SQL Server 2017正式发布,微软老牌数据库如何继往开来?

策划|Gary
作者|何恺铎
美国时间 2017 年 10 月 2 日,微软最新一代数据库 SQL Server 2017 正式发布。SQL Server 2017 带来了一系列全新的功能与设计,体现了微软在数据平台建设方面的最新思考和实践。InfoQ 特邀国双科技高级技术总监何恺铎撰文对 SQL Server 2017 进行深入探讨和解析,以飨各位读者。
写在前面
数十年来,关系型数据库一直是结构化数据存储的不二之选。从高校到工业界,关系型数据库向来是数据研究和应用的核心,也促生了大批从事数据库开发、维护和调优的人才。近年来随着各种 NoSQL 数据库和 Hadoop 技术生态的诞生和流行,RDBMS 似乎受到了巨大的挑战,有着“严谨呆板”形象的关系型数据库一度被市场唱衰。然而事实证明,即便面对着众多后起之秀的竞争,有着悠久历史的关系型数据库不但没有消亡,反而历久弥坚,不断推陈出新,在现代后端数据架构中仍然占据核心地位,散发出十足活力。
微软 SQL Server 数据库,是商业关系型数据库阵营中的杰出代表,在 DB-Engines 数据库流行度排行榜上常年位居前三。得益于便捷的图形化管理界面和易于上手的特点,许多人的关系型数据库之旅,就是从 SQL Server 开始的。如今正值 SQL Server 2017 发布之际,我们不妨一起来看看 SQL Server 的前世今生,探究微软数据平台发展之路。
微软 SQL Server 自身的历史具有传奇色彩,最初是由微软、Sybase、Ashton-Tate(开发 dBase 的公司)三家合作,将 Sybase SQL Server 数据库移植到 OS/2 操作系统而诞生的。后来随着 OS/2 的挫败和 Windows NT 操作系统的走强,微软停止了与 Sybase 的合作,开始聚焦于为 Windows 平台独立地开发和维护这个数据库产品,此即 Microsoft SQL Server 的由来。为了避免混淆,Sybase 也将自己的数据库从 Sybase SQL Server 重命名为了 Adaptive Server Enterprise(ASE),从此 SQL Server 仅指微软旗下关系型数据库了。说起来 Sybase 的数据库产品也一度在金融等行业享有盛誉、颇受欢迎,但如今早已风光不再,于 2010 年被 SAP 收购,令人唏嘘。
与 Sybase 分道扬镳之后的 Microsoft SQL Server,倒是稳扎稳打,一路前行。SQL Server 7.0 和 SQL Server 2000 这两个版本基本完成了在原有 Sybase 代码基础上的大量重写和扩展,正式进入企业级数据库的行列;而 SQL Server 2005 则真正走向了成熟,与 Oracle、IBM DB2 形成了商业数据库的三足鼎立之势。之后 SQL Server 历经 2008、2008 R2、2012、2014、2016 各版本的持续投入和不断进化,直至 2017 年 10 月 2 日正式发布了最新版本 SQL Server 2017,也即本文的主角。
近年回顾
在着手分析 SQL Server 2017 新特性之前,我们不妨先来看看 SQL Server 近些年的着力点,一窥其发展思路。
着力点之一,在于 OLAP。传统关系型数据库一般以行为基本的处理和存储单位,以便于数据记录的增删改查。但面对日益增长的数据分析和聚合类查询,基于行的存储和处理就显得有些笨拙和低效了。为此,在以 Denali 为代号的 SQL Server 2012 中,微软引入了一个全新的 xVelocity 列式存储与分析引擎,使得 SQL Server 拥有了一个高质量的列式存储实现,以及一个为矢量化和批处理高度优化的查询执行引擎。从此面向 OLAP 负载的数据表可以选择建立基于列存储的非聚集索引(Non Clustered Column Store Index),大幅提升了分析类查询性能。在后续的 SQL Server 版本中,列存储相关特性不断得到进一步的增强和完善,不但引入了列存储聚集索引(Clustered Column Store Index)使数据表能够完全仅以列式存储,还通过 Delta-Store 机制实现了列存储表的数据更新支持,进一步拓宽了应用场景,增强了易用性。
笔者还清晰记得多年前在自己的 Thinkpad T410 上首次尝试 SQL Server 2012 的列存储索引时带来的震撼,针对近亿行数据的分析查询在普通笔记本上也做到了数秒内的返回结果,令人印象深刻。历经多年的打磨之后,可以说微软的列存储实现已经成为世界范围内最高效最可靠的列存储设计之一。 相关技术微软甚至还作了一定程度的对外输出:通过与 HortonWorks 合作,微软向开源世界的 Apache Hive 项目贡献了不少代码(被称为 Stinger 项目,[注 1]),帮助 Hive 提速,其思想精髓也正来自于 SQL Server 的 xVelocity 列式存储和分析引擎。
着力点之二,在于 OLTP。传统关系型数据库其实本就擅长 OLTP,那么可改进的点在哪里呢?计算机发展的历史进程所带来的一个问题是,经典的数据库存储机制大都针对磁盘结构进行设计和优化,原本昂贵的内存资源更多充当的是缓存的角色。而随着硬件技术不断发展,服务器内存不断增大后,许多场景下数据的存储和索引其实都可以完全纳入内存中了——这就为基于内存的数据库引擎提供了条件。当一个数据库引擎及其存储完全为内存优化和设计后,其性能的增幅将是非常惊人的。微软数年前在这一领域进行了大举投入,代号为 Hekaton 的内存数据库技术最早在 2012 年底对外进行了公布[注 2],后随 SQL Server 2014 正式发布。配合其无锁的并发模型及用 SQL 撰写的本机编译存储过程(Natively Compiled Stored Procedure),相比传统方案,Hekaton 往往能够达到多达数十倍的性能提升,完全地改变了许多系统的设计思路,实现了之前难以企及的高负荷场景支撑。
可以看到,截止到 SQL Server 2016 版本,这款微软的拳头产品已经非常强大和完整,能够在单个产品内提供 OLAP 和 OLTP 负载的完美融合。那么仅过了短短一年时间,最新的 SQL Server 2017 还能带来哪些新的惊喜?我们来一看究竟。
新特性之跨平台与容器化
SQL Server 2017 第一个不得不提的变化,不是一个具体功能,而是其运行环境的变革:支持 Linux 服务器。这是微软 SQL Server 系列产品首次正式地得以在 Linux 上运行,并且提供完整的官方支持。这无疑大大拓宽了 SQL Server 的应用场景和客户群体。要知道,虽然 Windows Server 的授权并不算昂贵,但对于许多以 Linux 生态为主要技术栈的公司而言,并不会考虑申购和运维基于 Windows 的后端服务器——因此在技术选型时,SQL Server 可能第一时间就被排除在外了。当 SQL Server 2017 正式支持 Linux 后,这一障碍将不复存在,SQL Server 终于可以在新的战场和竞争对手开展竞争,这无疑会非常有助于其市场份额的提升。
当然,看上去深度耦合于 Windows 的 SQL Server 想要完美地运行于 Linux 上,实现起来绝非一件容易的事情。这是怎样做到的呢?这里有两个关键因素:
其一是 SQL Server 原本就有称为 SQL OS 的底层基础设施,该组件可绕过操作系统和 Win32 API 的限制,直接自行管理和组织 CPU、内存等计算和存储资源,以及进行适合自己的线程调度,以便充分利用底层硬件性能;
其二是来自微软研究院的 DrawBridge 项目,该项目原用于实现应用沙盒机制,它的 Library OS 组件依靠仅约 50 个底层内核调用实现了一千多个常用的 Windows API,同时还具备为其他组件如 MSXML 和 CLR 等提供宿主的能力。
SQL Server 团队基于这两个已有基础进行了伟大的尝试,将二者进行了必要的重写和充分的融合,形成了新一代的底层封装 SQLPAL(SQL Platform Abstraction Layer),同时将上层逻辑代码都移植到了 SQLPAL 之上——这是 SQL Server 得以在短时间内实现跨平台的关键所在。与此同时,SQLPAL 这种特殊的抽象机制,并没有付出通常意义上抽象所带来的性能代价,因为它一定程度地绕过了操作系统的制约,自底向上地搭建了自身所需的运行环境。
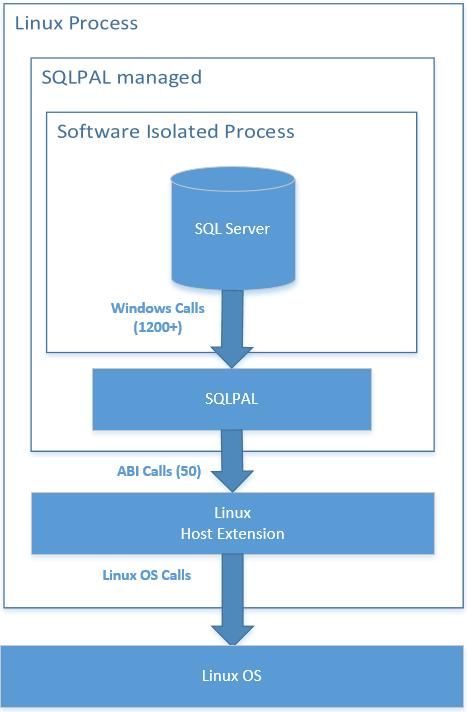
SQL Server on Linux 实现原理[注 3]
前面回顾历史时我们提到,SQL Server 在 90 年代努力地独立与成长,战略性地聚焦在了 Windows 平台。而 20 多年后,SQL Server 如今跨出拥抱 Linux 的关键一步,同样是一种战略的调整。历史看似循环往复,其实都是不同时代不同环境下的最佳商业选择。
为了给 SQL Server on Linux 保驾护航,微软还和 Red Hat 等老牌 Linux 提供商达成了合作[注 4],一起为客户提供整合解决方案,以确保操作系统层面的可靠性及与 SQL Server 的兼容性。目前 SQL Server 能够被安装到 Red Hat Enterprise Linux、SUSE Linux Enterprise Server 及 Ubuntu 之上。伴随着 Linux 支持一起到来的,还有对于容器的支持。SQL Server 2017 现能完美地通过 Docker 运行,微软也已在 Docker Hub 上发布了基于 SQL Server on Linux 的官方 SQL Server 镜像[注 5](微软同时还提供了面向 Windows 容器的版本)。SQL Server 容器化的主要意义在于支持 DevOps。在以往,想要让 SQL Server 这样一个重型数据库实例按需地、自动地启动或关闭是比较困难的,一般都需要事先安装准备好相关的数据库环境;而如今,借助容器和镜像,我们可以非常方便地通过 Docker 来轻量化地启停 SQL Server,通过脚本与 DevOps 流程进行集成也变得很容易。
笔者曾经在自己的一个开源类库[注 6]中做过这样的尝试,将原有的依赖于 SQL Server LocalDB 的一系列集成测试迁移到了新的 SQL Server 容器上,顺利解除了本地测试运行环境必须安装 SQL Server 的依赖,也为在远端 CI 环境中运行测试扫清了障碍。当然,除了 DevOps 方面的应用,也可以尝试在生产环境直接使用容器化的 SQL Server,以便使数据库也统一纳入生产环境容器编排的范畴。限于篇幅,此处不再展开。
如上所述,SQL Server 2017 已从原来固守 Windows 的策略,大步地转向了支持 Linux、Docker 容器和 Windows 三大平台。这一决策无疑将对 SQL Server 乃至数据库市场产生深远影响。
新特性之图数据处理
向新兴的 NoSQL 学习也是现代关系型数据库发展的一个重要特征。如文档型数据库善于处理的 JSON 数据,在 SQL Server 2016 中也成为了一等公民,得到了存储、索引、查询等方面的全面支持。而在 SQL Server 2017 中,这位数据库老前辈与时俱进,又开始向 Neo4j 这样的后起之秀学习,大胆地引入了图数据的处理与支持[注 7]。
众所周知,图数据库的核心实体是节点和边,通常都拥有一些属性,然后节点通过边进行相互关联。在传统关系型数据库中,对图进行建模其实并不困难,可以通过为节点和边分别建表并通过外键关联的方式来完整表达图的信息。然而,主要的问题在于查询和查询的性能:一些典型的图查询的表达在传统关系型数据库中显得笨拙而困难,尤其当需要在图的节点间进行多次跳跃(multi-hop)时,SQL 的撰写比较容易出错,查询性能也不能得到保证。
SQL Server 2017 中的图数据库特性试图解决这两个问题,它仍然以表的形式来对图信息进行建模和存储,但加上了额外的扩展,大幅提升了易用性。在创建表时,现可通过 T-SQL 的扩展语法来指定此表是图数据库中的节点表 (AS NODE) 或边表 (AS EDGE),随后 SQL Server 会隐式地为表加上 $node_id 或是 $edge_id、$from_id、$to_id 等字段,以帮助记录节点和节点间的关系;在查询时,SQL Server 2017 一定程度借鉴了 Neo4j 中 Cypher 查询语言的部分语法,通过引入 MATCH 关键词来帮助用户以 ASCII-art 的方式表达有向图中的节点巡游,同时完美地融合进现有的 SQL 查询体系。我们不妨来看一个官方的查询样例:
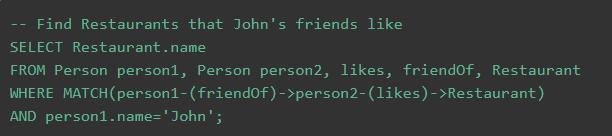
可以看到,上述 T-SQL 片段能够很方便地表达出“John 的朋友喜爱的餐馆”这个包含两种不同连接类型的“二跳式”查询,并且用 ACSII 字符表达的箭头也很好地体现了边的方向性。若与相同语义的传统 SQL 写法相比,这样的表达方式无疑清晰、直观得多。
图数据库特性在 SQL Server 2017 中已初露峥嵘。当然,由于此特性是首次引入,客观上来讲并没有到达完全成熟的程度。例如,不支持 transitive closure(节点间不限跳跃次数的连通性判断)和 polymorphism(查询某节点所能到达的不同类型的节点)等图数据库常用的高级查询。在性能方面,SQL Server 目前主要利用的也仅是二维表的既有索引和查询优化器所作的表连接优化,尚没有引入为图优化的专用数据结构。期待后续的版本升级和更新会在这些方向上做进一步的增强。
新特性之数据库内机器学习
机器学习无疑是近年来的热词,也是现代数据应用不可或缺的组成部分。微软虽然在此领域拥有雄厚的研究实力和成果,但在构建相关开发生态上却显得动作缓慢。早年的 SQL Server Analysis Service 虽然也内置了数据挖掘功能,但因过于笨重及程序集成困难等问题,使用场景非常受限。直到近年,微软才开始逐渐发力:在 2015 年初,微软果断地将 Revolution Analytics 收入囊中[注 8]。此次收购至关重要,它为微软带来了面向 R 语言生态的全面的开源和商业解决方案,覆盖了庞大的 R 语言社区和数据科学家人群。
那么作为经典的关系数据库,SQL Server 如何应对和适应这个新趋势呢?受益于 Revolution Analytics 的收购,SQL Server 2016 版本带来了突破性的 SQL Server R Services[注 9]:能够让 R 语言及其生态直接作为一个服务在 SQL Server 环境内部运行。而在 SQL Server 2017 中,更进一步加入了另一个拥有强大 AI 生态的语言支持:Python。原有的 R Services 也与新引入的 Python 服务一起重命名为 Machine Learning Services。
Machine Learning Services 的核心产品思路,是在数据库内直接运行机器学习负载,它允许大家熟悉的 Python/R 脚本与众多机器学习类库在数据库服务器上运行,并无缝地与 SQL 衔接。这样的设计理念,与传统的数据库外独立的机器学习相比有何好处呢?在笔者看来,其核心优势正在于“集成”二字,可从几个方面来理解:
一是便捷的数据集成,即无需进行复杂的数据移动和准备就可以使用 SQL 访问到各类业务数据,并提供给 Python/R 的各类 AI 算法作为输入;二是高效的模型集成,即训练完成后的模型可以使用 SQL Server 进行管理和存储,模型使用时也可轻易地通过存储过程进行调用并获取结果,SQL Server 会自动帮助你完成执行引擎和 Python/R 运行环境间的高效数据传输和序列化;三是无痛的应用集成,即应用可以通过传统的数据库连接和存储过程返回值的方式来获得机器学习能力,无需复杂的仪式和专用的架构,一切就和传统的数据库访问一致。
当然,客观地说数据库内机器学习的设计也有其技术局限,主要体现在可伸缩性方面:由于模型训练时需要较大的计算资源消耗,因此单机服务器可能成为潜在的瓶颈。虽然 SQL Server 中可以使用性能超越开源 R 实现的 ScaleR/ScalePy/MicrosoftML 等支持多线程和 GPU 加速的商业级类库,但可能仍不适合数据量大到需要动用大规模集群进行训练的场合。此外,也有人对数据库内集成 Python/R 脚本的开发、测试和运维成本表示疑虑。这些也是微软后续会考虑增强的地方,R Tools for Visual Studio 在这方面已经作出了一些努力。
对比同类解决方案,SQL Server Machine Learning Services 有其独特的优势。数据库内机器学习的理念让拥抱 AI 变得更简单而直接,也意味着更低的研发成本和更早的上线时间。它尤其适合现有基于 SQL Server 的企业应用进行机器学习方面的尝试和升级。让我们期待更多的实际案例的诞生,也期待它的进一步完善。
新特性之自适应查询处理
如果说数据库内机器学习给开发者应用带来了智能,那么 SQL Server 的查询执行引擎本身是否也能变得更聪明更智能呢?答案是肯定的,这也正是 SQL Server 2017 的另一个发展方向,相关的一系列特性被称为自适应查询处理(Adaptive Query Processing)。
SQL 查询高效执行的关键在于制定合理的执行计划。一般来说,执行计划的生成发生在查询执行之前,是执行引擎基于统计信息和索引状态等元数据信息,结合执行步骤和中间结果集的量级预估而综合得出的。同时执行计划通常会进行缓存,以便相同形式的查询可以复用查询计划,以提高综合查询性能——这一切看上去很美好,不是么?然而在实际环境中,上述的精妙机制也会遇到种种挑战和棘手问题。例如,参数化的查询常常对参数输入较为“敏感”,不同的参数会导致数据结果量级波动很大,难以事先预估和选择最优的查询计划;又如统计信息未及时更新导致中间结果集规模预估失误而选择了错误的计划;再如使用 hint 解决短期问题,导致长期来看效果适得其反等等。
为了缓解上述的种种痛点,势必要引入执行时智能和自我调优,对此 SQL Server 2017 的自适应查询处理作了有益的探索和落地。其核心思路在于,一定程度地延后完整的执行计划生成的时间,等待部分实际输入集合到位后再做下游执行方式的策略选择。例如,新引入的自适应 join 运算符可以基于上游数据输入的精准量级动态地选择联接策略是应当使用 nested loop 还是 hash join;又如多语句表值函数 (MSTVF) 不再使用固定的量级预估,而是可以先执行函数再制定下游执行计划的方式来确保获得更优的执行效率。这些新特性,有 DBA 给出了“能够避免我上周一半的查询性能调优工作” [注 10]的高度评价。
除了执行时的计划延迟生成,数据库系统还可以从已经执行完成的查询中获得反馈,以便后续的同形态查询获得更合适的查询计划,这是超越简单的执行计划缓存的更高级形式。在这个方面,SQL Server 2017 实现了批处理模式下的内存分配反馈(memory grant feedback)功能, 可帮助后续查询从之前查询的内存分配实践中吸取“经验教训”,实现内存资源的准确估计和分配。
可以看到,SQL Server 2017 已通过自适应查询处理在执行智能方面开始发力,实现了一系列场景下的自动适应和优化,同时做到了对开发者透明。目前其局限性主要在于不少上述特性仅适用于批处理模式(见于针对列存储的查询),而不适用于传统的行式处理模式。相信微软今后会在此领域加入更多对行处理模式的支持,进一步拓展自适应查询处理的适用场景。
SQL Server 与大数据
在大数据时代,以 Hadoop 为代表的分布式数据处理计算框架层出不穷,取得了空前的生态繁荣;而以 Hive、Impala、Presto 等为代表的 SQL on Hadoop 解决方案更是对传统数据库发起了强而有力的冲击。在这样的时代背景下,关系型数据库的确略显尴尬。那么,SQL Server 是如何应对和拥抱“大数据”浪潮的呢?
应对之一,是强化 SQL Server 自身的数据存储和处理能力,拓展应用场景,即”SQL Server 也能处理大数据”。得益于服务器硬件技术的不断发展,单服务器容量和处理能力不断提高,配合优秀的分区机制和列存储压缩,SQL Server 事实上已经能够处理相当大体量的数据。去年微软和英特尔曾合作进行了一个有趣的实验,使用一台单机 SQL Server 服务器承载了多达 100TB 的数据,并进行了详细的测试,其综合性能表现令人惊喜[注 11]。百 TB 的量级,其实已经能够满足不少存储和计算“大数据”的需要了。在很多场景下,与有着 over-engineering 之嫌的 Hadoop 集群方案相比,SQL Server 更易于管理和维护,架构稳定简单,反倒是综合成本更低的选择。
当然,若是面对 PB 级别以上的数据,单服务器仍会捉襟见肘。针对这样的数据量级,微软有一个被称为 SQL Server Parallel Data Warehouse(简称 PDW)的产品解决方案,可以理解为 SQL Server 的一个分布式变体,是基于 SQL Server 核心构建的一个 MPP 分析型数据库。PDW 通常以与硬件厂商合作的方式进行软硬件一体化售卖,能够轻松支持 PB 规模的数据存储与分析。
应对之二,自然是与大数据开源解决方案的充分共通与融合,尤其是大数据的事实标准:Hadoop。这里的主角,是微软在 SQL Server 2012 PDW 中开始正式引入的 PolyBase 技术。现在它不再是 PDW 版本所独有,已成为了标准 SQL Server 和 Hadoop 间的重要桥梁。PolyBase 的核心能力,是允许在 SQL Server 上下文环境中定义面向 Hadoop 的外部表,并面向外部表执行 SQL——这一设计思路和 Hive 的外部表以及 PostgreSQL 的 FDW 扩展非常类似。基于这样的核心能力,就能够很容易地实现将大量数据从 Hadoop 导入 SQL Server,也可以反向将 SQL Server 数据导出至大数据集群。若和 Sqoop 这样单纯的数据移动方案相比,PolyBase 一方面拥有更好的性能(基于直接 HDFS 访问而非 MapReduce),另一方面受益于外部表的抽象,能够在外部 Hadoop 数据不落地的情况下和本地数据库表进行联合查询。
由上可见,面对风起云涌的大数据浪潮,微软没有固步自封。在强化自身能力的同时,SQL Server 也选择了和大数据生态和谐共存,互相融合。
SQL Server 与云计算
如今的云计算发展如火如荼,因此拥抱和支持云也是每一个数据库产品都需要做好的功课。在这个方面,SQL Server 称得上是成绩出色的优等生,是微软云计算战略的重要组成部分。
作为拥抱云的第一步,微软毫无悬念地将 SQL Server 以 PaaS 服务的形式提供了出来。这一服务其实早在 2010 年就已经发布,当时命名为 SQL Azure,后改称 Azure SQL Database。对传统商业数据库而言,通常采购和安装的流程较为冗长,开发者即便有兴趣,也有比较高昂的尝试成本——Azure SQL Database 的出现彻底改变了这一点,只需在 Azure 门户中轻轻点击,一个托管的数据库实例就整装待发了。这一商业模式上的改变,无疑大大降低了微软数据库的使用门槛,拓展了使用场景。
从技术上来说,Azure SQL Database 绝非通过虚拟机提供 SQL Server 服务那么简单,它是基于 SQL Server 的能力完全为云端环境设计的 PaaS 产品——它不但拥有丰富的 SQL Server 特性,与 SQL Server 的功能升级同步,而且具有良好的弹性伸缩特点。Azure SQL Database 使用 Data Transaction Unit (DTU) 的概念来描述 SQL Database 实例的性能级别。用户可以随时地按需调整数据库实例 DTU 的大小,以达到不同时间段下工作负载和性能级别的匹配,有效地节省成本。此外,Azure SQL Database 还支持弹性池(elastic pool)特性,允许一组数据库实例共享一个资源池,特别适合于多租户的 SaaS 类应用程序。
在微软 2015 年 Build 大会上发布的 Azure SQL Data Warehouse,则是 SQL Server 在云端的另一位表亲。它本质上是前面提到的 SQL Server PDW 的云端版,是可用于大规模数据计算与分析的分布式数据仓库。SQL Data Warehouse 的核心技术,除分布式调度之外,正是运行在 SSD 存储之上的列存储索引。相对主要竞品 AWS RedShift 而言,Azure SQL Data Warehouse 受益于 Azure 存储与计算分离的理念,不但可以动态调节计算能力,甚至可以“关机”,即暂时关闭计算能力而仅保留存储——这在许多数据仓库场景中是可以节省大量成本的杀手级特性,也成为了许多客户选择 Azure 的原因。
当然,有时仍然需要 SQL Server 以 VM 的形式在 Azure 上运行,以突破一些 PaaS 形式云数据库的限制,如使用 SQL Agent 或需要在 VM 上安装其他配套软件等。针对这种情形 Azure 也提供了便捷的 SQL Server 虚拟机,开箱即用,数据库的许可证费用也会按照使用时间进行计算。
作为拥抱云计算的另一种形式,SQL Server 也非常重视云端互操作能力,将云作为自己的扩展,以及融入云端数据平台体系。首先,从 2016 版本起,SQL Server 就开始支持使用云作为数据库的外延,通过 Stretch Database 功能可以让本地数据库中的冷数据自动无缝地上传到 Azure 云中,同时前端查询不需要做任何的调整。其次,SQL Server 也能够通过不断增强的 PolyBase 技术顺畅地融入云端的大数据解决方案,如微软自家的 Azure Data Lake 或是 Hortonworks 提供支持的基于 HDP 的 HDInsight。
前景与展望
如今的 SQL Server 风华正茂,早已不是当年那个被认为“只适合中小企业”的年轻后辈。通过拿下纳斯达克、NTT DoCoMo 等大型标杆客户,SQL Server 正在全面出击、攻城掠地,已不惧怕任何竞争对手。Gartner 近年的魔力象限报告也可以印证这一点:微软已在操作型数据库、分析型数据管理解决方案和商业智能等多个领域都处于领导者象限。
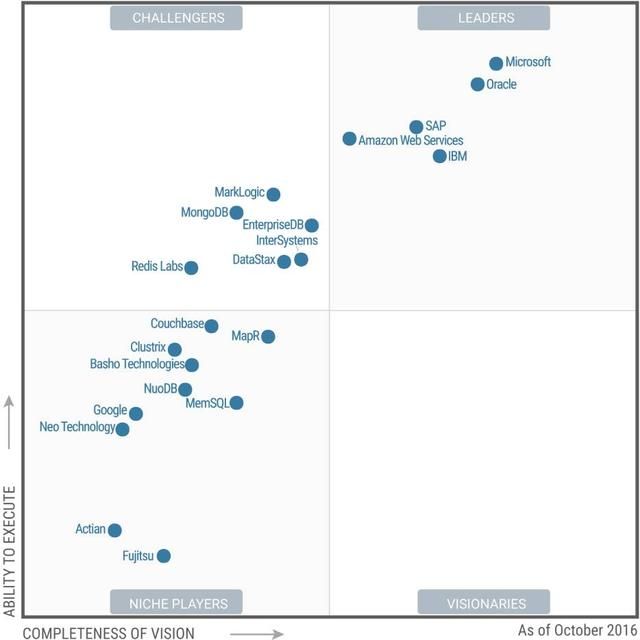
Gartner 操作型数据库 (ODBMS) 魔力象限图[注 12]
距离 SQL Server 2016 短短一年,SQL Server 2017 就全新发布了,微软明显加快了更新的节奏。支持 Linux 的 SQL Server 2017 完全有理由百尺竿头,更进一步。这是技术平台的选择,更是商业策略的创新。脱离 Windows 捆绑之后的 SQL Server 即将闯荡一片新的广阔市场。
从使用场景角度来看,如上述介绍,SQL Server 现既可以从容应对高频 OLTP 负载,也可以作为面向 OLAP 的数据仓库,还可以打造为基于内存的实时数据处理组件,或是用作应用智能的驱动引擎——SQL Server 已经变得非常“全能”。
另外值得一提的是,相比 Oracle、SAP 等竞争对手的细分产品策略和琳琅满目的产品列表,微软选择了“简单、集成”的设计哲学和商业模式。一个 SQL Server Enterprise Edition 就囊括了竞品中可能需要分别单独购买的列存储、内存数据库等功能,商务层面更加便捷的同时,也简化了系统架构。从版本策略的角度,微软也进行了聪明的调整,将大多数的重要功能下放到了 Standard Edition 和 Express Edition 中,转而主要通过数据量级来划分版本,以便高级功能触达更多的潜在客户。此外,微软还特意推出了可免费下载安装的 Developer Edition,除了不能用于生产环境之外,在功能与数据量级上与最高级的 Enterprise Edition 完全一致,没有任何限制,大大降低了开发者们体验和尝试各项企业级功能的门槛。
一个绕不开的话题,也许是同 MySQL、PostgreSQL 等开源关系型数据库以及各种 SQL on Hadoop 数据库的比较。客观地说,开源浪潮的确对商业数据库产生了巨大的冲击,出于直接成本的原因,以互联网行业为代表的诸多企业纷纷采用了开源方案。然而,随着多年来大家对开源体系与运作模式的理解不断加深,尤其是积累了大量的实践经验之后,市场逐渐趋于理性,开始更客观地看待开源模式的利弊和适用场景。天下毕竟没有免费的午餐,当企业的核心业务高负荷地运行在开源软件之上时,恐怕一样需要购买并不便宜的商业 support 服务,或是雇佣大量高级人才来了解和掌控底层的源码级细节。所以,不少企业会宁愿直接选择性能更佳、稳定性更高、企业级特性更丰富的商业数据库——因为对于这些企业来说,选择 SQL Server 具有更低的总体拥有成本。
从开发环境与工具生态上来看,SQL Server 同样具有深厚的积累。向来口碑颇佳的 SQL Server Management Studio 一直是微软持续投入的数据库综合管理工具,为 SQL Server 带来了强大而易用的图形化管理界面,可以免费下载使用;在各版本的 Visual Studio 中,也可以通过 VS 内置的 Server Explorer 连接和查询 SQL Server,与开发过程紧密联动——这些充分体现了微软大厂所能够带来的整合优势。另外值得一提的是,在编程语言支持方面,除了自家的 C#/.NET,SQL Server 团队近年来明显加大了对于其他流行语言支持的力度,尤其是 Java 和 PHP,为这些语言和平台带来了高质量的客户端类库支持。
最后,说说 SQL Server 之于中国市场。其实在国内,得益于在教育领域的耕耘和出色的产品易用性,SQL Server 一直有着比较好的群众基础和亲和形象。但若要在中国的高端市场打开局面,还需要进一步塑造品牌,打造标杆案例,消除之前给部分人群留下的“适用于中小企业”的陈旧印象。要做到这一点,除产品本身需不断提升以满足大客户苛刻需要外,还必须重视本地技术社区的建设,并帮助从业人员获得良好的职业发展,形成良性循环。另外,随着 Azure 云在中国的落地和发力,SQL Server 家族也大可借公有云发展之势进行推广,分享增长红利。
写在最后
关系型数据库源远流长,在许多场景下仍具有不可替代的重要地位。SQL Server 作为关系型数据库中的翘楚,一路走高,不断焕发着生机与活力。SQL Server 2017 的发布,有助于微软进一步巩固其市场地位,并通过支持 Linux 这一杀手锏,向新的市场发起有力冲击。
其实 SQL Server 特性之多,一文远不能穷尽。限于篇幅,我们没有提及 AlwaysOn、AlwaysEncrypted 等企业级特性,也没有详细介绍 SQL Server Integration Service、Analysis Service、Reporting Service 等商业智能套件。但通过本文上述的分析,我们已清晰地了解了这个投入巨资的商业关系数据库在新时代的大致轮廓与发展策略。如果用八个字来概括的话,“兼收并蓄,开放外联”当是最好的诠释。
那么,最后的问题来了:无论身处传统行业还是消费互联网,无论基于 Linux 还是 Windows 平台,你的下一个关键应用,会选择 SQL Server 吗?
作者介绍
何恺铎,国双科技 (Nasdaq:GSUM) 高级技术总监。毕业于清华大学,曾供职于摩根士丹利基础架构部门,2011 年加入国双科技工作至今。数年来参与架构和设计了国双多个面向数字营销和社交聆听的大数据解决方案。个人关注的技术领域包括.Net 生态系统、云计算、大数据技术栈等,曾撰写发表本文姊妹篇《从 Visual Studio 2017 谈起,解析微软技术生态进化之道》。