性等问题,但是他是一种阻塞的线程控制方法,在关键字使用期间,所有其他线程不能使用此变量。(同步机制采用了“以时间换空间”的方式)
2.volatile
volatile如何实现可见性?
volatile变量每次被线程访问时,都强迫线程从主内存中重读该变量的最新值,而当该变量发生修改变化时,也会强迫线程将最新的值刷新回主内存中。这样一来,不同的线程都能及时的看到该变量的最新值。
但是volatile不能保证变量更改的原子性:
比 如number++,这个操作实际上是三个操作的集合(读取number,number加1,将新的值写回number),volatile只能保证每一 步的操作对所有线程是可见的,但是假如两个线程都需要执行number++,那么这一共6个操作集合,之间是可能会交叉执行的,那么最后导致number 的结果可能会不是所期望的。
所以对于number++这种非原子性操作,推荐用synchronized:
synchronized(this){
number++;
}
3.synchronized和volatile比较
volatile不需要同步操作,所以效率更高,不会阻塞线程,但是适用情况比较窄
volatile读变量相当于加锁(即进入synchronized代码块),而写变量相当于解锁(退出synchronized代码块)
synchronized既能保证共享变量可见性,也可以保证锁内操作的原子性;volatile只能保证可见性
4.ThreadLocal
ThreadLocal不是为了解决多线程访问共享变量,而是为每个线程创建一个单独的变量副本,提供了保持对象的方法和避免参数传递的复杂性。
顾名思义它是local variable(线程局部变量)。它的功用非常简单,就是为每一个使用该变量的线程都提供一个变量值的副本,是每一个线程都可以独立地改变自己的副本,而不会和其它线程的副本冲突。从线程的角度看,就好像每一个线程都完全拥有该变量。(ThreadLocal采用了“以空间换时间”的方式)
-
ThreadLocal什么时候会出现OOM的情况?为什么?
答:参考博客:https://blog.csdn.net/GoGleTech/article/details/78318712
ThreadLocal的实现是这样的:每个Thread 维护一个 ThreadLocalMap 映射表,这个映射表的 key 是 ThreadLocal实例本身,value 是真正需要存储的 Object。
3、也就是说 ThreadLocal 本身并不存储值,它只是作为一个 key 来让线程从 ThreadLocalMap 获取 value。值得注意的是图中的虚线,表示 ThreadLocalMap 是使用 ThreadLocal 的弱引用作为 Key 的,弱引用的对象在 GC 时会被回收。
4、ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal没有外部强引用来引用它,那么系统 GC 的时候,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会一直存在一条强引用链:Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value永远无法回收,造成内存泄漏。
5、总的来说就是,ThreadLocal里面使用了一个存在弱引用的map, map的类型是ThreadLocal.ThreadLocalMap. Map中的key为一个threadlocal实例。这个Map的确使用了弱引用,不过弱引用只是针对key。每个key都弱引用指向threadlocal。 当把threadlocal实例置为null以后,没有任何强引用指向threadlocal实例,所以threadlocal将会被gc回收。
但是,我们的value却不能回收,而这块value永远不会被访问到了,所以存在着内存泄露。因为存在一条从current thread连接过来的强引用。只有当前thread结束以后,current thread就不会存在栈中,强引用断开,Current Thread、Map value将全部被GC回收。最好的做法是将调用threadlocal的remove方法,
扫码关注!!!!!
