深度学习 ReID——读ISSDA:Unsupervised Person Re-Identification with Iterative Self-Supervised Dom...
(本文架构如下)
Pre:文章主要解决的问题 和 自己可以汲取的亮点
一.网络结构及训练过程
二.作者卖点及损失函数
(一)step1初始化模型——准备训练集及有监督训练
(二)step2迭代自监督后处理——聚类及伪标签
(三)step2迭代自监督后处理——WMCT
三.实验
四.背景知识(内容待补。。。预告:DBSCAN)
Pre:文章主要解决的问题 和 自己可以汲取的亮点:
文章主要解决的问题:
无标签数据用伪标签训练。如果是通过错误的标签的话,那么就会导致结果向一个不好的方向推进。而作者提出的WMCT, 可以削弱错误的伪标签对模型的影响。
自己可以汲取的亮点:
1.用CycleGAN做源域的风格转换(还有 那个mask是什么东东,有机会搞搞)
2.对于Re-ID中距离的度量,可以用更为适合的:K-reciprocal Encoding Distance
3.DBSCAN:无需设定K值聚类算法一枚~
4.思考点:如何降低错误伪标签影响? 或者 最根本的——如何提高伪标签准确率
5.工程方法:尽可能地优化过程中的每一个步骤。
一.网络结构及训练过程
(一)网络结构:
(下图为,使用目标域训练的过程,即已用有标签数据初始化网络)
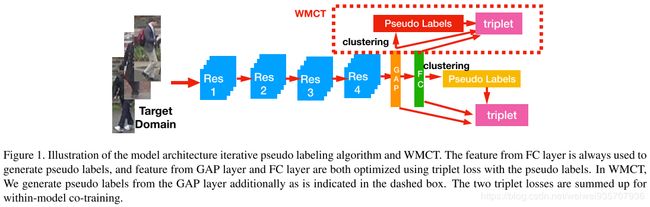
解释:
输入:目标域
蓝色:ResNet保留 最后的全局平均池化 之前的部分。
橘色:GAP——第一个特征题取器
绿色:FC——第二个特征提取器
(每个特征提取器都会生成一套伪标签; 两套伪标签会有四个triplet Loss)
(二)训练过程
首先:整体的过程=聚类打标+伪标签训练模型
step1:无标签数据经模型,得到两套特征GAP 和 FC
step2:将得到两套特征分别用DBSCAN做聚类,打标
step3:用两套伪标签的四个triplet损失优化模型(即作者卖点之一,WMCT)
step4:重复上述步骤,训练设定的次数
二.作者卖点及损失函数
(一)step1初始化模型——准备训练集及有监督训练
- 工具:CycleGAN并且迭代地,增加constraint 和 foreground mask(?)
- 损失函数:
1.对抗损失:(理解:使图片进行风格转换的同时还能保留尽量多原来图片的信息)
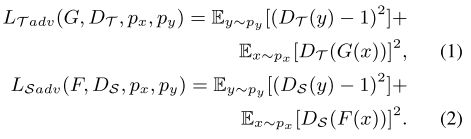
(解释:
(1)源域转目标域:扔源域,判别生成目标域,再生成源域
1)鉴别器:让式子的两项都尽量小
2)生成器:让式子的第二项尽量大
(2)目标域转源域:反过程,并且只是两个生成器对调了
1)鉴别器:(同上)
2)生成器:(同上)
)
2.循环一致损失:(理解:同上)

(解释:每个式子,第二个生成器的损失。让图片转换后还能转回来。)
3.id 约束:(理解:让同一个人的特征尽量靠近,不同人的尽量远离,即便跨域)
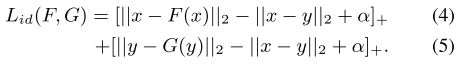
(解释:第一项靠近,第二项远离,第三项靠近,第四项远离。
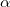 是三元组损失的常规,margin。
是三元组损失的常规,margin。
[]+代表只取正数。)
4.Masked 循环一致损失(替代循环损失,将前景和后景分开):
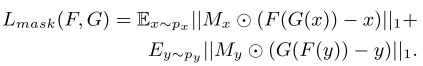
(解释:查资料再说)
- 有标签数据训练模型:使用交叉熵损失和三元组损失。
(二)step2迭代自监督后处理——聚类及伪标签
1.聚类:使用 K-reciprocal Encoding Distance,而不是大家一般用的欧式距离。(用GAP的特征)
2.伪标签:使用DBSCAN,而不是K-means等。(用FC的特征)
(三)step2迭代自监督后处理——WMCT
- 提出卖点的出发点:用伪标签训练模型,如果伪标签本身就是错的,那么就会一步错,步步错。
(”伪标签迭代使用的是GAP的特征“ ?不是两个都用吗)
- 损失函数:

(解释:
上标:聚类标准
下标:损失函数使用的特征
一开始,两套标签会有很多不一样的。(? 但是两套标准的联系怎么建立,怎么知道它们是不一 样的。 还是真的有什么伪标签和聚类标签的关系?)
理解:?是不是在一套里面是正另一套里面是负,就会削弱损失函数,下次少这么分。
)
- WMCT过程:
在设定的迭代次数里循环这个过程:
Step1:分别获得GAP和FC的距离度量矩阵
Step2:用k-reciprocal encoding and obtain来处理距离度量矩阵(?不是直接拿这个距离算吗)
Step3:用距离度量矩阵的平均 toppN 获得聚类的threshold (?什么东东)
Step4:用BDSCAN聚类,分别打标给GAP和FC (? 文章里说伪标签只用GAP是什么意思)
Step5:用伪标签和损失函数训练模型
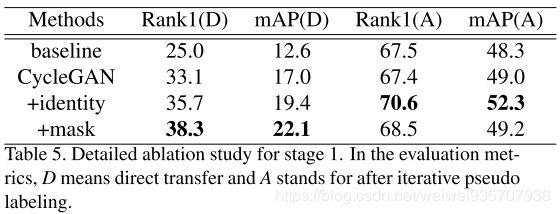
三.实验



四.背景知识
(DBSCAN,forground mask GAN)