JVM系列(四)之GC调优
- JVM内存参数调优
- 为什么要GC调优?
- 说说Minor GC 、Major GC、Full GC
- 总结
- 限制JVM内存的大小
- 减少新生代对象转移到老年代的数量
- 选择合适的垃圾收集器
- 垃圾收集器的调优分析
- Serial收集器
- ParNew收集器
- GC日志分析
- Parallel收集器
- Parallel Old 收集器
- CMS收集器
- 关于CMS收集器
- 关于CMS触发条件
- 在CMS出现以下失败情况时,将会触发Full GC
- GMS参数控制:
- 总结:
- G1收集器
- GC日志分析
- JVM的GC日志的主要参数包括如下几个:
- 分析GC日志
- GC分析工具
- GChisto
- GC Easy
JVM内存参数调优
为什么要GC调优?
或者说的更确切一些,对于基于Java的服务,是否有必要优化GC?应该说,对于所有的基于Java的服务,并不总是需要进行GC优化,但当你的系统时常报了内存溢出或者java程序运行缓慢时,优先排查是否是程序导致的内存泄漏,再看你是否需要JVM参数调优。
想一下进行GC优化的最根本原因,垃圾收集器清除在Java程序中创建的对象,GC执行的次数即需要被垃圾收集器清理的对象个数,与创建对象的数量成正比,因此,首先你应该减少创建对象的数量。
俗话说的好,“冰冻三尺非一日之寒”。我们应该从小事做起,否则日积月累就会很难管理。
我们需要使用StringBuilder 或者StringBuffer 来替代String, 应该尽量少的输出日志,写最优代码,从源头减少问题出现的可能。
但是,但是,我们知道有些情况会让我们束手无策,我们眼睁睁的看着XML以及JSON解析占用了大量的内存。即便我们已经尽可能少的使用String以及尽量少的输出日志,大量的临时内存被用于XML或者JSON解析,例如10-100MB。但是,舍弃XML和JSON是很难的。我们只要知道,他会占用很多内存。
如果应用内存使用量重复几次调整之后增加了,java 进程运行变慢了,你就应该考虑可以开始GC优化了。
我为GC优化归纳了两个目的:
- 一个是将转移到老年代的对象数量降到最少
- 另一个是减少Full GC的执行时间
总之,你需要时刻铭记一条:GC优化永远是最后一项任务。
说说Minor GC 、Major GC、Full GC
- Minor GC 针对Young Gen的垃圾收集
- Major GC/Full GC 整个堆内存的回收,Major GC通常是跟Full GC是等价的,因为收集Old Gen时一般会触发 Minor GC,所以相当于Full GC.
总结
Minor GC和Major GC是俗称,在Hotspot JVM实现的Serial GC, Parallel GC, CMS, G1 GC中大致可以对应到某个Young GC和Old GC算法组合;
1. Serial GC算法:Serial Young GC + Serial Old GC (敲黑板!敲黑板!敲黑板!实际上它是全局范围的Full GC);
2. Parallel GC算法:Parallel Young GC + 非并行的PS MarkSweep GC / 并行的Parallel Old GC(敲黑板!敲黑板!敲黑板!这俩实际上也是全局范围的Full GC),选PS MarkSweep GC 还是 Parallel Old GC 由参数UseParallelOldGC来控制;
3. CMS算法:ParNew(Young)GC + CMS(Old)GC (piggyback on ParNew的结果/老生代存活下来的object只做记录,不做compaction)+ Full GC for CMS算法(应对核心的CMS GC某些时候的不赶趟,开销很大);
4. G1 GC:Young GC + mixed GC(新生代,再加上部分老生代)+ Full GC for G1 GC算法(应对G1 GC算法某些时候的不赶趟,开销很大);
关于GC收集器的详细介绍和对比请看 JVM系列(三)之GC
限制JVM内存的大小
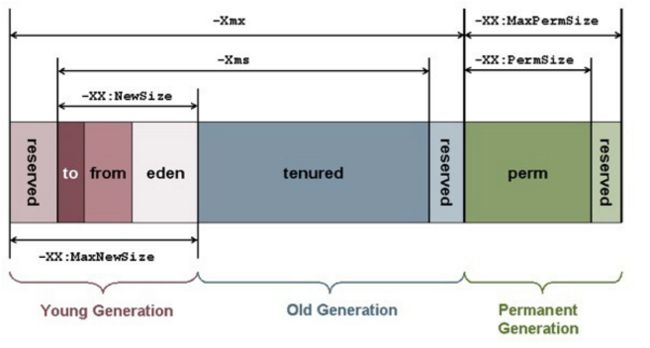
回顾内存接口区域的参数限制
JVM参数如下:
java -jar -Xms10g -Xmx15g -XX:+UseConcMarkSweepGC -XX:NewSize=6g -XX:MaxNewSize=6g -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:d:\gc.log Slaver.jar
运行时gc.log日志如下:
看一个Minor GC的log:
519.514: [GC 519.514: [ParNew: 5149852K->83183K(5662336K), 0.0831770 secs] 6955196K->1905793K(9856640K), 0.0833560 secs] [Times: user=0.57 sys=0.03, real=0.08 secs ]
采用CMS GC在发生Minor GC的时候采用的collector类似于Parallel GC,log也和Parallel GC的log类似。不多解释。
重点在于Full GC的log:
2051.800: [GC [1 CMS-initial-mark : 6040466K(6555784K)] 6161554K(12218120K), 0.1028810 secs] [Times: user=0.10 sys=0.00, real=0.11 secs ]
2051.903: [CMS-concurrent-mark-start ]
2059.492: [GC 2059.492: [ParNew: 5153779K->129958K(5662336K), 0.1145560 secs] 11194245K->6189004K(12218120K), 0.1147330 secs] [Times: user=0.82 sys=0.04, real=0.11 secs]
2067.229: [GC 2067.229: [ParNew: 5163174K->92868K(5662336K), 0.1136260 secs] 11222220K->6170498K(12218120K), 0.1137820 secs] [Times: user=0.82 sys=0.00, real=0.12 secs]
2075.005: [GC 2075.005: [ParNew: 5126084K->126301K(5662336K), 0.1205450 secs] 11203714K->6222479K(12218120K), 0.1207120 secs] [Times: user=0.84 sys=0.01, real=0.12 secs]
2077.487: [CMS-concurrent-mark: 25.231/25.584 secs] [Times: user=158.91 sys=22.71, real=25.58 secs ]
2077.487: [CMS-concurrent-preclean-start ]
2078.512: [CMS-concurrent-preclean: 0.961/1.025 secs] [Times: user=5.97 sys=1.20, real=1.03 secs]
2078.513: [CMS-concurrent-abortable-preclean-start]
2082.466: [GC 2082.467: [ParNew: 5159517K->89444K(5662336K), 0.1162740 secs] 11255695K->6204092K(12218120K), 0.1164340 secs] [Times: user=0.82 sys=0.01, real=0.12 secs]
CMS: abort preclean due to time 2083.642: [CMS-concurrent-abortable-preclean: 4.933/5.129 secs] [Times: user=31.10 sys=4.89, real=5.12 secs]
2083.644: [GC[YG occupancy: 877128 K (5662336 K)]2083.644: [Rescan (parallel) , 0.5058390 secs]2084.150: [weak refs processing, 0.0000630 secs] [1 CMS-remark: 6114647K(6555784K)] 6991776K(12218120K), 0.5060260 secs] [Times: user=3.35 sys=0.01, real=0.50 secs ]
2084.150: [CMS-concurrent-sweep-start ]
2090.416: [GC 2090.416: [ParNew: 5122660K->124614K(5662336K), 0.1247190 secs] 11237258K->6257803K(12218120K), 0.1248800 secs] [Times: user=0.88 sys=0.00, real=0.12 secs]
2095.868: [CMS-concurrent-sweep: 11.593/11.718 secs] [Times: user=70.11 sys=11.53, real=11.72 secs]
2095.896: [CMS-concurrent-reset-start ]
2096.124: [CMS-concurrent-reset: 0.227/0.227 secs] [Times: user=1.33 sys=0.19, real=0.23 secs]
减少新生代对象转移到老年代的数量
选择合适的垃圾收集器
- Serial收集器 Serial串行收集器是最古老,最稳定以及效率高的收集器,可能会产生较长的停顿,只使用一个线程去回收。新生代使用串行复制算法回收(Seerial New)、老年代使用串行标记-压缩算法回收(Serial Old);垃圾收集的过程中会Stop The World(服务暂停)
- ParNew收集器 是Serial串行收集器的多线程版,新生代复制算法收集器,虽然是多线程并行,只是收集线程并行,整个收集过程还是会Stop The World(服务暂停)挂起用户线程。
- Parallel收集器 和ParNew收集器类似,是一个新生代收集器。使用复制算法的并行多线程收集器。该垃圾收集器,是JAVA虚拟机在Server模式下的默认值,使用Server模式后,Java虚拟机使用Parallel Scavenge收集器(新生代)+ Serial Old收集器(老年代)的收集器组合进行内存回收。该收集器还有个特点就是“吞吐量优先”JVM自动调节参数,已达到预设的吞吐量,提升性能。
- Parallel Old 收集器 老年代收集器,Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法。这个收集器是在JDK 1.6中才开始提供的,在此之前,新生代的Parallel Scavenge收集器一直处于比较尴尬的状态。原因是,如果新生代选择了Parallel Scavenge收集器,老年代除了Serial Old(PS MarkSweep)收集器外别无选择(还记得上面说过Parallel Scavenge收集器无法与CMS收集器配合工作吗?)。由于老年代Serial Old收集器在服务端应用性能上的“拖累”,使用了Parallel Scavenge收集器也未必能在整体应用上获得吞吐量最大化的效果,由于单线程的老年代收集中无法充分利用服务器多CPU的处理能力。直到Parallel Old收集器出现后,“吞吐量优先”收集器终于有了比较名副其实的应用组合,在注重吞吐量以及CPU资源敏感的场合,都可以优先考虑Parallel Scavenge加Parallel Old收集器。
- CMS收集器 老年代收集器,它的主要适合场景是对响应时间的重要性需求 大于对吞吐量的要求,能够承受垃圾回收线程和应用线程共享处理器资源,并且应用中存在比较多的长生命周期的对象的应用。CMS是用于对tenured generation的回收,也就是年老代的回收,目标是尽量减少应用的暂停时间,减少full gc发生的几率,利用和应用程序线程并发的垃圾回收线程来标记清除年老代。在我们的应用中,因为有缓存的存在,并且对于响应时间也有比较高的要求,因此希 望能尝试使用CMS来替代默认的server型JVM使用的并行收集器,以便获得更短的垃圾回收的暂停时间,提高程序的响应性。
-
G1收集器 新生代和老年代回收器,G1 GC是Jdk7的新特性之一、Jdk7+版本都可以自主配置G1作为JVM GC选项;作为JVM GC算法的一次重大升级、DK7u后G1已相对稳定、且未来计划替代CMS。
不同于其他的分代回收算法、G1将堆空间划分成了互相独立的区块。每块区域既有可能属于O区、也有可能是Y区,且每类区域空间可以是不连续的(对比CMS的O区和Y区都必须是连续的)。这种将O区划分成多块的理念源于:当并发后台线程寻找可回收的对象时、有些区块包含可回收的对象要比其他区块多很多。虽然在清理这些区块时G1仍然需要暂停应用线程、但可以用相对较少的时间优先回收包含垃圾最多区块。这也是为什么G1命名为Garbage First的原因:第一时间处理垃圾最多的区块。平时工作中大多数系统都使用CMS、即使静默升级到JDK7默认仍然采用CMS、那么G1相对于CMS的区别在:
- G1在压缩空间方面有优势
- G1通过将内存空间分成区域(Region)的方式避免内存碎片问题
- Eden, Survivor, Old区不再固定、在内存使用效率上来说更灵活
- G1可以通过设置预期停顿时间(Pause Time)来控制垃圾收集时间避免应用雪崩现象
- G1在回收内存后会马上同时做合并空闲内存的工作、而CMS默认是在STW(stop the world)的时候做
- G1也会在Young GC中使用、而CMS只能在O区使用
就目前而言、CMS还是默认首选的GC策略、可能在以下场景下G1更适合:
- 服务端多核CPU、JVM内存占用较大的应用(至少大于4G)
- 应用在运行过程中会产生大量内存碎片、需要经常压缩空间
- 想要更可控、可预期的GC停顿周期;防止高并发下应用雪崩现象
总结:
各个垃圾收集器的工作原理和作用区域有所不同,具体还需要根据业务使用场景来搭配使用各种垃圾收集器。
垃圾收集器的调优分析
Serial收集器
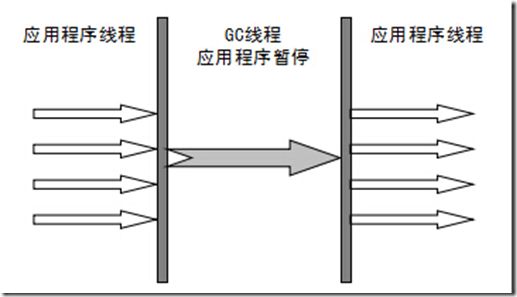
串行收集器是最古老,最稳定以及效率高的收集器,可能会产生较长的停顿,只使用一个线程去回收。新生代、老年代使用串行回收;新生代复制算法、老年代标记-压缩;垃圾收集的过程中会Stop The World(服务暂停)
参数控制:-XX:+UseSerialGC 串行收集器
JAVA OPTIONS
-XX:+UseSerialGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:d:\gc.log
Young GC日志为:
2017-10-19T11:12:07.270+0800: 0.770: [GC2017-10-19T11:12:07.270+0800: 0.770: [DefNew: 39296K->4352K(39296K), 0.0993030 secs] 61169K->58002K(126720K), 0.0993900 secs] [Times: user=0.09 sys=0.00, real=0.10 secs]
Major GC(Full GC)日志为:
2017-10-19T11:12:09.020+0800: 2.521: [Full GC2017-10-19T11:12:09.020+0800: 2.521: [Tenured: 87423K->87424K(87424K), 0.2906936 secs] 126719K->118898K(126720K), [Perm : 4728K->4728K(21248K)], 0.2907630 secs] [Times: user=0.30 sys=0.00, real=0.30 secs]
这个是 Serial Old对老年代收集时候的日志,Tenured指的是老年代回收内存前后,后面跟堆内存回收前后,Perm 指的是方法区(永久区)内存回收前后大小,最后是详细的时间信息,user 是用户态消耗的CPU时间,sys 是内核态消耗的CPU时间,而real 是操作从开始到结束的墙钟时间(包括各种非计算的等待耗时,如I/O、线程阻塞),当系统有多CPU(多核)情况下,多线程会叠加这些CPU时间来表示user或sys时间,所以user 或 sys 时间超过real是正常的;
Serial收集器 = Young Serial GC + Old Serial GC
ParNew收集器
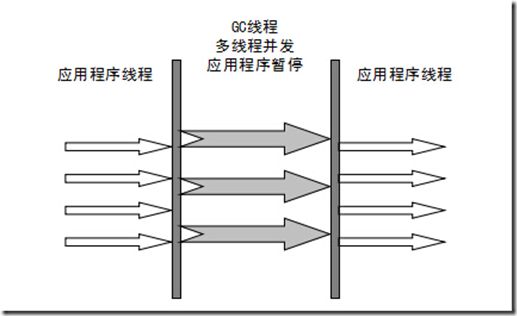
ParNew收集器其实就是Serial收集器的多线程版本。新生代并行,老年代串行;新生代复制算法、老年代标记-压缩
参数控制:
-XX:+UseParNewGC ParNew收集器 -XX:ParallelGCThreads 限制线程数量
GC日志分析
Young GC分析:
2017-10-19T11:16:03.323+0800: 0.639: [GC2017-10-19T11:16:03.324+0800: 0.639: [ParNew: 39296K->4352K(39296K), 0.0355422 secs] 61275K->58175K(126720K), 0.0356449 secs] [Times: user=0.25 sys=0.00, real=0.03 secs]
ParNew的意思就是ParNew收集器手机的意思,收集了年轻代内存,收集前39296K收集后4352K,年轻代内存总大小为39296K,收集耗时0.0355422 secs,Young GC前的堆内存使用大小为61275K,GC之后为58175K,堆内存总大小为126720K
Full GC/Major GC 日志:
2017-10-19T11:16:05.036+0800: 2.351: [Full GC2017-10-19T11:16:05.036+0800: 2.351: [Tenured: 87423K->87423K(87424K), 0.2697705 secs] 126719K->118898K(126720K), [Perm : 4728K->4728K(21248K)], 0.2698456 secs] [Times: user=0.26 sys=0.00, real=0.27 secs]
ParNew收集器 = ParNew(ParNew收集器) + Tenured(Old Serial GC) + Perm(Old Serial GC)
Parallel收集器
Parallel Scavenge(PS)收集器类似ParNew收集器,Parallel收集器更关注系统的吞吐量。可以通过参数来打开自适应调节策略,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或最大的吞吐量;也可以通过参数控制GC的时间不大于多少毫秒或者比例;新生代复制算法、老年代标记-压缩;年轻代并行,老年代串行
参数控制:-XX:+UseParallelGC 年轻代使用Parallel收集器
Young GC日志:
2017-10-19T11:18:45.907+0800: 1.228: [GC [PSYoungGen: 38880K->5096K(38912K)] 86943K->86985K(125952K), 0.1195992 secs] [Times: user=0.23 sys=0.00, real=0.13 secs]
Full GC/Major GC 日志
2017-10-19T11:18:46.038+0800: 1.347: [Full GC [PSYoungGen: 5096K->0K(38912K)] [ParOldGen: 81889K->81677K(87040K)] 86985K->81677K(125952K) [PSPermGen: 4728K->4726K(21504K)], 0.6904718 secs] [Times: user=1.44 sys=0.01, real=0.69 secs]
从上面日志可知:
Parallel收集器 = PSYoungGen(Parallel收集器) + ParOldGen(Parallel Old收集器) + PSPermGen(永久代Parallel Old收集器)
Parallel Old 收集器
Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法。这个收集器是在JDK 1.6中才开始提供,老年代并行(多线程)的垃圾收集方式,Full GC时用于收集老年代内存。
参数控制: -XX:+UseParallelOldGC 老年代使用Parallel并行收集器
-XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:d:\UseParallelOldGC.log -Xmx128M -XX:+UseParallelOldGC
Young GC日志:
2017-10-19T11:24:04.787+0800: 1.217: [GC [PSYoungGen: 38880K->5096K(38912K)] 86929K->86955K(125952K), 0.1457005 secs] [Times: user=0.39 sys=0.00, real=0.15 secs]
Full GC/Major GC 日志:
2017-10-19T11:24:04.933+0800: 1.363: [Full GC [PSYoungGen: 5096K->0K(38912K)] [ParOldGen: 81859K->81670K(87040K)] 86955K->81670K(125952K) [PSPermGen: 4728K->4726K(21504K)], 0.6701206 secs] [Times: user=1.80 sys=0.00, real=0.67 secs]
从上面日志可知-XX:+UseParallelOldGC开启使用时同时也开启了-XX:+UseParallelGC,也是JDK1.7默认GC收集器设置:
Parallel Old 收集器 = PSYoungGen(Parallel收集器) + ParOldGen(Parallel Old收集器) + PSPermGen(永久代Parallel Old收集器)
CMS收集器
关于CMS收集器的过程详细请查看 JVM系列(三)之GC
关于CMS收集器
采用CMS时候,新生代必须使用Serial GC或者ParNew GC两种,默认是ParNew GC。CMS共有七个步骤,只有Initial Marking和Final Marking两个阶段是stop-the-world的,也就是一次CMS收集的发生有两次Full GC.
关于CMS触发条件
与之前的旧生代收集器(串行GC(Serial MSC)、并行GC(Parallel MSC)不同,不需要在触发Full GC时才会执行旧生代回收器,触发CMS的条件有以下两个:
- 旧生代或者持久代已经使用的空间达到设定的百分比时(-XX:CMSInitiatingOccupancyFraction=来设置,该值代表老年代堆空间的使用率。比如,value=75意味着第一次CMS垃圾收集会在老年代被占用75%时被触发。通常CMSInitiatingOccupancyFraction的默认值为68,perm区也可以设置);
- JVM自动触发(JVM的动态策略,也就是悲观策略)(基于之前GC的频率以及旧生代的增长趋势来评估决定什么时候开始执行),如果不希望JVM自行决定,可以通过-XX:UseCMSInitiatingOccupancyOnly=true来制定;
- 设置了 -XX:CMSClassUnloadingEnabled时,表示对永久区也启用CMS垃圾收集,默认这个参数不开启
在CMS出现以下失败情况时,将会触发Full GC
-
Prommotion failed是堆碎片导致大对象没有足够的连续空间存放而提升值老年代,导致老年代空间不足时,堆碎片是有可能的,不像吞吐量收集器,CMS收集器并没有任何碎片整理的机制。因此,应用程序有可能出现这样的情形,即使总的堆大小远没有耗尽,但却不能分配对象——仅仅是因为没有足够连续的空间完全容纳对象。当这种事发生后,并发算法不会帮上任何忙,因此,万不得已JVM会触发Full GC。
Prommotion failed的日志输出大概是这样:[ParNew (promotion failed): 320138K->320138K(353920K), 0.2365970 secs]42576.951: [CMS: 1139969K->1120688K( 166784K), 9.2214860 secs] 1458785K->1120688K(2520704K), 9.4584090 secs]
-
Concurrent mode failed如果获取对象实例的频率高于收集器清除堆里死对象的频率,并发算法将再次失败。这种情况被称为“并发模式失败”。产生是由于CMS回收年老代的速度太慢,导致年老代在CMS完成前就被沾满,引起full gc。避免这个现象的产生就是调小-XX:CMSInitiatingOccupancyFraction参数的值,让CMS更早更频繁的触发,降低年老代被沾满的可能。
Concurrent mode failed的日志输出大概是这样的:2017-10-19T11:41:05.064+0800: 10.226: [Full GC2017-10-19T11:41:05.064+0800: 10.226: [CMS2017-10-19T11:41:05.283+0800: 10.453: [CMS-concurrent-mark: 0.296/0.310 secs] [Times: user=0.72 sys=0.00, real=0.30 secs]
(concurrent mode failure): 174783K->174783K(174784K), 1.0782900 secs] 242347K->241164K(253440K), [CMS Perm : 4728K->4728K(21248K)], 1.0783622 secs] [Times: user=1.28 sys=0.02, real=1.08 secs]
GMS参数控制:
- 启用CMS:-XX:+UseConcMarkSweepGC。
- 年轻代的并行收集线程数默认是(cpu <= 8) ? cpu : 3 + ((cpu * 5) / 8),如果你希望降低这个线程数,可以通过
-XX:ParallelGCThreads= N来调整。 - CMS默认启动的回收线程数目是 (ParallelGCThreads + 3)/4) ,如果你需要明确设定,可以通过
-XX:ParallelCMSThreads=20来设定,其中ParallelGCThreads是年轻代的并行收集线程数 - CMS是不会整理堆碎片的,因此为了防止堆碎片引起full gc,通过会开启CMS阶段进行合并碎片选项:
-XX:+UseCMSCompactAtFullCollection,开启这个选项一定程度上会影响性能,阿宝的blog里说也许可以通过配置适当的CMSFullGCsBeforeCompaction来调整性能,未实践。 -
为了减少第二次暂停的时间,开启并行remark:
-XX:+CMSParallelRemarkEnabled。如果remark还是过长的话,可以开启-XX:+CMSScavengeBeforeRemark选项,强制remark之前开始一次minor gc,减少remark的暂停时间,但是在remark之后也将立即开始又一次minor gc。 -
为了避免Perm区满引起的full gc,建议开启CMS回收Perm区选项:
-XX:+CMSPermGenSweepingEnabled -XX:+CMSClassUnloadingEnabled
关于XX:+CMSPermGenSweepingEnabled值得注意的是,即使没有设置这个标志,一旦永久代耗尽空间也会尝试进行垃圾回收,但是收集不会是并行的,而再一次进行Full GC。所以一般-XX:+CMSPermGenSweepingEnabled -XX:+CMSClassUnloadingEnabled同时设置。 -
默认CMS是在tenured generation沾满68%的时候开始进行CMS收集,如果你的年老代增长不是那么快,并且希望降低CMS次数的话,可以适当调高此值:
-XX:CMSInitiatingOccupancyFraction=80,这里修改成80%沾满的时候才开始CMS回收。 -
如果想在CMS过程的两次的Full GC(Initial Marking和Final Marking)之后进行内存碎片整理,
-XX:+ UseCMSCompactAtFullCollection,整理过程是独占的,会引起停顿时间变长; - 如果你想让CMS过程的几次Full GC后出发碎片整理,可以使用
-XX:+CMSFullGCsBeforeCompaction=4,表示进行2次CMS(4次Full GC)之后进行碎片整理
总结:
GMS参数调优的核心:
- 减少年轻代进入老年代的数量
- 降低出现Full GC的机会
G1收集器
G1是目前技术发展的最前沿成果之一,HotSpot开发团队赋予它的使命是未来可以替换掉JDK1.5中发布的CMS收集器,最新发布的JDK1.9默认用的就是G1收集器
GC日志分析
JVM的GC日志的主要参数包括如下几个:
-XX:+PrintGC 输出GC日志
-XX:+PrintGCDetails 输出GC的详细日志
-XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式)
-XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2017-09-04T21:53:59.234+0800)
-XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息
-Xloggc:../logs/gc.log 日志文件的输出路径
在生产环境中,根据需要配置相应的参数来监控JVM运行情况。
-
-Xms2000m -Xmx2000m -Xmn800m -XX:PermSize=64m -XX:MaxPermSize=256m
Xms,即为jvm启动时得JVM初始堆大小,Xmx为jvm的最大堆大小,xmn为新生代的大小,permsize为永久代的初始大小,MaxPermSize为永久代的最大空间。 -
-XX:SurvivorRatio=4
SurvivorRatio为新生代空间中的Eden区和救助空间Survivor区的大小比值,默认是8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10。调小这个参数将增大survivor区,让对象尽量在survitor区呆长一点,减少进入年老代的对象。去掉救助空间的想法是让大部分不能马上回收的数据尽快进入年老代,加快年老代的回收频率,减少年老代暴涨的可能性,这个是通过将-XX:SurvivorRatio 设置成比较大的值(比如65536)来做到。 -
-verbose:gc-Xloggc:$CATALINA_HOME/logs/gc.log
将虚拟机每次垃圾回收的信息写到日志文件中,文件名由file指定,文件格式是平文件,内容和-verbose:gc输出内容相同。 -
-Djava.awt.headless=trueHeadless模式是系统的一种配置模式。在该模式下,系统缺少了显示设备、键盘或鼠标。 -
-XX:+PrintGCTimeStamps -XX:+PrintGCDetails
设置gc日志的格式 -
-Dsun.rmi.dgc.server.gcInterval=600000 -Dsun.rmi.dgc.client.gcInterval=600000
指定rmi调用时gc的时间间隔 -
-XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=15采用并发gc方式,经过15次minor gc 后进入年老代
分析GC日志
开启GC的日志输出:
-XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:d:\gc.log
-XX:+PrintGCDateStamps表示GC日志的日期输出格式 -XX:+PrintGCDetails 表示打印出GC的详细日志 -Xloggc:d:\gc.log 表示日志输入的文件路径
摘录GC日志一部分
Young GC回收日志:
2016-07-05T10:43:18.093+0800: 25.395: [GC [PSYoungGen: 274931K->10738K(274944K)] 371093K->147186K(450048K), 0.0668480 secs] [Times: user=0.17 sys=0.08, real=0.07 secs]
Full GC回收日志:
2016-07-05T10:43:18.160+0800: 25.462: [Full GC [PSYoungGen: 10738K->0K(274944K)] [ParOldGen: 136447K->140379K(302592K)] 147186K->140379K(577536K) [PSPermGen: 85411K->85376K(171008K)], 0.6763541 secs] [Times: user=1.75 sys=0.02, real=0.68 secs]
通过上面日志分析得出,PSYoungGen、ParOldGen、PSPermGen属于Parallel收集器。其中PSYoungGen表示gc回收前后年轻代的内存变化;ParOldGen表示gc回收前后老年代的内存变化;PSPermGen表示gc回收前后永久区的内存变化。young gc 主要是针对年轻代进行内存回收比较频繁,耗时短;full gc 会对整个堆内存进行回城,耗时长,因此一般尽量减少full gc的次数
通过两张图非常明显看出gc日志构成:
Young GC日志: 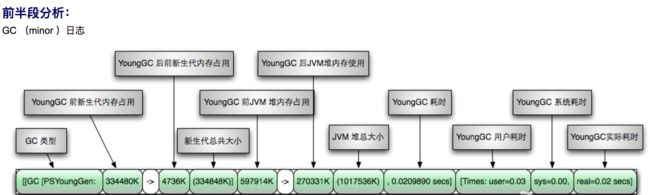
Full GC日志: 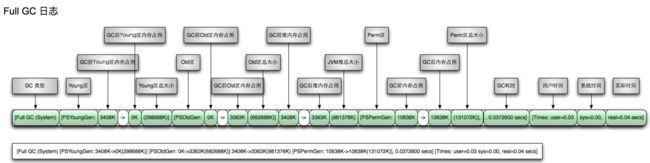
GC分析工具
GChisto
GChisto是一款专业分析gc日志的工具,可以通过gc日志来分析:Minor GC、full gc的时间、频率等等,通过列表、报表、图表等不同的形式来反应gc的情况。虽然界面略显粗糙,但是功能还是不错的。
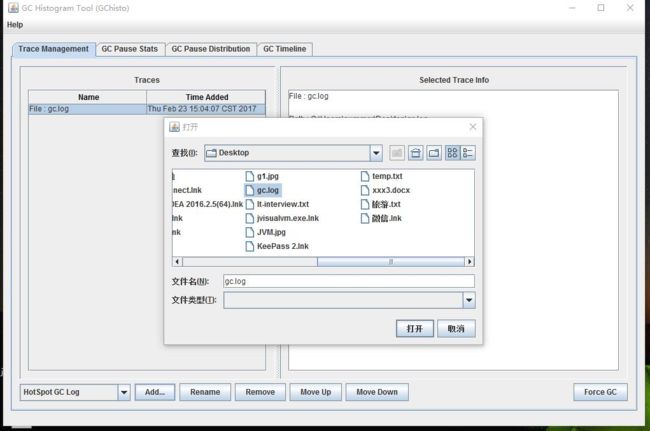
配置好本地的jdk环境之后,双击GChisto.jar,在弹出的输入框中点击 add 选择gc.log日志
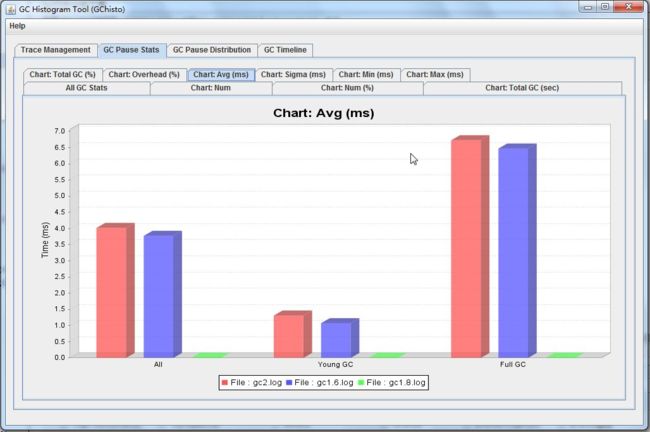
GC Pause Stats:可以查看GC 的次数、GC的时间、GC的开销、最大GC时间和最小GC时间等,以及相应的柱状图
GC Pause Distribution:查看GC停顿的详细分布,x轴表示垃圾收集停顿时间,y轴表示是停顿次数。
GC Timeline:显示整个时间线上的垃圾收集 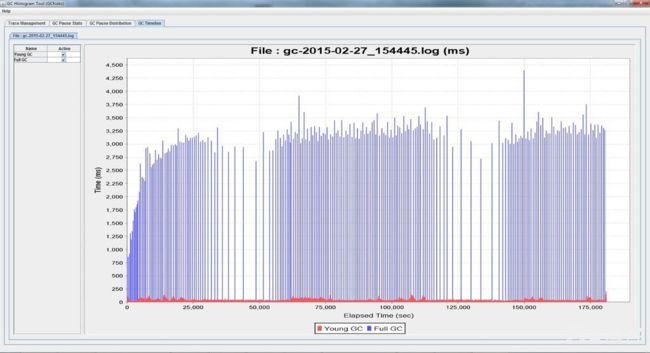
不过这款工具已经不再维护
GC Easy
这是一个web工具,在线使用非常方便.
地址: http://gceasy.io
进入官网,讲打包好的zip或者gz为后缀的压缩包上传,过一会就会拿到分析结果。
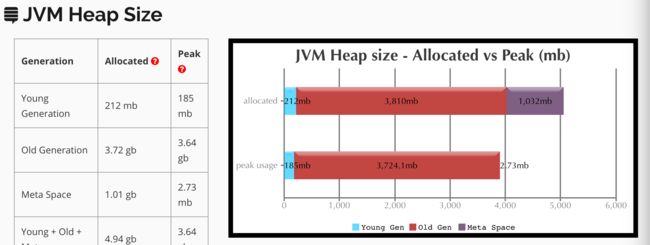
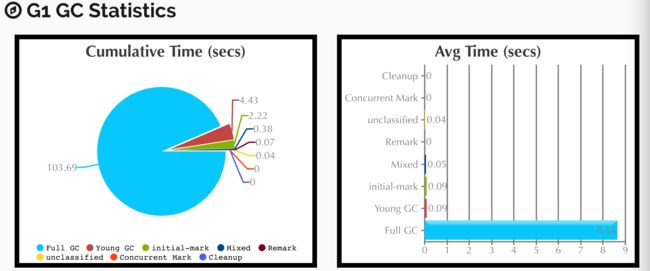
推荐使用此工具进行gc分析。
上一篇: jvm系列(一)之内存模型
下一篇: JVM系列(二)之类加载
http://blog.leanote.com/post/zhangyue/JVM%E7%B3%BB%E5%88%97%EF%BC%88%E5%9B%9B%EF%BC%89%E4%B9%8B%E8%B0%83%E4%BC%98