理解redis的分布式高可用
还是老话,直入主题。今天就是再次熟悉和理解下redis的高可用,啥是高可用呢,不废话了大家应该都知道。所以再说直白点,前两篇我们了解了redis的基础数据结构和一些高级特性,所以今天,就是来理解redis的主从复制、哨兵模式已经redis cluster这三种模式的。好了,让我们开始
主从复制
主从复制配置
在salve配置文件redis.conf中配置 slaveof 192.168.8.203 6379 启动后,查看集群状态: redis> info replication 从节点不能写入数据(只读),只能从 master 节点同步数据。
主从复制原理
基本流程
当slave连接master的时候,会发送一个ping命令给master,master接收到命令,并且slave内部有个定 时任务去检查是否有master需要连接,1秒执行一次。 然后master进行数据同步到slave,如果是第一次连接就是全量复制,如果不是的话就断点续传只复制小部分 数据进行增量复制(通过 master_repl_offset 记录的偏移量)。
数据同步
数据同步的时候,master会启动一个子线程,生成一份RDB数据快照文件,如果此时master还在接 收redis命令的话,会先将这些redis命令缓存,然后发送RDB快照文件给slave。 (如果超时会重连,可以调大 repl-timeout 的值)。 slave node 首先清除自己的旧数据,然后用 RDB 文件加载数据。 之后master会将缓存当中的redis命令,发给slave。
问题:master生成RDB文件期间,master接收到的命令怎么处理?
上面我们有说到,master会先将新的命令缓存,之后等RDB文件发给给了slave之后, 也会把缓存的redis命令发送给slave节点。
QPS压测
./redis-benchmark -h 192.168.31.187,直接使用该工具进行测试,参数: -cNumber of parallel connections (default 50) 设置多少客户端,默认50 -n Total number of requests (default 100000) 设置总请求量,默认100000 -d Data size of SET/GET value in bytes (default 2) 设置每个数据的大小,默认2字节
主从复制的缺点不足
1:RDB文件过大,同步非常耗时 2:在一主一从或者一主多从的情况下,如果master节点挂了,整个集群无法使用了,还是无法解决单点的 问题,如果每次都需要手动去设置master节点,这不符合实际


Sentinel哨兵模式
sentinel原理
主要功能:
(1)集群监控,负责监控redis master和slave进程是否正常工作,sentinel会每秒发送一次ping命令 (2)消息通知,如果某个redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员 (3)故障转移,如果master node挂掉了,会自动转移到slave node上 (4)配置中心,如果故障转移发生了,通知client客户端新的master地址
sentinel集群之间的自动发现:
哨兵互相之间的发现,是通过redis的pub/sub系统实现的, 每个哨兵都会往__sentinel__:hello这个channel里发送一个消息, 这时候所有其他哨兵都可以消费到这个消息,并感知到其他的哨兵的存在 每隔两秒钟,每个哨兵都会往自己监控的某个master+slaves对应的 __sentinel__:hello channel里发送一个消息,内容是自己的host、ip和runid还有对这个master的 监控配置 每个哨兵也会去监听自己监控的每个master+slaves对应的__sentinel__:hello channel, 然后去感知到同样在监听这个master+slaves的其他哨兵的存在 每个哨兵还会跟其他哨兵交换对master的监控配置,互相进行监控配置的同步
服务下线原理:
sentinel每秒1次的频率会给master发送ping,如果在 down-after-milliseconds 内都没有收到有效 回复,Sentinel 会将该服务器标记为下线(主观下线) 这个时候,sentinel会询问其他的snetinel,确认这个节点是否下线。如果大都数认为该节点下线, master 才真正确认被下线, 这个时候就需要重新选举 master。(客观下线)
故障转移(选举):
当master节点宕机后,sentinel就需要进行选举,然后进行故障转移。 选举出来的new mater,先是给其他slave发送 salve no one 命令,就是让slave变成独立的节点, 然后在发送 slaveof 命令挂到自身节点下。
不足
主从复制导致的数据丢失问题
因为master -> slave的复制是异步的,所以可能有部分数据还没复制到slave,master就宕机了, 此时这些部分数据就丢失了
脑裂问题
脑裂,也就是说,某个master所在机器突然脱离了正常的网络,跟其他slave机器不能连接, 但是实际上master还运行着 此时哨兵可能就会认为master宕机了,然后开启选举,将其他slave切换成了master 这个时候,集群里就会有两个master,也就是所谓的脑裂 此时虽然某个slave被切换成了master,但是可能client还没来得及切换到新的master, 还继续写向旧master的数据可能也丢失了 因此旧master再次恢复的时候,会被作为一个slave挂到新的master上去,自己的数据会清空, 重新从新的master复制数据
解决(减少数据丢失):
# 在redis的主节点的配置文件中进行配置 min-slaves-to-write 1 要求至少有1个slave min-slaves-max-lag 10 数据复制和同步的延迟不能超过10秒 减少数据同步造成的数据丢失: 有了min-slaves-max-lag这个配置,就可以确保说,一旦slave复制数据和ack延时太长, 就认为可能master宕机后损失的数据太多了,那么就拒绝写请求, 这样可以把master宕机时由于部分数据未同步到slave导致的数据丢失降低的可控范围内 减少脑裂的数据丢失: 如果一个master出现了脑裂,跟其他slave丢了连接,那么上面两个配置可以确保说, 如果不能继续给指定数量的slave发送数据,而且slave超过10秒没有给自己ack消息, 那么就直接拒绝客户端的写请求 这样脑裂后的旧master就不会接受client的新数据,也就避免了数据丢失 上面的配置就确保了,如果跟任何一个slave丢了连接,在10秒后发现没有slave给自己ack, 那么就拒绝新的写请求。因此在脑裂场景下,最多就丢失10秒的数据
哨兵的配置这里就不说了,具体的想试一下的可以看一下链接。
Redis Cluster
redis集群的架构和搭建
redis cluster 解决了分片的问题,支持横向纵向的扩展,所以在高并发的情况是很稳定的 (1)自动将数据进行分片,每个master上放一部分数据 (2)提供内置的高可用支持,部分master不可用时,还是可以继续工作的 在redis cluster架构下,每个redis要放开两个端口号,比如一个是6379, 另外一个就是加10000的端口号,比如16379 16379端口号是用来进行节点间通信的,也就是cluster bus的东西,集群总线。 cluster bus的通信,用来进行故障检测,配置更新,故障转移授权 cluster bus用了另外一种二进制的协议,主要用于节点间进行高效的数据交换, 占用更少的网络带宽和处理时间 然后关于搭建cluster这里就不写了,能偷懒就就偷懒,具体如何搭建可以看链接
数据分布
cluster模式多个master,那么它是如何解决数据分片问题的呢?如果希望数据平均分配的话,是用什么算法的呢,这里我们来理解下如何实现的数据分片。
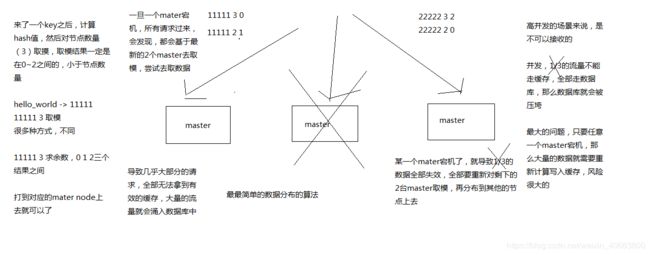
哈希取模算法:
当有n个节点得时候,此时这多个节点都是正常得,这些节点都是固定有序得。 当存储一个数据,会对这个数据得key获取哈希值然后进行取模操作,取模得到得值肯定不会大于节点数量得。 通过得到的值去操作对应得节点。 如果此时,有一个节点挂机了,等于之前得节点得顺序改变了。除了失去了这个节点上面得数据外, 若此时对key进行哈希取模,就会发现得到的值很有可能找不到对应得节点去拿了, 这就可能丢掉得不只是一个节点得数据。
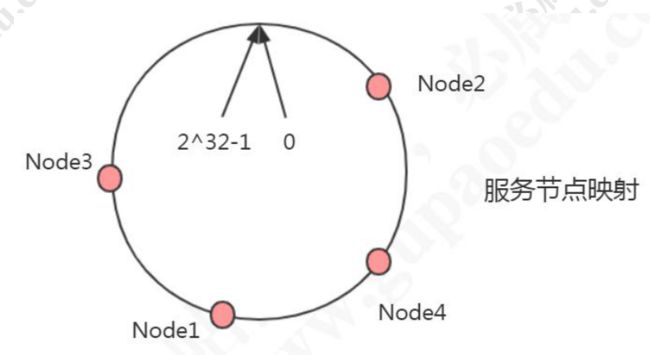
一致性哈希算法:
一致性哈希的原理: 把所有的哈希值空间组织成一个虚拟的圆环(哈希环),整个空间按顺时针方向组织。 因为是环形空间,0 和 2^32-1 是重叠的。 假设我们有四台机器要哈希环来实现映射(分布数据), 我们先根据机器的名称或者 IP 计算哈希值,然后分布到哈希环中(红色圆圈)。
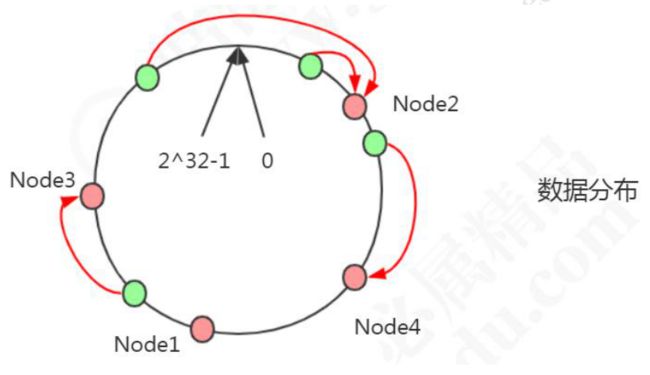
现在有 4 条数据或者 4 个访问请求,对 key 计算后,得到哈希环中的位置(绿色圆圈)。 沿哈希环顺时针找到的第一个 Node,就是数据存储的节点。
在这种情况下,新增了一个 Node5 节点,不影响数据的分布。
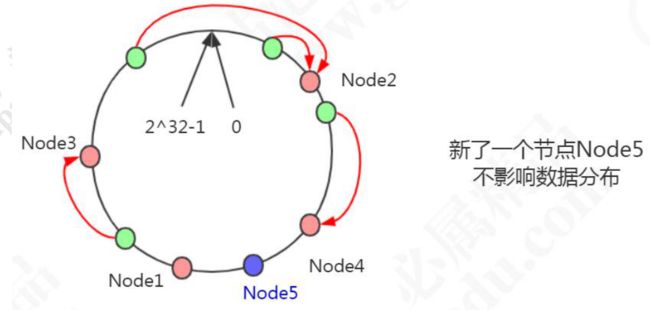
删除了一个节点 Node4,只影响相邻的一个节点。
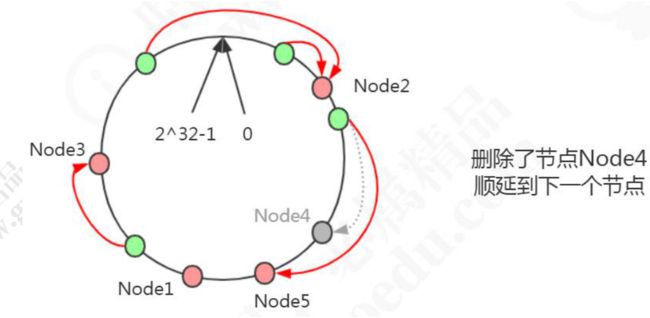
谷歌的 MurmurHash 就是一致性哈希算法。在分布式系统中,负载均衡、分库分表 等场景中都有应用。
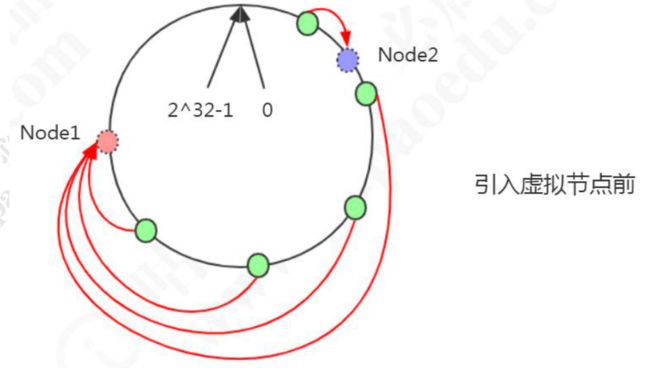
问题:数据分布不均匀
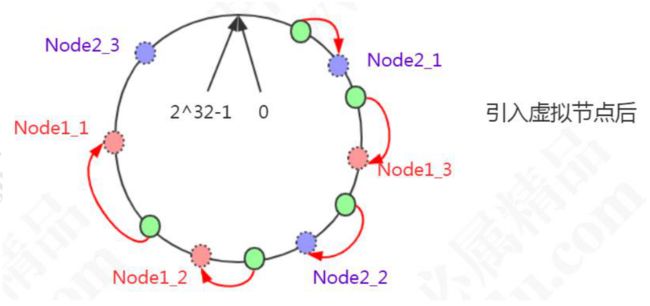
一致性哈希解决了动态增减节点时,所有数据都需要重新分布的问题,它只会影响到下一个相邻的节点, 对其他节点没有影响。 但是这样的一致性哈希算法有一个缺点,因为节点不一定是均匀地分布的,特别是 在节点数比较少的情况下,所以数据不能得到均匀分布。 解决这个问题的办法是引入虚拟节点(Virtual Node)。 比如:2 个节点,5 条数据,只有 1 条分布到 Node2,4 条分布到 Node1,不均匀。
Node1 设置了两个虚拟节点,Node2 也设置了两个虚拟节点(虚线圆圈)。 这时候有 3 条数据分布到 Node1,1 条数据分布到 Node2。
哈希slot虚拟槽分区:
Redis 既没有用哈希取模,也没有用一致性哈希,而是用虚拟槽来实现的。 Redis 创建了 16384 个槽(slot),每个节点负责一定区间的 slot。 比如 Node1 负 责 0-5460,Node2 负责 5461-10922,Node3 负责 10923-16383。
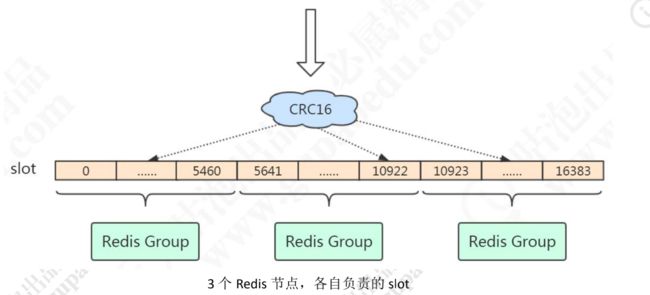
Redis 的每个 master 节点维护一个 16384 位(2048bytes=2KB)的位序列,比如:序列的第 0 位是 1,就代表第一个 slot 是它负责;序列的第 1 位是 0,代表第二个 slot不归它负责。对象分布到 Redis 节点上时,对 key 用 CRC16 算法计算再%16384取模,得到一个 slot的值,数据落到负责这个 slot 的 Redis 节点上。 这样就能得到这个数据具体在那个redis节点。 查看 key 属于哪个 slot: redis> cluster keyslot qingshan 注意:key 与 slot 的关系是永远不会变的,会变的只有 slot 和 Redis 节点的关系。
问题:怎么让一个数据落到同一个节点上?
比如有些 multi key 操作是不能跨节点的,如果要让某些数据分布到一个节点上, 例 如用户 2673 的基本信息和金融信息,怎么办? 在 key 里面加入{hash tag}即可。Redis 在计算槽编号的时候只会获取{}之间的字符 串进行槽编号计算,这样由于上面两个不同的键,{}里面的字符串是相同的,因此他们可 以被计算出相同的槽。
问题:客户端连接到哪一台服务器?访问的数据不在当前节点上,怎么办?(客户端重定向)
客户端重定向
比如在 7291 端口的 Redis 的 redis-cli 客户端操作: 127.0.0.1:7291> set qs 1 (error) MOVED 13724 127.0.0.1:7293 服务端返回 MOVED,也就是根据 key 计算出来的 slot 不归 7191 端口管理,而是 归 7293 端口管理, 服务端返回 MOVED 告诉客户端去 7293 端口操作。 这个时候更换端口,用 redis-cli –p 7293 操作,才会返回 OK。 或者用./redis-cli -c -p port 的命令(c 代表 cluster)。 这样客户端需要连接两次。 Jedis 等客户端会在本地维护一份 slot——node 的映射关系,大部分时候不需要重定向, 所以叫做 smart jedis(需要客户端支持)。
问题:新增或下线了 Master 节点,数据怎么迁移(数据迁移)?
数据迁移
因为 key 和 slot 的关系是永远不会变的,当新增了节点的时候,需要把原有的 slot分配给新的节点负责,并且把相关的数据迁移过来。添加新节点(新增一个 7297): redis-cli --cluster add-node 127.0.0.1:7291 127.0.0.1:7297 新增的节点没有哈希槽,不能分布数据,在原来的任意一个节点上执行: redis-cli --cluster reshard 127.0.0.1:7291 输入需要分配的哈希槽的数量(比如 500),和哈希槽的来源节点(可以输入 all 或者 id)。
问题:只有主节点可以写,一个主节点挂了,从节点怎么变成主节点(主从切换原理)?
主从切换原理
当 slave 发现自己的 master 变为 FAIL 状态时,便尝试进行 Failover,以期成为新的master。由于挂掉的master可能会有多个slave,从而存在多个slave竞争成为master节点的过程, 其过程如下: 1.slave 发现自己的 master 变为 FAIL 2.将自己记录的集群 currentEpoch 加 1,并广播 FAILOVER_AUTH_REQUEST 信息 3.其他节点收到该信息,只有 master 响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个 epoch 只发送一次 ack 4.尝试 failover 的 slave 收集 FAILOVER_AUTH_ACK 5.超过半数后变成新 Master 6.广播 Pong 通知其他集群节点。 Redis Cluster 既能够实现主从的角色分配,又能够实现主从切换,相当于集成了Replication 和 Sentinal 的功能。
总结:
优势
1. 无中心架构。 2. 数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布。 3. 可扩展性,可线性扩展到 1000 个节点(官方推荐不超过 1000 个),节点可动态添加或删除。 4. 高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做 standby 数据副本,能够实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave 到 Master 的角色提升。 5. 降低运维成本,提高系统的扩展性和可用性。
不足
1. Client 实现复杂,驱动要求实现 Smart Client,缓存 slots mapping 信息并及时更新,提高了开发难度,客户端的不成熟影响业务的稳定性。 2. 节点会因为某些原因发生阻塞(阻塞时间大于 clutser-node-timeout),被判断下线,这种 failover 是没有必要的。 3. 数据通过异步复制,不保证数据的强一致性。 4. 多个业务使用同一套集群时,无法根据统计区分冷热数据,资源隔离性较差,容易出现相互影响的情 14-redis cluster集群:redis cluster介绍-数据分布算法:一致性hash算法和redis cluster的hash slot算法blog.csdn.net
