1.说明
p:presto a:allixop z:zeppelin r:rancher
分为三部分讲解
1.什么是presto+Alluxio,大数据presto+Alluxio集成详细部署说明
2.大数据zeppelin+rancher,docker的集成部署
3.presto+alluxio集成ldap实操测试,zeppelin+rancher集成ldap实操测试
1.1什么是presto
于内存的并行计算,Facebook推出的分布式SQL交互式查询引擎 多个节点管道式执行
支持任意数据源 数据规模GB~PB 是一种Massively parallel processing(mpp)(大规模并行处理)模型
数据规模PB 不是把PB数据放到内存,只是在计算中拿出一部分放在内存、计算、抛出、再拿
为什么要用&优点&特点
多数据源、支持SQL、扩展性(可以自己扩展新的connector)、混合计算(同一种数据源的不同库 or表;将多个数据源的数据进行合并)、高性能、流水线(pipeline)
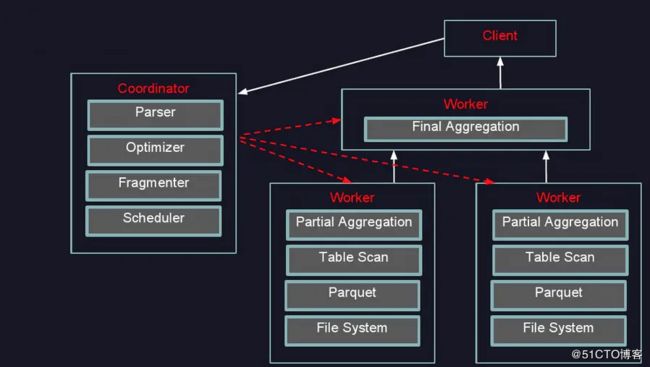
1.2 presto架构
2.1什么是alluxio
Alluxio(前身Tachyon)是世界上第一个以内存为中心的虚拟的分布式存储系统。它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁。
2.2Alluxio架构
Alluxio是大数据和机器学习生态系统中的新数据访问层。Alluxio作为据访问层处于持久存储层(如Amazon S3,Microsoft Azure Object Store,Apache HDFS或OpenStack Swift)和计算框架层(如Apache Spark,Presto或Hadoop MapReduce)之间。
3.presto+Alluxio
Starbrust + Alluxio = 在一起更好
和Alluxio一起的Starbrust Presto是一个真正独立的数据栈,支持任何文件或对象存储进行交互式大数据分析。Starbrust Presto和Alluxio整合后能够共同帮助作业运行速度提高10倍,使重要数据本地化,并连接到各种存储系统和云。

用户现在可以将他们遗留的数据仓库构建方法改为来使用现代云数据栈,在Presto、Alluxio和任何文件或对象存储上构建真正不同的数据栈。
3.1 presto部署
3.1.1Presto安装
3.1.2角色分配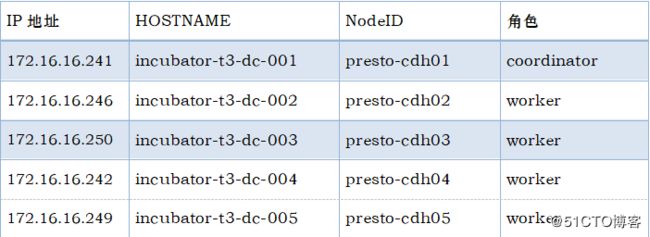
3.1.3测试环境:
1.CM6.3
2.Presto版本0.226
3.操作系统版本为Redhat7.3
4.采用root用户进行操作
3.1.4下载
下载最新版本
Presto服务的安装目录为/opt/cloudera/parcels/presto
https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.226/presto-server-0.226.tar.gz
3.1.5将下载好的presto-server-0.226.tar.gz上传至Presto集群的所有服务器上
mkdir -p /opt/cloudera/parcels/presto
scp -r -P53742 presto-server-0.226.* root@incubator-t3-dc-002:/opt/cloudera/parcels/presto/
presto-server-0.226.jar 

3.1.6解压安装(presto集群所有机器)
将presto-server-0.205.tar.gz压缩包解压至/opt/cloudera/parcels目录
# tar -zxvf presto-server-0.226.tar.gz -C /opt/cloudera/parcels/
#cd /opt/cloudera/parcels/
mv presto presto-soft
mv presto-server-0.226/ presto3.1.7Java环境变量设置
vim /opt/cloudera/parcels/presto/bin/launcher文件如下位置添加JAVA环境变量
JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
PATH=$JAVA_HOME/bin:$PATH3.1.8准备Presto的配置文件
#mkdir -p /opt/cloudera/parcels/presto/etc
#presto配置文件
#mkdir -p /data/presto
#数据盘
vim /opt/cloudera/parcels/presto/etc/node.properties
node.environment=presto
node.id=presto-cdh01
node.data-dir=/data/presto
配置说明:
node.environment:集群名称。所有在同一个集群中的Presto节点必须拥有相同的集群名称。
node.id:每个Presto节点的唯一标示。每个节点的node.id都必须是唯一的。在Presto进行重启或者升级过程中每个节点的node.id必须保持不变。如果在一个节点上安装多个Presto实例(例如:在同一台机器上安装多个Presto节点),那么每个Presto节点必须拥有唯一的node.id。
node.data-dir:数据存储目录的位置(操作系统上的路径)。Presto将会把日期和数据存储在这个目录下。3.1.9Presto的jvm配置文件
配置Presto的JVM参数,创建jvm.config文件
vim /opt/cloudera/parcels/presto/etc/jvm.config
-server
-Xmx8G
-XX:+UseConcMarkSweepGC
-XX:+ExplicitGCInvokesConcurrent
-XX:+CMSClassUnloadingEnabled
-XX:+AggressiveOpts
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError=kill -9 %p
-XX:ReservedCodeCacheSize=150M
#配置文件的格式是:一系列的选项,每行配置一个单独的选项。由于这些选项不在shell命令中使用。因此即使将每个选项通过空格或者其他的分隔符分开,java程序也不会将这些选项分开,而是作为一个命令行选项处理。(就想下面例子中的OnOutOfMemoryError选项)。
由于OutOfMemoryError将会导致JVM处于不一致状态,所以遇到这种错误的时候我们一般的处理措施就是将dump headp中的信息(用于debugging),然后强制终止进程。
Presto会将查询编译成字节码文件,因此Presto会生成很多class,因此我们我们应该增大Perm区的大小(在Perm中主要存储class)并且要允许Jvm class unloading。3.1.10创建config.properties文件
该配置文件包含了Presto Server的所有配置信息。每个Presto Server既是Coordinator也是一个Worker。在大型集群中,处于性能考虑,建议单独用一台服务器作为Coordinator。
coordinator节点的配置如下:
Presto会将查询编译成字节码文件,因此Presto会生成很多class,因此我们我们应该增大Perm区的大小(在Perm中主要存储class)并且要允许Jvm class unloading。
vim /opt/cloudera/parcels/presto/etc/coordinator-config.properties
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=6660
query.max-memory=4GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://incubator-t3-dc-001:6660
worker节点的配置如下:
vim /opt/cloudera/parcels/presto/etc/worker-config.properties
coordinator=false
http-server.http.port=6660
query.max-memory=4GB
query.max-memory-per-node=1GB
discovery.uri=http://incubator-t3-dc-001:6660
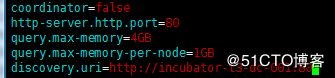
配置项说明:
coordinator:指定是否运维Presto实例作为一个coordinator(接收来自客户端的查询情切管理每个查询的执行过程)。
node-scheduler.include-coordinator:是否允许在coordinator服务中进行调度工作。对于大型的集群,在一个节点上的Presto server即作为coordinator又作为worke将会降低查询性能。因为如果一个服务器作为worker使用,那么大部分的资源都不会被worker占用,那么就不会有足够的资源进行关键任务调度、管理和监控查询执行。
http-server.http.port:指定HTTP server的端口。Presto 使用 HTTP进行内部和外部的所有通讯。
discovery.uri:Discoveryserver的URI。由于启用了Prestocoordinator内嵌的Discovery 服务,因此这个uri就是Prestocoordinator的uri。修改example.net:80,根据你的实际环境设置该URI。注意:这个URI一定不能以“/“结尾。
3.1.11新建日志文件log.properties
vim /opt/cloudera/parcels/presto/etc/log.properties
com.facebook.presto=INFO3.1.12重命名config文件
主节点
/opt/cloudera/parcels/presto/etc/
mv coordinator-config.properties config.properties
work节点
cd /opt/cloudera/parcels/presto/etc/
mv worker-config.properties config.properties3.1.13Presto服务启停/opt/cloudera/parcels/presto/bin/launcher start
#启动
![]()
/opt/cloudera/parcels/presto/bin/launcher stop
停止
3.1.14Presto-web
http://172.16.16.241/ui/
3.2 presto集成hive
1.在Presto集群的所有节点创建目录mkdir -p /opt/cloudera/parcels/presto/etc/catalog
2.创建hive.properties,该文件与Hive服务集成使用
vim /opt/cloudera/parcels/presto/etc/catalog/hive.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://incubator-t3-dc-003:9083
3.修改presto的jvm.config,在配置文件中增加Presto访问HDFS的用户名
vim /opt/cloudera/parcels/presto/etc/jvm.config
添加-DHADOOP_USER_NAME=presto
4.上面的配置中指定了presto用户作为访问HDFS的用户,需要在集群所有节点添加presto用户
useradd presto
修改完后重启presto
/opt/cloudera/parcels/presto/bin/launcher restart(所有集群机器执行)
3.3 Presto集成hive测试
这里测试Presto与Hive的集成使用Presto提供的Presto CLI,该CLI是一个可执行的JAR文件,也意味着你可以想UNIX终端窗口一样来使用CLI。
1.下载Presto的presto-cli-0.226-executable.jar,并重命名为presto并赋予可以执行权限
https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.226/presto-cli-0.226-executable.jar
2.复制客户端到所有主机上
scp -r -P53742 /home/t3cx/presto-cli-0.226-executable.jar root@incubator-t3-dc-005:/opt/cloudera/parcels/presto/etc/
3.复制客户端到所有主机上
cd /opt/cloudera/parcels/presto/etc/
mv presto-cli-0.226-executable.jar presto
chmod +x presto 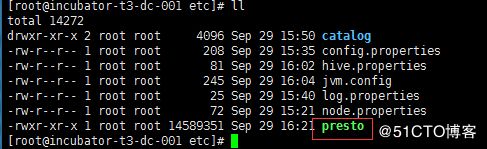
3.集群启用了Sentry,这里我们使用presto用户访问Hive所以为presto用户授权default库的所有权限
4.Hive创建角色并授权
#beeline
#!connect jdbc:hive2://incubator-t3-dc-001:10000/;user=hive;password=****
create role presto;
grant role presto to group presto;
grant ALL on database default to role presto;
5.impala创建角色并授权
su hive
#impala-shell -i incubator-t3-dc-002
create role presto;
grant role presto to group presto;
grant ALL on database default to role presto;
执行查询语句
[root@incubator-t3-dc-001 etc]# ./presto --server localhost:6660 --catalog hive --schema=default
3.4 Presto集成kudu测试
添加kudu配置分发到所有节点上面
# vim /opt/cloudera/parcels/presto/etc/catalog/kudu.properties
connector.name=kudu
kudu.client.master-addresses=incubator-t3-dc-001:7051,incubator-t3-dc-002:7051,incubator-t3-dc-003:7051
#重启服务
/opt/cloudera/parcels/presto/bin/launcher restart
#验证kudu
select * from kudu.default."default.test_kudu_table"3.5 Presto集成ldap
#apacheds安装ldaps
groupadd apacheds
#添加用户组
useradd -s /bin/sh -g apacheds apacheds
添加用户
wget http://mirrors.ocf.berkeley.edu/apache//directory/apacheds/dist/2.0.0.AM25/apacheds-2.0.0.AM25-64bit.bin
#下载授权
chmod +x apacheds-2.0.0.AM25-64bit.bin
./apacheds-2.0.0.AM25-64bit.bin
#启动
/etc/init.d/apacheds-2.0.0.AM25-default start
[root@incubator-t3-dc-002 presto_hue]# netstat -anplt |grep 10389
tcp 0 0 0.0.0.0:10389 0.0.0.0:* LISTEN 24770/java #配置用户名和密码,ip地址
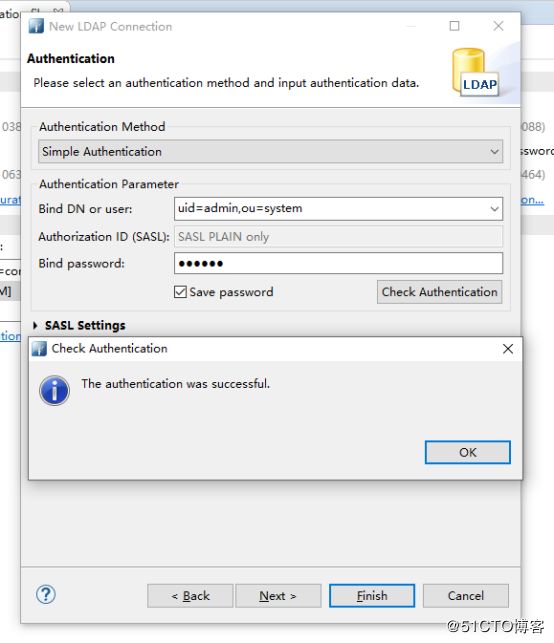
设置用户名密码,默认:user:uid=admin,ou=system password:secret
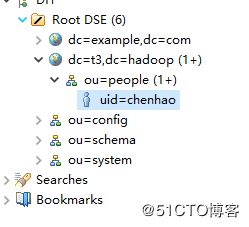
#连接客户端
配置客户端远程登录,这里使用Apache Directory Studio,配置界面如下
打开配置-添加分区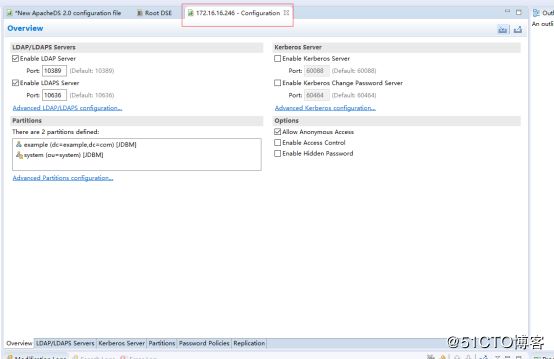

Ctrl+S保存
重启服务
[root@incubator-t3-dc-002 presto_hue]# /etc/init.d/apacheds-2.0.0.AM25-default restart
Stopping ApacheDS - default...
Stopped ApacheDS - default.
Starting ApacheDS - default...
[root@incubator-t3-dc-002 presto_hue]# 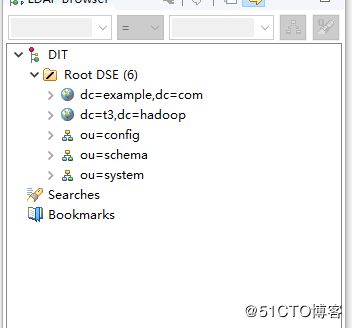
添加组

添加

#添加用户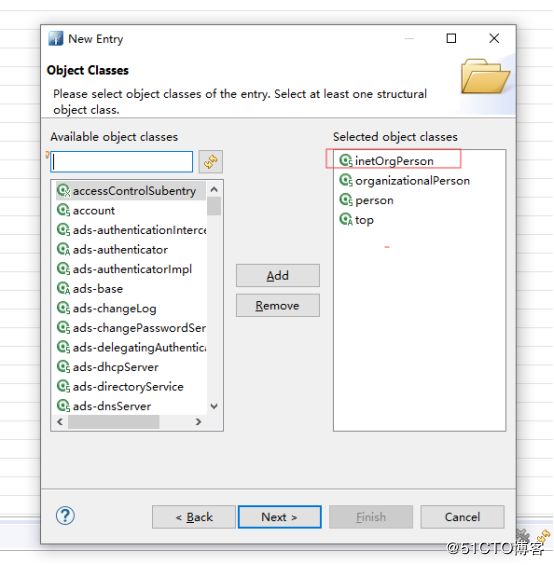

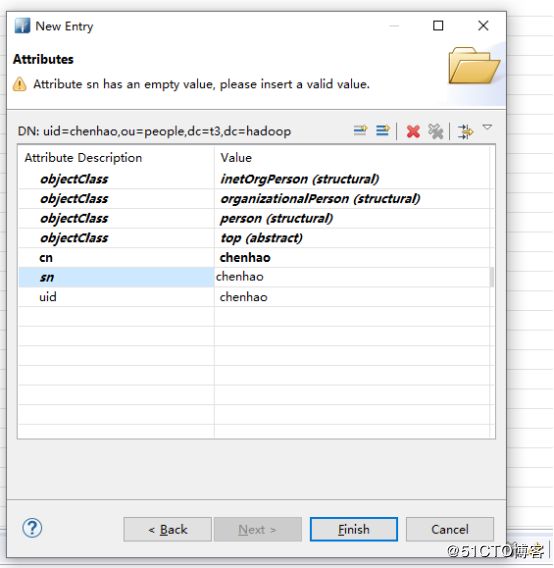
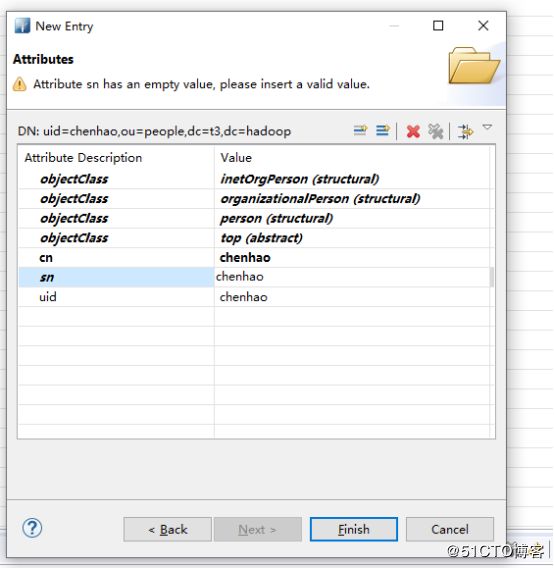
#启用ldaps
cd /var/lib/apacheds-2.0.0.AM25/default/conf/
密码:t3CDH123!
/opt/jdk1.8.0_181/bin/keytool -genkeypair -alias apacheds -keyalg RSA -validity 7 -keystore ads.keystore
chown apacheds:apacheds ./ads.keystore
#配置apacheds.cer
/opt/jdk1.8.0_181/bin/keytool -export -alias apacheds -keystore ads.keystore -rfc -file apacheds.cer
#默认口令
changeit
## 将证书导入系统证书库,实现自认证,这里的密钥库口令是默认的: /opt/jdk1.8.0_181/bin/keytool -import -file apacheds.cer -alias apacheds -keystore /usr/java/jdk1.8.0_181-cloudera/jre/lib/security/cacerts
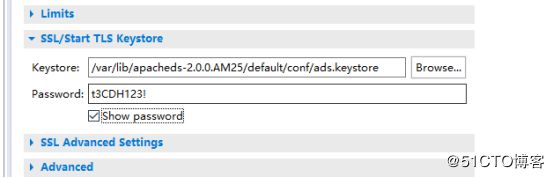
#配置证书
/var/lib/apacheds-2.0.0.AM25/default/conf/ads.keystore
/etc/init.d/apacheds-2.0.0.AM25-default restart
配置客户端

![]()
#测试presto-ldaps
cd /data/presto-server-0.228/etc
/opt/jdk1.8.0_181/bin/keytool -genkeypair -alias presto -keyalg RSA -keystore presto.jks
修改config.properties,添加
http-server.authentication.type=PASSWORD
http-server.https.enabled=true
http-server.https.port=8443
http-server.https.keystore.path=/data/presto-server-0.228/etc/presto.jks
http-server.https.keystore.key=t3CDH123!
# vi password-authenticator.properties
password-authenticator.name=ldap
ldap.url=ldaps://172.16.16.246:10636
ldap.user-bind-pattern=uid=${USER},ou=people,dc=t3,dc=hadoop
ldap.user-base-dn=dc=t3,dc=hadoop3.6 Alluxio 内存存储系统部署安装
下载并解压
wget https://downloads.alluxio.io/downloads/files/2.0.1/alluxio-2.0.1-bin.tar.gz
cp conf/alluxio-site.properties.template conf/alluxio-site.properties拷贝软件到所有节点
scp -r -P53742 /opt/cloudera/parcels/alluxio/ root@incubator-t3-dc-002:/opt/cloudera/parcels/
cd /opt/cloudera/parcels/alluxio/alluxio-2.0.1
cp conf/alluxio-site.properties.template conf/alluxio-site.properties修改配置(集群所有机器)
vim alluxio-site.properties
alluxio.master.hostname=172.16.16.241
vim alluxio-site.properties
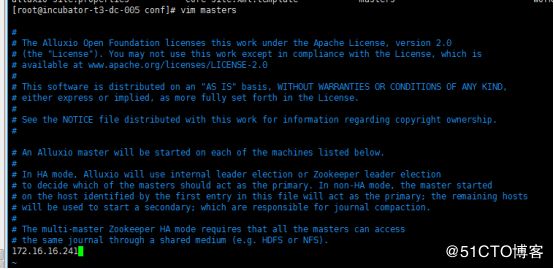
更新conf/alluxio-site.properties中的alluxio.master.hostname为你将运行Alluxio Master的机器的主机名。添加所有worker节点的IP地址到conf/workers文件
alluxio.home=/opt/cloudera/parcels/alluxio/alluxio-2.0.1
alluxio.work.dir=/opt/cloudera/parcels/alluxio/alluxio-2.0.1
alluxio.conf.dir=${alluxio.home}/conf
alluxio.logs.dir=${alluxio.home}/logs
alluxio.master.mount.table.root.ufs=hdfs://incubator-t3-dc-001:8020/alluxio
#hdfs挂载地址
alluxio.metrics.conf.file=${alluxio.conf.dir}/metrics.properties
alluxio.master.hostname=incubator-t3-dc-001
alluxio.underfs.address=hdfs://incubator-t3-dc-001:8020/alluxio
alluxio.underfs.hdfs.configuration=/etc/hadoop/conf/core-site.xml
alluxio.master.bind.host=172.16.16.241
alluxio.master.journal.folder=/opt/cloudera/parcels/alluxio/alluxio-2.0.1/journal
alluxio.master.web.bind.host=172.16.16.241
alluxio.master.web.hostname=incubator-t3-dc-001
alluxio.master.web.port=6661
alluxio.worker.bind.host=0.0.0.0
alluxio.worker.memory.size=2048MB
alluxio.worker.tieredstore.levels=1
alluxio.worker.tieredstore.level0.alias=MEM
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk
JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
alluxio.user.network.netty.timeout.ms=600000
alluxio.master.security.impersonation.presto.users=*
#scp所有机器
scp -r -P53742 alluxio-site.properties root@incubator-t3-dc-002:/opt/cloudera/parcels/alluxio/alluxio-2.0.1/conf/
scp -r -P53742 alluxio-masters.sh alluxio-workers.sh alluxio-start.sh root@incubator-t3-dc-002:/opt/cloudera/parcels/alluxio/alluxio-2.0.1/bin![]()

vim workers
172.16.16.246
172.16.16.250
172.16.16.242
172.16.16.249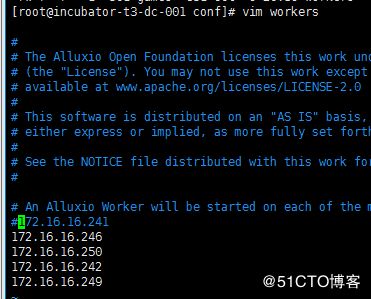
cp -rf alluxio-env.sh.template alluxio-env.sh
vim alluxio-env.sh(所有机器)
#添加
export ALLUXIO_SSH_OPTS="-p 53742"
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
cd /opt/cloudera/parcels/alluxio/alluxio-2.0.1/bin
vim alluxio-masters.sh
添加-p 53742
cd /opt/cloudera/parcels/alluxio/alluxio-2.0.1/bin
vim alluxio-workers.sh
搜索ssh
添加-p 53742

[root@incubator-t3-dc-001 bin]# ln -s /opt/jdk1.8.0_181/bin/java /usr/bin/java
[root@incubator-t3-dc-001 bin]# /usr/bin/java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
[root@incubator-t3-dc-001 bin]#
./alluxio format
报错需要在所有节点
创建mkdir -p /mnt/ramdisk/alluxioworker
如果不创建会报如下错误。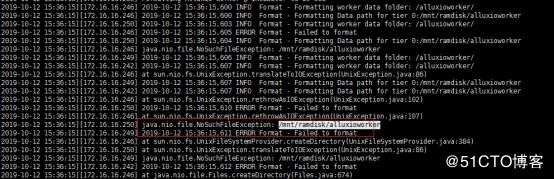
初始化alluxio
cd /opt/cloudera/parcels/alluxio/alluxio-2.0.1/bin
[root@incubator-t3-dc-001 bin]# ./alluxio format
Executing the following command on all worker nodes and logging to /opt/cloudera/parcels/alluxio/alluxio-2.0.1/logs/task.log: /opt/cloudera/parcels/alluxio/alluxio-2.0.1/bin/alluxio formatWorker
Waiting for tasks to finish...
All tasks finished
Executing the following command on all master nodes and logging to /opt/cloudera/parcels/alluxio/alluxio-2.0.1/logs/task.log: /opt/cloudera/parcels/alluxio/alluxio-2.0.1/bin/alluxio formatJournal
Waiting for tasks to finish...
All tasks finished启动alluxio
./alluxio-start.sh all NoMountalluxio-start.sh
./alluxio-start.sh all SudoMount
http://172.16.16.241:6661/overview测试
[root@incubator-t3-dc-001 bin]# echo "1.txt">1.txt
[root@incubator-t3-dc-001 bin]# ll
total 68
-rw-r--r-- 1 root root 6 Oct 14 20:27 1.txt
-rwxrwxrwx 1 501 games 11808 Oct 12 14:35 alluxio
-rwxrwxrwx 1 501 games 2758 Oct 12 14:38 alluxio-masters.sh
-rwxrwxrwx 1 501 games 9668 Oct 14 20:06 alluxio-monitor.sh
-rwxrwxrwx 1 501 games 5591 Aug 23 12:52 alluxio-mount.sh
-rwxrwxrwx 1 501 games 18761 Oct 14 20:06 alluxio-start.sh
-rwxrwxrwx 1 501 games 3806 Aug 23 12:52 alluxio-stop.sh
-rwxrwxrwx 1 501 games 2128 Oct 14 19:48 alluxio-workers.sh
[root@incubator-t3-dc-001 bin]# chmod 777 1.txt
[root@incubator-t3-dc-001 bin]# ./alluxio fs copyFromLocal 1.txt /
Copied file:///opt/cloudera/parcels/alluxio/alluxio-2.0.1/bin/1.txt to /
上传文件到alluxio
cd /opt/cloudera/parcels/alluxio/alluxio-2.0.1/bin
#alluxio文件固化到HDFS
./alluxio fs persist /1.txt
hadoop fs -ls /alluxio

3.7 Alluxio 集成presto
在hive-core-site.xml添加
在hive-core-site.xml添加
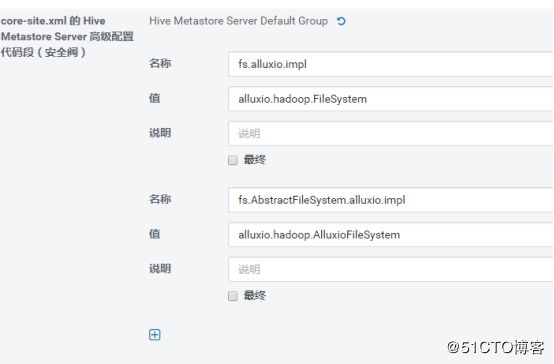
配置core-site.xml
你需要向你的hive.properties指向的core-site.xml中添加以下配置项:
fs.alluxio.impl alluxio.hadoop.FileSystem
fs.AbstractFileSystem.alluxio.impl alluxio.hadoop.AlluxioFileSystem
The Alluxio AbstractFileSystem (Hadoop 2.x)

hive-site.xml
alluxio.user.file.writetype.default CACHE_THROUGH
修改jvm.properties
修改alluxio-site.properties
另外,你也可以将alluxio-site.properties的路径追加到Presto JVM配置中,该配置在Presto目录下的etc/jvm.config文件中。该方法的好处是只需在alluxio-site.properties配置文件中设置所有Alluxio属性。
-Xbootclasspath/p:/opt/cloudera/parcels/alluxio/alluxio-2.0.1/
#所有work节点必须添加
此外,我们建议提高alluxio.user.network.netty.timeout.ms的值(比如10分钟),来防止读异地大文件时的超时问题。
Create a Hive table on Alluxio
Create a Hive table on Alluxio
Here is an example to create an internal table in Hive backed by files in Alluxio. You can download a data file (e.g., ml-100k.zip) from http://grouplens.org/datasets/movielens/. Unzip this file and upload the file u.user into /ml-100k/ on Alluxio:
# ./bin/alluxio fs mkdir /ml-100k
Successfully created directory /ml-100k
# ./bin/alluxio fs copyFromLocal /opt/cloudera/parcels/alluxio/alluxio-2.0.1/ml-100k/u.user alluxio://incubator-t3-dc-001:19998/ml-100k
Copied file:///opt/cloudera/parcels/alluxio/alluxio-2.0.1/ml-100k/u.user to alluxio://incubator-t3-dc-001:19998/ml-100kHive create table
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> CREATE TABLE u_user (
> userid INT,
> age INT,
> gender CHAR(1),
> occupation STRING,
> zipcode STRING)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '|'
> LOCATION 'alluxio://incubator-t3-dc-001:19998/ml-100k';
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:java.lang.RuntimeException: java.lang.ClassNotFoundException: Class alluxio.hadoop.FileSystem not found)集成hive
#第一步环境变量
export HIVE_AUX_JARS_PATH=/opt/cloudera/parcels/alluxio/alluxio-2.0.1/client/alluxio-2.0.1-client.jar:${HIVE_AUX_JARS_PATH}
#拷贝java路径
cp -rf /opt/cloudera/parcels/alluxio/alluxio-2.0.1/client/alluxio-2.0.1-client.jar /opt/cloudera/parcels/CDH/lib/hive/lib
#权限
chmod 777 /opt/cloudera/parcels/CDH/lib/hive/lib/alluxio-2.0.1-client.jar
重启hive服务集成hdfs
# cp -rf /opt/cloudera/parcels/alluxio/alluxio-2.0.1/client/alluxio-2.0.1-client.jar /opt/cloudera/parcels/CDH/lib/hadoop-hdfs/lib/
[root@incubator-t3-dc-001 lib]# chmod 777 /opt/cloudera/parcels/CDH/lib/hadoop-hdfs/lib/alluxio-2.0.1-client.jar
重启hdfs服务测试hive集成
#切换hive用户
cubator-t3-dc-001:19998, Error: alluxio.exception.status.UnauthenticatedException: Plain authentication failed: Failed to authenticate client user="hive" connecting to Alluxio server and impersonating as impersonationUser="root" to access Alluxio file system. User "hive" is not configured to allow any impersonation. Please read the guide to configure impersonation at https://docs.alluxio.io/os/user/2.0/en/advanced/Security.html)
su hive
重新创建表
hive> CREATE TABLE u_user (
> userid INT,
> age INT,
> gender CHAR(1),
> occupation STRING,
> zipcode STRING)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '|'
> LOCATION 'alluxio://incubator-t3-dc-001:19998/ml-100k';
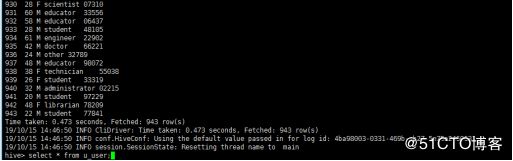
#创建表
create EXTERNAL table rating_alluxio(
userId INT,movieId INT,
rating FLOAT,
timestamps STRING)
row format delimited fields terminated by ','
LOCATION 'alluxio://incubator-t3-dc-001:19998/ml-100k';使用presto查询表
需要关联java包,否则会报错
使用 Presto 查询表,关联java包,重启服务
cp -rf /opt/cloudera/parcels/alluxio/alluxio-2.0.1/client/alluxio-2.0.1-client.jar /opt/cloudera/parcels/presto/lib/
chmod 777 /opt/cloudera/parcels/presto/lib/alluxio-2.0.1-client.jar
#复制客户端到presto-hive里面
复制Alluxio client jar
cp -rf /opt/cloudera/parcels/alluxio/alluxio-2.0.1/client/alluxio-2.0.1-client.jar /opt/cloudera/parcels/presto/plugin/hive-hadoop2/
重启presto
/opt/cloudera/parcels/presto/bin/launcher restart
#查询表
./presto --server localhost:6660 --execute "use default;select * from u_user limit 10;" --catalog hive --debugtext_QDUxQ1RP5Y2a5a6i,color_FFFFFF,t_100,g_se,x_10,y_10,shadow_90,type_ZmFuZ3poZW5naGVpdGk=)
Failed to authenticate client user="root" connecting to Alluxio server and impersonating as impersonationUser="presto" to access Alluxio file system.
#master机器
vim alluxio/alluxio-2.0.1/conf/alluxio-site.properties
alluxio.master.security.impersonation.root.users=*
#添加用户到site里面然后重启alluxio服务
完全禁用客户端模拟机制。这就需要将客户端配置参数(不在服务器上)作如下设置:
alluxio.security.login.impersonation.username=NONE
正确显示
4.1Zeppelin
Apache Zeppelin 是一个让交互式数据分析变得可行的基于网页的开源框架。Zeppelin提供了数据分析、数据可视化等功能。
Zeppelin 是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell。
4.2 zeppelin部署
在机器上安装zeppelin
#zeppelin安装
cd /opt/cloudera/parcels/zeppelin
tar zxvf zeppelin-0.8.2-bin-all.tgz#修改端口
vim /opt/cloudera/parcels/zeppelin/zeppelin-0.8.2-bin-all/conf/zeppelin-env.sh
export ZEPPELIN_PORT=80
export ZEPPELIN_ADDR=172.16.16.241
禁止匿名登陆
[root@incubator-t3-dc-001 conf]# cp -rf shiro.ini.template shiro.ini
[root@incubator-t3-dc-001 conf]# cp -rf zeppelin-site.xml.template zeppelin-site.xml
vim zeppelin-site.xml
#禁止匿名登录
修改zeppelin.anonymous.allowed属性为false
zeppelin.anonymous.allowed
false
Anonymous user allowed by default
集成ldap
#配置ldap
vim shiro.ini
[main]
ldapRealm=org.apache.zeppelin.realm.LdapRealm
ldapRealm.contextFactory.authenticationMechanism=simple
ldapRealm.contextFactory.url=ldap://172.16.16.245:389
ldapRealm.userDnTemplate=uid={0},ou=People,dc=t3,dc=com
ldapRealm.pagingSize = 200
ldapRealm.authorizationEnabled=true
ldapRealm.searchBase= dc=t3,dc=com
ldapRealm.userSearchBase = ou=People,dc=t3,dc=comd
ldapRealm.groupSearchBase = ou=group,dc=t3,dc=com
ldapRealm.groupObjectClass= posixGroup
ldapRealm.userLowerCase = true
ldapRealm.userSearchScope = subtree;
ldapRealm.groupSearchScope = subtree;
ldapRealm.contextFactory.systemUsername= cn=Manager,dc=t3,dc=com
ldapRealm.contextFactory.systemPassword= CFXZ6EU3bCpIMFpFZX0LqjEq
ldapRealm.groupSearchEnableMatchingRuleInChain = true
ldapRealm.rolesByGroup = group: admin
#关联组合admin角色
sessionManager = org.apache.shiro.web.session.mgt.DefaultWebSessionManager
cookie = org.apache.shiro.web.servlet.SimpleCookie
cookie.name = JSESSIONID
cookie.httpOnly = true
sessionManager.sessionIdCookie = $cookie
securityManager.sessionManager = $sessionManager
securityManager.sessionManager.globalSessionTimeout = 86400000
shiro.loginUrl = /api/login
[roles]
role1 = *
role2 = *
role3 = *
admin = *
[urls]
/api/version = anon
/api/interpreter/setting/restart/** = authc
/api/interpreter/** = authc, roles[admin]
/api/configurations/** = authc, roles[admin]
/api/credential/** = authc, roles[admin]
#/** = anon
/** = authcLdap和用户认证只能二选一
#权限认证
其中的[users]部分,即登录时的账号。等号前是用户名,等号后是密码,逗号后是用户的角色。账号可以不定义角色,也可以定义多个角色。
比如用户名user1,对应密码password2,拥有角色role1和role2。
[users]
admin = t, admin
bi_wkx = bi_wkx, read, write
bi_ch = bi_ch, read, write
bi_fyc = bi_fyc read, write[roles]配置用户的角色,[urls]部分配置不同web接口的认证方式和需要的角色,
/表示任意路径,验证时按照定义顺序匹配,所以/一般放在最后一行。
比如,下面的配置定义了4种角色。接口version验证方式anon,即不需要验证,不用登录就能访问。
接口interperter需要表格形式的验证,且用户具有admin角色才能访问。/** = authc表示其他接口只需要登录验证即可访问,
不需要用户有额外的角色。
[roles]
admin = *
read = *
write = *
[urls]
# anon means the access is anonymous.
# authcBasic means Basic Auth Security
# authc means Form based Auth Security
/api/version = anon
/api/interpreter/** = authc, roles[admin]
/api/credentail/** = authc, roles[admin]
/api/configurations/** = authc, roles[admin]
/** = authc
重启服务
sh ../bin/zeppelin-daemon.sh restart集成zeppelin各插件
#zeppelin配置hive
配置文件vim zeppelin-env.sh:在文件末尾添加以下配置,根据自己的路径设置。
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
export MASTER=yarn-client
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop
export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark
export HIVE_HOME=/opt/cloudera/parcels/CDH/lib/hive
export IMPALA_HOME=/opt/cloudera/parcels/CDH/lib/impala
export HADOOP_CONF_DIR=/etc/hadoop/conf
export ZEPPELIN_LOG_DIR=/opt/cloudera/parcels/zeppelin/zeppelin-0.8.2-bin-all/log
export ZEPPELIN_PID_DIR=/opt/cloudera/parcels/zeppelin/zeppelin-0.8.2-bin-all/run/
export ZEPPELIN_WAR_TEMPDIR=/var/tmp/zeppelin
#配置zeppelin 页面
common.max_count 1000
hive.driver org.apache.hive.jdbc.HiveDriver
hive.password hive
hive.url jdbc:hive2://incubator-t3-dc-003:10000
hive.user hive
zeppelin.interpreter.localRepo /opt/cloudera/parcels/zeppelin/zeppelin-0.8.2-bin-all/local-repo/helium-registry-cache
zeppelin.interpreter.output.limit 102400
zeppelin.jdbc.auth.type
zeppelin.jdbc.concurrent.max_connection 10
zeppelin.jdbc.concurrent.use true
zeppelin.jdbc.keytab.location
zeppelin.jdbc.principal
Dependencies
artifact exclude
org.apache.hive:hive-jdbc:2.1.1 hive-jdbc-2.1.1-cdh6.3.0.jar
org.apache.hadoop:hadoop-common:3.0.0 hadoop-common-3.0.0-cdh6.3.0.jar
mysql:mysql-connector-java:5.1.47 mysql-connector-java-5.1.47.jar

新建一个作业进行测试
notebook --> Create new node填写名称,选择hive即可
输入查询语句,注意查询语句前需要有前缀(hive):
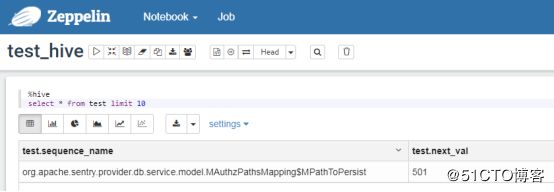
%hive
select * from test limit 10
语句末尾不能加分号,不然会有错误。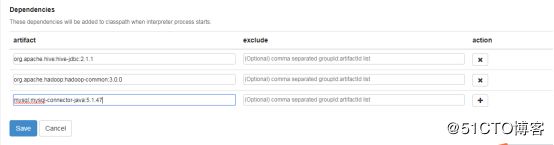

#python集成
%python
import sys
sys.version
语句末尾不能加分号,不然会有错误。
#impala
新建;jdbc_impala
default.driver = org.apache.hive.jdbc.HiveDriver
default.url = jdbc:hive2://incubator-t3-dc-003:21050/default;auth=noSasl(验证模式是NOSASL才能正常使用impala,但是这个会让impala查询数据时,跳过rander中设置的掩码规则)
default.user = zeppelin
url 的 NOSASL模式需要任意一个用户名(如Hive),不需要密码,不填写用户名会报错。
Dependencies
artifact exclude
org.apache.hive:hive-jdbc:2.1.1 hive-jdbc-2.1.1-cdh6.3.0.jar
org.apache.hadoop:hadoop-common:3.0.0 hadoop-common-3.0.0-cdh6.3.0.jar
mysql:mysql-connector-java:5.1.47 mysql-connector-java-5.1.47.jar
#impala测试
%impala
select * from nation limit 10#spark
local[*] in local mode
yarn-client in Yarn client mode
yarn-cluster in Yarn cluster mode
#修改hdfs参数
dfs.permissions.superusergroup=supergroup,root
![]()
%sql
show databases
#presto
presto %jdbc (default)
%presto
select * from kudu.default."default.test_kudu_table" limit 10
Option Shared
Properties
name value
default.driver com.facebook.presto.jdbc.PrestoDriver
default.url jdbc:presto://172.16.16.241:6660
default.user root
default.passwd 密码
zeppelin.jdbc.concurrent.max_connection 10
zeppelin.jdbc.concurrent.use true
Dependencies
artifact exclude
com.facebook.presto:presto-jdbc:0.170
cd /opt/cloudera/parcels/zeppelin/zeppelin-0.8.2-bin-all/interpreter/jdbc
rz presto-jdbc-0.226.jar
5.1 rancher
Rancher是一个开源的企业级容器管理平台。通过Rancher,企业再也不必自己使用一系列的开源软件去从头搭建容器服务平台。Rancher提供了在生产环境中使用的管理Docker和Kubernetes的全栈化容器部署与管理平台。
为什么需要Rancher
在原来, 如果我们需要做一个分布式集群我们需要学习一全套的框架并编码实现如 服务发现, 负载均衡等逻辑, 给开发者造成很大的负担, 不过好在现在有Docker以及他周边的一些技术能在上层解决这些问题, 而应用该怎么开发就怎么开发.
当你选择使用Docker技术栈的时候, 会发现在生产环境中不光光是 docker run就能解决的. 还需要考虑比如docker之间的组网, 缩扩容等问题, 于是你去学习kubernetes, 发现好像有点复杂啊, 有没有更傻瓜化一点的? 那就是rancher了.
5.2 rancher部署zeppelin
#安装docker
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sudo yum makecache fast
yum list docker-ce --showduplicates | sort -r
sudo yum install docker-ce-17.12.0.ce-1.el7.centos
docker version
docker pull rancher/server
netstat -anplt | grep 8000
# Error starting daemon: error initializing graphdriver: devmapper: Base Device UUID and Filesystem veri(报错)
systemctl stop docker (停止docker 服务)
dmsetup udevcomplete_all (释放未完成的磁盘操作)
sudo rm -rf /var/lib/docker/* (清空docker 数据)
* reboot (注:当有镜像或容器文件删除不了时,重启服务器)
systemctl start docker (重启docker服务)
以下是创建数据库和数据库用户的SQL命令例子
#创建rancher数据库
CREATE DATABASE IF NOT EXISTS cattle COLLATE = 'utf8_general_ci' CHARACTER SET = 'utf8';
GRANT ALL ON cattle.* TO 'cattle'@'%' IDENTIFIED BY 'cattle';
GRANT ALL ON cattle.* TO 'cattle'@'localhost' IDENTIFIED BY 'cattle';
启动一个Rancher连接一个外部数据库,你需要在启动容器的命令中添加额外参数。
#启动rancher
docker run -d --restart=unless-stopped -p 80:8080 rancher/server \
--db-host incubator-t3-dc-001 --db-port 3306 --db-user cattle --db-pass cattle --db-name cattle
docker search nginx
docker pull docker.io/nginx
docker images
#启动rancher
docker run --name rancher -d -p 80:8080 rancher/server
docker start 9b04ff050ddd
为了安全可以给Rancher配置登录账号(选择 系统管理 --》访问控制 --》LOCAL)-添加本地账号
管理员 admin admin
#安装zeppelin
docker pull apache/zeppelin:0.8.2
docker volume create zeppelin-logs
docker volume create zeppelin-notebook
3.启动zeppelin
docker run -d -p 80:8081 \
-v zeppelin-logs:/logs \
-v zeppelin-notebook:/notebook \
--env HOST_IP=0.0.0.0 \
--env ZEPPELIN_LOG_DIR='/logs' \
--env ZEPPELIN_NOTEBOOK_DIR='/notebook' \
--volume /etc/localtime:/etc/localtime \
--restart=always \
--name zeppelin apache/zeppelin:0.8.25.3 rancher集成ldap认证
http://172.16.16.241/admin/access/openldap
设置ldap用户
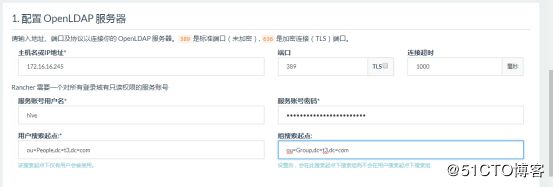
组:ou=Group,dc=t3,dc=com
用户:ou=People,dc=t3,dc=com
域:172.16.16.245
端口:389
#设置
常规
服务器: 172.16.16.245:389
TLS: No
服务账号: cn=Manager,dc=t3,dc=com
Connection Timeout: 1000毫秒
用户
搜索起点: ou=People,dc=t3,dc=com
对象分类: posixAccount
登录字段: uid
名称字段: givenName
搜索字段: uid
启用字段:
必须创建api
到此实战结束。
大数据运维更多技巧和技术
CDH+Ambari实战
带你搞定大数据运维
详情在《大数据安全运维实战》
大数据安全运维实战
扫码加入大数据运维大家庭共同学习进步。
学习专栏你能收获什么?
专栏以CDH和ambari二个大数据平台为主,内容全都是笔者多年的工作中提炼出来的,不仅包含了大数据的基本知识,最主要的是大数据安全维领域的常见案例和实战技巧,借以本专栏分享给大家,希望大家通过学习,能够解决在日常工作中所遇到的问题,提高自己的工作效率,收获满满。
最后的最后,希望每一个学习我专栏的小伙伴,能够转型成功,升职加薪!