前言
BlueStore中的对象非常类似于文件系统中的文件,每个对象在BlueStore中拥有唯一的ID、大小、从0开始逻辑编址、支持扩展属性等,因此对象的组织形式,类似于文件也是基于Extent。
目录
- 稀疏写
- 名词解释
- onode结构
- PExtent
- LExtent
- Blob
- big-write
- small-write
- simple-write
- deferred-write
- IO流程
1.稀疏写
我们知道一个文件的逻辑空间上是连续的,但是真正在磁盘上的物理空间分布并不一定是连续的。同时我们也会使用lseek系统调用,可以指定文件偏移位置,此时再对文件写入,便会在文件中形成一个空洞,这些空洞中的字节都是0。空洞是否占用磁盘空间是有文件系统决定的,不过大部分的文件系统ext4、xfs都不占磁盘空间。我们称部分数据是0同时这部分数据不占磁盘空间的文件为稀疏文件,这种写入方式为稀疏写。
BlueStore中的对象也支持稀疏写,同时支持克隆等功能,所以对象的数据组织结构设计的会相对复杂一点。
2.名词解释
Collection:PG在内存的数据结构。
bluestore_cnode_t:PG在磁盘的数据结构。
Onode:对象在内存的数据结构。
bluestore_onode_t:对象在磁盘的数据结构。
Extent:一段对象逻辑空间(lextent)。
extent_map_t:一个对象包含多段逻辑空间。
bluestore_pextent_t:一段连续磁盘物理空间。
bluestore_blob_t:一片不一定连续的磁盘物理空间,包含多段pextent。
Blob:包含一个bluestore_blob_t、引用计数、共享blob等信息。
3.Onode结构
BlueStore的每个对象对应一个Onode结构体,每个Onode包含一张extent-map,extent-map包含多个extent(lextent),每个extent负责管理对象内的一个逻辑段数据并且关联一个Blob,Blob包含多个pextent,最终将对象的数据映射到磁盘上。
BlueStore的对象内部结构如下图:
onode
数据结构主要包含两部分:内存数据结构、磁盘数据结构。
Onode本身和FileStore的对象一样,主要包含四部分:数据、扩展属性、omap头部、omap条目。
omap和扩展属性很类似,只不过扩展属性大小有限制,omap没有限制。BlueStore把扩展属性和Onode一起保存,omap分开保存。
// 内存数据结构
struct Onode {
// reference count
std::atomic_int nref;
// onode 对应的PG
Collection *c;
// onode磁盘数据结构
bluestore_onode_t onode;// metadata stored as value in kv store
// 有序的Extent逻辑空间集合,持久化在RocksDB。lexetnt--->blob
//
// 由于支持稀疏写,所以extent map中的extent可以是不连续的,即存在空洞。
// 也即前一个extent的结束地址小于后一个extent的起始地址。
//
// 如果单个对象内的extent过多(小块随机写多、磁盘碎片化严重)
// 那么ExtentMap会很大,严重影响RocksDB的访问效率
// 所以需要对ExtentMap分片即shard_info,同时也会合并相邻的小段。
// 好处可以按需加载,减少内存占用量等。
ExtentMap extent_map;
......
}
// 磁盘数据结构 onode: per-object metadata
struct bluestore_onode_t {
// 逻辑ID,单个BlueStore内部唯一。
uint64_t nid = 0;
// 对象大小
uint64_t size = 0;
// 对象扩展属性
map attrs;
......
} 4.PExtent
每段pextent对应一段连续的磁盘物理空间,结构体为bluestore_pextent_t。
struct bluestore_pextent_t {
// 磁盘上的物理偏移
uint64_t offset = 0;
// 数据段的长度
uint32_t length = 0;
}pextent的offset和length都是块大小对齐的。
5.LExtent
Extent是对象内的基本数据管理单元,数据压缩、数据校验、数据共享等功能都是基于Extent粒度实现的。这里的Extent是对象内的,并不是磁盘内的,所以我们称为lextent,和磁盘内的pextent以示区分。
struct Extent {
// 对象内逻辑偏移,不需要块对齐。
uint32_t logical_offset = 0;
// 逻辑段长度,不需要块对齐。
uint32_t length = 0;
// 当logical_offset是块对齐时,blob_offset始终为0;
// 不是块对齐时,将逻辑段内的数据通过Blob映射到磁盘物理段会产生物理段内的偏移称为blob_offset。
uint32_t blob_offset = 0;
}logical_offset、length、blob_offset关系如下图: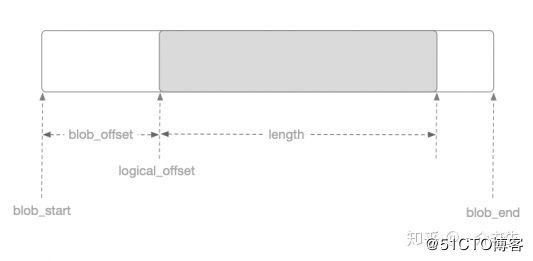
6.Blob
Blob包含磁盘上物理段的集合,即bluestore_pextent_t的集合。
/// in-memory blob metadata and associated cached buffers (if any)
struct Blob {
// reference count
std::atomic_int nref = {0};
mutable bluestore_blob_t blob;///< decoded blob metadata
SharedBlobRef shared_blob; ///< shared blob state (if any)
}
/// blob: a piece of data on disk
struct bluestore_blob_t {
PExtentVector extents; ///< raw data position on device
}
typedef mempool::bluestore_cache_other::vector PExtentVector; 7.big-write
我们知道磁盘的最小分配单元是min_alloc_size,HDD默认64K,SSD默认16K。
bluestore_min_alloc_size_hdd: 64K
bluestore_min_alloc_size_ssd: 16K
对齐到min_alloc_size的写我们称为大写(big-write),在处理时会根据实际大小生成lextent、blob,lextent包含的区域是min_alloc_size的整数倍,如果lextent是之前写过的,那么会将之前lextent对应的空间记录下来并回收。
void BlueStore::_do_write_big(TransContext *txc, CollectionRef &c, OnodeRef o,
uint64_t offset, uint64_t length,
bufferlist::iterator &blp, WriteContext *wctx) {
......
bufferlist t;
blp.copy(l, t);
wctx->write(offset, b, l, b_off, t, b_off, l, false, new_blob);
......
}8.small-write
落在min_alloc_size区间内的写我们称为小写(small-write)。因为最小分配单元min_alloc_size,HDD默认64K,SSD默认16K,所以如果是一个4KB的IO那么只会占用到blob的一部分,剩余的空间还可以存放其他的数据。所以小写会先根据offset查找有没有可复用的blob,如果没有则生成新的blob。
void BlueStore::_do_write_small(TransContext *txc, CollectionRef &c, OnodeRef o,
uint64_t offset, uint64_t length,
bufferlist::iterator &blp, WriteContext *wctx) {
// Look for an existing mutable blob we can use.
......
// new blob.
BlobRef b = c->new_blob();
uint64_t b_off = p2phase(offset, alloc_len);
uint64_t b_off0 = b_off;
_pad_zeros(&bl, &b_off0, block_size);
o->extent_map.punch_hole(c, offset, length, &wctx->old_extents);
wctx->write(offset, b, alloc_len, b_off0, bl, b_off, length, true, true)
}
BlueStore::queue_transactions()--->BlueStore::_txc_add_transaction()--->Transaction::OP_WRITE:--->BlueStore::_write()--->BlueStore::_do_write()--->_do_write_data|_do_alloc_write在事物的state_prepare阶段会调用_txc_add_transaction方法,把OSD层面的事物转换为BlueStore层面的事物。
- _do_write:创建WriteContext,调用_do_write_data和_do_alloc_write。
- _do_write_data:进行大写和小写,将数据放在WriteContext,此时数据还在内存。
- _do_alloc_write:Allocator分配空间,并调用aio_write将数据提交到Libaio队列。
// bluestore 写操作上下文
struct WriteContext {
......
// 写条目
struct write_item {
uint64_t logical_offset; ///< write logical offset
BlobRef b;
uint64_t blob_length;
uint64_t b_off;
bufferlist bl;
uint64_t b_off0; ///< original offset in a blob prior to padding
uint64_t length0; ///< original data length prior to padding
}
// blobs we're writing
vector writes;
// bluestore大小写都会调用,向writes这个vector里面插入一条write_item。
void write(uint64_t loffs, BlobRef b, uint64_t blob_len, uint64_t o,
bufferlist &bl, uint64_t o0, uint64_t len0,
bool _mark_unused, bool _new_blob) {
writes.emplace_back(loffs, b, blob_len, o, bl, o0, len0,
_mark_unused, _new_blob);
}
_do_write_data--->_do_write_small()|_do_write_big() --->wctx->write() --->writes.emplace_back()--->_do_alloc_write()--->_wctx_finish int BlueStore::_do_alloc_write(
TransContext *txc,
CollectionRef coll,
OnodeRef o,
WriteContext *wctx)
{
for (auto& wi : wctx->writes) {//循环遍历write_item,进行写操作
...
bdev->aio_write(offset, t, &txc->ioc, false);
...
}
}
9.simple-write
BlueStore支持BufferIO也支持Libaio,通常默认使用Libaio,为simple-write和deferred-write抽象了基类AioContext,当IO完成时调用回调函数aio_finish。
struct AioContext {
virtual void aio_finish(BlueStore *store) = 0;
virtual ~AioContext() {}
};simple-write对应的上下文是TransContext,包含对齐覆盖写(COW)和非覆盖写,通常在事物state_prepare阶段将IO分为大小写的时候就已经调用aio_write提交到Libaio队列了,后续会通过_aio_thread线程收割完成的AIO事件。
struct TransContext : public AioContext {
......
void aio_finish(BlueStore *store) override {
store->txc_aio_finish(this); // txc的回调
}
}在处理simple-write时,需要考虑offset、length是否对齐到block_size(4KB)以进行补零对齐的操作。之所以要进行补零对齐和磁盘IO有关。我们知道BlueStore支持BufferIO和Libaio。
- Libaio:使用DIO方式,要求offset、length、data必须是block_size对齐的。
- BufferIO:先写PageCache再Sync磁盘,不要求PageSize对齐。但是如果不对齐,内核在处理非对齐写的时候,会先从磁盘上Read该内存页对应的数据,然后和内存页的数据进行Merge,最后再把内存页的数据Write到磁盘上。也即会进行RMW操作,降低了写入效率。
所以BlueStore在处理数据写入时,需要将数据对齐到block_size,提升写磁盘效率。
10.deferred-write
我们在BlueStore源码分析之架构设计中提到的RMW便是对应BlueStore的deferred-write,对应的结构体便是DeferredBatch。
struct DeferredBatch final : public AioContext {
struct deferred_io {
bufferlist bl; ///< data
uint64_t seq; ///< deferred transaction seq
};
// txcs in this batch
deferred_queue_t txcs;
// aio 完成的回调函数
void aio_finish(BlueStore *store) override {
store->_deferred_aio_finish(osr);
}
}deferred-write在事物state_prepare阶段会将对应的数据写入RocksDB,在之后会进行RMW操作以及CleanupRocksDB中的deferred-write的数据。
// journal deferred items
if (txc->deferred_txn) {
txc->deferred_txn->seq = ++deferred_seq;
bufferlist bl;
encode(*txc->deferred_txn, bl);
string key;
get_deferred_key(txc->deferred_txn->seq, &key);
txc->t->set(PREFIX_DEFERRED, key, bl);
}11.IO流程
具体的IO流程便不在画图,引用ceph存储引擎bluestore解析中的图片。如有侵权,还请联系删除。
参考link:
https://zhuanlan.zhihu.com/p/92397191