ACL 2020 | 腾讯AI Lab解读三大前沿方向及入选的20篇论文
点击上方,选择星标或置顶,不定期资源大放送 !
!
阅读大概需要20分钟
Follow小博主,每天更新前沿干货


来源:腾讯AI实验室
自然语言处理领域顶级会议 ACL 2020 将于 7 月 5 日至 10 日在线上举行。本届 ACL 共接收论文 779 篇,接收率 25.2%。今年腾讯公司共有 30 篇论文入选,位列国内业界 AI 研究机构首位。腾讯 AI Lab 贡献了其中 20 篇论文,涉及对话及文本生成、机器翻译及文本理解等几大重点研究方向,充分展现了其在自然语言处理领域的研究实力。
自然语言理解是腾讯 AI Lab 的主要研究方向之一,研究能力也一直处于业界领先水平。总体而言,腾讯 AI Lab 的研究内容囊括从自然语言理解到生成的整个链条,另外还涉及到对 AI 系统可解释性以及算法底层机制等理论研究。相关研究成果也一直在通过研究论文、开放数据集和开源代码的形式向 NLP 及 AI 社区分享。
同时,腾讯 AI Lab 也在积极探索新技术在实际产品中的应用,涵盖数字人、机器翻译和内容推荐等重要应用领域。举个例子,腾讯 AI Lab 今年 4 月对外开放了自然语言理解系统 TexSmart。该系统提供细粒度命名实体识别、语义联想、深度语义表达等特色功能,在腾讯业务及产品中已达到数千亿次的调用量。
本文将分对话及文本生成、机器翻译、文本理解三大方向对腾讯 AI Lab 入选的 20 篇论文进行简要解读;此外,部分研究的代码和相关数据集也已发布,感兴趣的研究者和实践者可以轻松复现或尝试这些新成果。
方向一:对话及文本生成
在基于自然语言的人机交互以及图像和视频和文本描述等任务中,对话及文本生成是最重要的核心步骤之一,同时这也是近年来 NLP 领域一大核心研究主题。目前,对话及文本生成方面的难题包括生成内容与上下文的一致性、融合常识等知识的方法、如何在保证相关性的同时提供新颖性和趣味性等。本届 ACL 上,腾讯 AI Lab 的相关入选论文涉及对话中的人设保持、固定格式文本生成和对话中的知识融合等多个研究方向。
1. 生成-删除-重写:提升对话人设一致性的三阶段生成模型
Generate, Delete and Rewrite: A Three-stage Framework for Improving Persona Consistency of Dialogue Generation
论文:https://arxiv.org/abs/2004.07672
本文由腾讯 AI Lab 主导,与哈尔滨工业大学合作完成,提出了一种用于在对话中保持个性和人设一致性的新框架。
对人类来说,在对话中保持一致的个性和人设是一件很自然的事情,但对于机器来说这仍是一个遥不可及的目标。因此,研究者们提出了基于人设的对话生成任务,希望通过将明确的角色信息融入到对话生成模型中来实现对话中的人设一致。尽管已经取得了一定的效果,但目前大多数研究里采用的“单阶段”解码框架仍然难以避免生成出与人设不一致的词语。本文提出了一种三阶段生成框架,通过采用生成-删除-重写(GDR)的机制来从生成的回复原型中删除不一致的单词并重写为人设一致的回复。研究者在 Persona-Chat 数据集上进行了实验,结果表明新提出的方法在人工和自动指标上均取得了非常好的表现。相信这能为未来的对话人设一致性研究提供新的思路与方法。
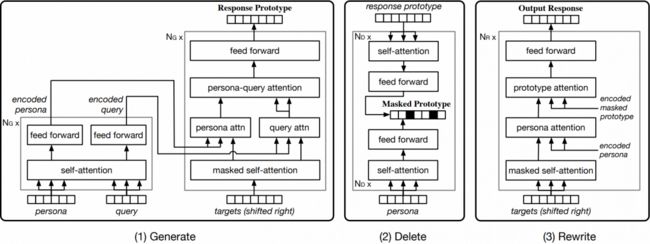
新提出的三阶段 GDR 模型架构示意图
这种三阶段 GDR 模型包含一个原型回复生成器(生成阶段)、一个一致性匹配模型(删除阶段)、一个掩码式原型回复重写器(重写阶段)。
2. 格式控制下的文本生成
Rigid Formats Controlled Text Generation
论文:https://arxiv.org/abs/2004.08022
本文由腾讯 AI Lab 独立完成,提出了一种用于严格格式文本生成的新型框架 SongNet。
基于神经网络的文本生成在各种任务中取得了巨大的进步。大多数任务的一个共同特点是:在生成时,文本不受某些严格格式的限制。但是,我们可能会遇到一些特殊的文本范式,如歌词(例如给定乐谱配词)、十四行诗、宋词等。这些文本的典型特征有以下三个方面:(1)它们必须完全遵守预定的硬性格式。(2)它们必须遵守一定的韵律。(3)虽然受制于一些格式,但必须保证句子的完整性。就我们所知,基于预定义的硬性格式的文本生成还没有得到很好的研究。因此,本文提出了一个简单而优雅的框架 SongNet 来解决这个问题。该框架的骨干是一个基于 Transformer 的自回归语言模型。为了提高建模性能,研究者设计了多种符号来建模格式、韵律和句子的完整性。研究者也改进了注意力机制,促使模型捕捉到一些未来格式的信息。此外,研究者还设计了一个预训练和微调框架来进一步提高生成质量。在两个收集到的语料库上进行的大量实验表明,我们提出的框架在自动指标和人类评价方面都得到了明显更好的结果。
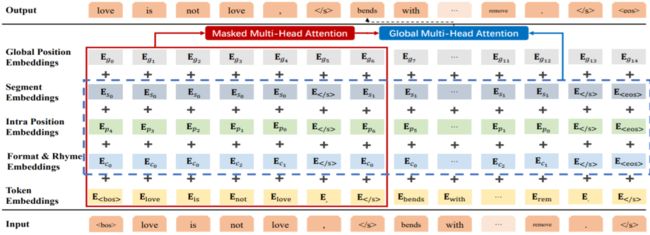
SongNet 模型框架

SongNet 根据给定格式填词(宋词和十四行诗)
SongNet 已在“唱作俱佳”的腾讯 AI 数字人艾灵的歌词生成方案中得到了应用,更多解读可见《唱作俱佳 腾讯AI艾灵领唱中国新儿歌》。
3. 基于“回复预知”存储机制的知识融合型对话生成
Response-Anticipated Memory for On-Demand Knowledge Integration in Response Generation
论文:https://arxiv.org/abs/2005.06128
本文由腾讯 AI Lab 主导,与香港科技大学合作完成,提出了一种“回复预知”的存储机制,使得知识提取与存储过程中可考虑到可能的回复信息,进而提升知识融合型对话系统中回复生成的质量。
众所周知,神经对话模型可以生成不错的回复,但其回复内容往往缺乏信息量。基于阅读的对话模式(Conversing by Reading)可以大大提高回复中的信息量,具体而言,这类模式会基于给定的外部文档中的信息开展对话。在已有的基于阅读对话的工作中,外部文档是通过(1)创建一个上下文感知的文档存储模块来整合来自文档和对话上下文的信息,然后(2)利用该存储模块来帮助生成回复。在本文中,我们认为在构建文档存储模块时,应该考虑“我们可能的回复是什么样的”。具体地,新提出的模型是使用教师-学生框架实现的。我们为教师模型提供了外部文档、上下文和真实的回复,并让教师模型学习了如何从三种信息源中构建“可感知回复”的文档存储模块。学生模型可从外部文档、上下文和教师模型中学习如何构建“回复预知”的文档存储模块。实验结果表明,新提出的模型优于 CbR 任务的其它最新模型。

新提出的模型架构,其中灰色的模块和线条构成了基础模型,蓝色和灰色部分是教师模型,紫色部分则是学生模型。训练阶段会用到所有组件,而推理阶段仅需学生模型和解码器。
4. 运用批标准化的变分网络防止KL散度消失
A Batch Normalized Inference Network Keeps the KL Vanishing Away
论文:https://arxiv.org/abs/2004.12585
本文由腾讯 AI Lab 主导,与佛罗里达大学合作完成,提出了一种用于变分自编码器的不增加训练负担就能有效防止后验概率坍缩的新方法。
变分自编码器 (VAE) 是一种被广泛运用的生成模型。然而,当与强大的自回归解码器搭配使用时,VAE 通常会收敛到一个退化的局部最优值,称之为后验概率坍缩。先前的方法会考虑每个数据点的 KL 散度,且需要额外的计算量和参数。如何不增加训练负担而有效防止后验概率坍缩是本文的研究内容。本文提出只需要保证 KL 散度的分布的期望为正就足以防止后验概率坍缩。本文因此提出批归一化-VAE (BN-VAE),一种通过对近似后验参数进行正则化从而保证 KL 散度分布的期望下限为正。本文所提出的模型在不引入任何新参数或者修改优化目标的情况下就能避免后验概率的坍缩。BN-VAE 的训练速度可以媲美普通 VAE。实验表明,本文提出的 BN-VAE 在语言模型、文本分类和对话生成方面优于自回归编码器的基准,效果可与更复杂的方法相媲美,同时保持了与 VAE 几乎相同的训练时间。

BN-VAE 的训练过程
5. 一种为低资源对话生成任务定制模型结构的方法
Learning to Customize Model Structures for Few-shot Dialogue Generation Tasks
论文:https://arxiv.org/abs/1910.14326
本文由腾讯 AI Lab 与北京大学合作完成,首次提出了从模型参数和模型结构两个角度,为低资源场景下的多个对话任务定制文本生成模型的新方法。
低资源场景下的对话生成任务是开放领域对话系统的重要研究课题。现有的方法大多采用元学习的框架,即在大量任务上训练得到一个初始化参数,然后通过微调迅速将该参数迁移到新任务上。然而,微调仅从参数层面区分不同的任务,而忽略了不同任务可能需要不同的网络结构的事实,导致不同任务的生成结果差异小。本文提出一种在低资源场经下可以为不同任务定制生成模型结构的方法。具体地,每个任务的生成模型分为三部分:共享模块、门控制模块和私有模块。前两个模块是所有任务之间共享,私有模块会根据每个任务的特点在训练过程中演化为不同的网络结构,以适应每个任务的特点。在两个个性化对话的数据集上的实验表明,本文提出定制方法可以更好地区分不同的生成任务,且在低资源场景下表现优异。此外,本文还分析了任务的相似度、任务的数据量等影响因素对生成任务结果的影响,为其他文本生成任务提供了支持。
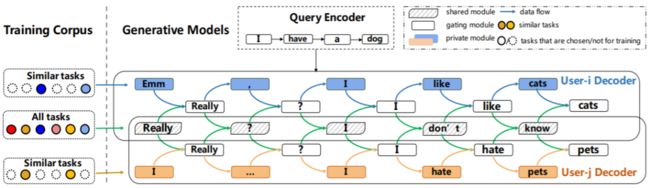
新提出的应用于个性化对话系统的定制模型无关式元学习(CMAML)算法,每个定制对话模型 Seq2SPG 都由共享模块、门控制模块和私有模块构成。
6. 基于开放领域表格的逻辑性自然语言生成
Logical Natural Language Generation from Open-Domain Tables
论文:https://arxiv.org/abs/2004.10404
代码:https://github.com/wenhuchen/LogicNLG
本文由腾讯 AI Lab 与加州大学圣巴巴拉分校合作完成,构建了一个要求推理能力的新型自然语言生成任务,对现有的生成方法提出了挑战,并给出了若干解决方向。相关研究代码已经开源。
神经网络自然语言生成模型近期取得了较大进展,特别是生成语言的流畅度方面更是进展显著。然而,近期主要的研究都集中于表层实现,很少有研究关注生成过程中的推理问题。本文提出了一个新的自然语言生成任务,在本任务中模型被要求从开放领域的半结构化表格来生成自然语言句子,要求生成的句子在逻辑事实上可以从表格的事实中推出。本工作是基于之前(Chen et al. 2019)中提出的 TabFact 数据集构建的,提出了若干个自动评估准则用于评估生成的自然语言句子在逻辑上是否符合事实。本文提出的任务对于现有的单调生成方法(例如从左到右序列生成法)构成了很大的挑战。通过一系列全面的实验,我们发现单调生成方法擅长于生成高流畅度的句子,但在保证逻辑真实性上表现较弱。为解决这一难题,本文提出了一种由粗颗粒到细颗粒度的生成机制,可以在保证逻辑顺序的同时保证真实性。本工作对研究更接近实用化的自然语言生成模型可提供很好的评估平台和指引。

LogicNLG 数据集与已有 NLG 数据集的比较

本文新提出的由粗颗粒到细颗粒度的生成机制:首先生成一个粗粒度的模板,然后再实现细粒度的表层。其中表层实现模型会获得更多上下文信息以更好地获取上下文的逻辑依赖关系。
7. 用于自动解数学应用题的图到树学习
Graph-to-Tree Learning for Solving Math Word Problems
论文:https://www.aclweb.org/anthology/2020.acl-main.362/
代码:https://github.com/2003pro/Graph2Tree
本文由腾讯 AI Lab与新加坡管理大学、成都电子科技大学合作完成。本文通过提出基于图的编码器建模了应用题中数字与数字的关系,为未来本领域的研究提供了新的思路。
近年来,基于表达式树的神经网络模型在自动解数学应用题(mwp)的公式表达方面已显示出令人鼓舞的结果,但大多数模型仍然没能很好地捕捉数字之间的关系和顺序信息,并导致数字表示不正确和解题公式表达不正确。本文提出了Graph2Tree,这是一种新颖的深度学习架构,结合了基于图的编码器和基于树的解码器以生成更好的公式表达式。我们的Graph2Tree框架中包含两个图,即“数字单元图(Quantity Cell Graph)”和“数字比较图(Quantity Comparison Graph)”,并通过有效地表示数学应用题中数字之间的关系和顺序信息来解决现有方法的局限性。我们在两个公开数据集进行了实验,结果表明,Graph2Tree的性能明显优于最新基准。最后在案例研究中,我们展示了本方法在解决数学应用题方面的优势与独到之处。

Graph2Tree 模型架构示意图
8. 基于内容匹配约束的有忠实度的表格文本生成
Towards Faithful Neural Table-to-Text Generation with Content-Matching Constraints
论文:https://arxiv.org/abs/2005.00969
本文由腾讯 AI Lab 与纽约州立大学布法罗分校合作完成,提出一种忠于输入表格的文本生成方法与文本生成自动评价准则。
基于表格等知识库的文本生成任务主要是将输入的若干条源于表格的三元组信息转换为自然语言描述。大多数现有生成方法忽略了生成文本与原有表格的忠实度,进而导致生成的信息超越了输入表格中的原有内容。本文首次提出了基于Transformer模型的有忠实度的表格文本生成框架。为了实现忠实度,本文提出了表格至文本的最优-传输匹配损失和表格-文本嵌入相似度损失两种损失函数,并提出了一种新的表格至文本生成自动评价准则。实验证明新提出的方法在表格至文本生成任务上表现显著优越于其他现有方法。

新提出的用于表格到文本生成任务的模型架构。为了生成多句式的忠实文本,其中的损失由三部分组成,包括一个最大似然损失(绿色),一个隐含匹配不一致损失(橙色)和一个最优-传输匹配损失。
9. 用于生成更连贯视频语言描述的记忆增强型循环Transformer
MART: Memory-Augmented Recurrent Transformer for Coherent Video Paragraph Captioning
论文:https://arxiv.org/abs/2005.05402
代码:https://github.com/jayleicn/recurrent-transformer
本文由腾讯AI Lab主导,与美国北卡罗来纳大学教堂山分校(UNC)合作完成,提出了一种可以增强视频语言生成的连贯性的循环 Transformer 结构。
为视频生成多句子描述是最具挑战性的任务之一,因为它不仅对相关性而且对连贯性都有很高的要求。为了实现这一目标,本文提出了一种新的方法——记忆增强型循环 Transformer(MART)。MART使用记忆存储单元来增强 Transformer 架构,从而实现递归模型。记忆存储模块从视频片段和句子历史记录生成高度汇总的记忆状态,以帮助预测下一个句子,从而促进连贯段落的生成。大量的实验表明,与其它方法相比,MART 可以产生更连贯,避免重复的段落文字,同时保持相关性。

左图:用于视频段描述的记忆增强型循环Transformer
右图:作为对比的Transformer-XL模型

生成结果示例,可以看到新提出的模型生成的描述不仅更连贯更少重复,而且也保证了相关性
方向二:机器翻译
机器翻译是近年来成果颇丰的研究领域,尤其是神经机器翻译更是在研究和应用上都取得了亮眼的成绩,但同时机器翻译也还仍存在许多有待解决的问题。腾讯 AI Lab 共有 5 篇相关论文入选 ACL 2020,其中除了新型的翻译模型之外,还有一种用于评估神经机器翻译的可解释性方法以及在量化神经网络模型在推理阶段的置信度校准偏差方面的开创性研究,另外还有两项基于自注意网络的研究成果。
1. 神经机器翻译中推理阶段的置信度校准研究
On the Inference Calibration of Neural Machine Translation
论文:https://arxiv.org/abs/2005.00963
代码:https://github.com/shuo-git/InfECE
本文由腾讯AI Lab主导,与清华大学合作完成,是在量化神经网络模型在推理阶段的置信度校准偏差方面的开创性研究,并且本文的一系列分析结果能对日后如何进一步改进模型提供有效支持。最后,本文提出的阶梯式标签平滑方法可以有效减少模型在推理阶段的置信度校准偏差。
在面向用户的场景中,如果系统能在预测结果的同时给出可靠的置信度,那就将具有十分重要的意义。在结构化生成任务中,神经网络模型的置信度通常是在训练场景中研究的。鉴于结构化生成任务的训练和推理存在暴露偏差问题,模型在训练阶段的置信度往往不能如实反映其在推理阶段的置信度校准情况。本文提出在推理场景下量化结构化生成模型的置信度校准能力,并且以机器翻译为例对推理阶段的置信度偏差进行了充分的分析,最后我们基于以上发现提出了一种阶梯式标签平滑的方法。本文首次量化了神经网络模型在推理阶段的置信度校准偏差,消除了暴露偏差的影响。并且本文的一系列分析结果对日后如何进一步改进模型提供了有效的支持。实验表明,本文提出的置信度校准量化方法可以有效地反映模型的能力。并且本文提出的阶梯式标签平滑方法可以有效减少模型在推理阶段的置信度校准偏差。

在 WMT 14 英德翻译任务上的训练和推理可靠度示意图。Gap 是指置信度和准确度之间的差别。Gap 更小表示更好的校准输出。可以发现置信度和准确度之间的平均 Gap 在推理阶段比在训练阶段要大得多(15.83 > 1.39)
2. 评估神经机器翻译的可解释性方法
Evaluating Explanation Methods for Neural Machine Translation
论文:https://arxiv.org/abs/2005.01672
本文由腾讯 AI Lab 主导, 与电子科技大学和哈尔滨工业大学合作完成,在评估“对模型的仿真度”的视角下提出了一种自动的评估方法,来评价机器翻译的可解释性方法。
近年来致力于解释神经机器翻译黑盒模型的研究越来越多,但是在如何评价这些可解释性方法上,却始终进展甚微。词对齐错误率可用作衡量可解释性方法与人类认知的符合度的指标,但是它却不能评价可解释性方法在那些没有人工对齐的目标端词语表现如何。因此,本文做出了初步的尝试,从另一种视角下评价可解释性方法。为此,本文提出了一种基于与神经机器翻译模型预测行为的仿真度的原则性度量方法,并且提出了这种方法的近似以便进行计算。在6个基础翻译任务上,我们定量地评估了可解释性方法在我们提出的度量方法下的表现,并且在实验中得到了一些有用的发现。本研究对之后的神经机器翻译可解释性相关的研究有助推的作用,同时对未来自然语言处理中可解释性方法的评价工作有参考价值。

算法 1:计算评估指标
3. 基于正则化上下文门的Transformer翻译模型
Regularized Context Gates on Transformer for Machine Translation
论文:https://arxiv.org/abs/1908.11020
本文由腾讯 AI Lab 主导,与香港中文大学和日本国立情报通信研究所合作完成,探索了通过扩展门技术提高机器翻译性能的方法。
上下文门在循环神经网络中可以有效地控制机器翻译中来自源端和目标端信息的贡献。然而,将上下文门扩展到更复杂的 Transformer 中仍是一项有挑战的工作。基于 Transformer,本文首先提出识别源端和目标端信息的方法,继而引入门机制来控制它们在翻译中的贡献。此外,为进一步降低门机制中的偏置问题,本文提出了一种正则化方法,可通过点互信息监督来引导门的学习。在四个数据集上的大量实验表明,所提出的方法可将 BLEU 分数平均提升 1。
4. 选择性机制如何改善自注意力网络?
How Does Selective Mechanism Improve Self-Attention Networks?
论文:https://arxiv.org/abs/2005.00979
代码:https://github.com/xwgeng/SSAN
本文由腾讯 AI Lab 主导, 与哈尔滨工业大学合作完成,分析研究了自注意力网络在自然语言处理任务上的选择性机制。
近年来,为自注意力网络(SAN)引入选择机制已经成为了一个重要的研究方向,这种做法使得模型能关注其中重要的输入元素,从而取得更好的效果。但是,为何选择机制能取得这样结果呢?本文提出了一个通用、灵活的基于选择机制的自注意力网络,并在自然语言推理(分类)、语义角色标注(序列标注)和机器翻译(序列生成)任务上验证其有效性。考虑到自注意力网络在顺序编码以及结构信息建模能力上存在不足,本文主要针对这两个方面提出了相应假设,并通过实验验证其正确性。实验分析发现,将选择机制引入自注意力网络的好处在于:1) 能更多关注周围词的信息,从而对周围词序的变化比较敏感,使得其能更好对顺序进行编码;2)其对于句法树结构中的重要成分更加关注,从而使网络具备更强的捕捉结构信息的能力。总体而言。本文在三种代表性任务上验证了选择性机制对自注意力网络的提升作用,并解释了该机制在顺序编码和结构建模上的主要贡献,这对于进一步改进自注意力网络有一定的启发和指导意义。

使用一个额外的选择器网络选择输入元素的一个子集的选择性自注意网络(SSAN)示意图,其中上半部分执行的自注意。这个案例中,词 talk 在输入序列上执行注意操作,而词 Bush、held 和 Sharon 则被选为真正重要的词。

来自一个在本地重新排序检测任务上的注意权重的可视化,图中红色框表示对于每次查询(X 轴)有最大注意权重的被注意词(Y 轴)
5. 融入跨语言位置表征的自注意力网络
Self-Attention with Cross-Lingual Position Representation
论文:https://arxiv.org/abs/2004.13310
本文由腾讯 AI Lab 与悉尼大学合作完成,研究了关于自注意力网络融合跨语言位置信息。本文证明了跨语言位置表征在翻译任务中的有效性,这对进一步改进自注意力网络以及编码器-解码器结构的共享性具有启发和指导意义。
近年来自注意力网络在自然语言处理的各项任务中都取得了很好的表现。作为其重要部分,额外的位置编码模块可通过对词序信息建模使自注意力网络具备位置感知能力。但是机器翻译任务是跨语种场景,其源端和目标端的位置编码是独立的。然而不同语言之间存在语序差异,同时考虑两端的位置关系可以进一步提升自注意力网络的建模能力。本文提出利用跨语言的位置表示来增强自注意力网络,使其对输入句子的潜在双语结构进行建模。具体地,本文采用了括号转录语法得到调序位置信息并提出了两种融合策略,以鼓励自注意力网络学习单调对齐性质。实验结果表明,新提出的方法在英德、日英、中英和英中翻译任务上能稳定一致地提高翻译质量。

用于英中翻译任务的跨语言位置示意图。(a)展示跨语言预排序的括号转录语法(BTG)树。左上角是转录语法。(b)绝对位置编码(APE)与新提出的跨语言位置编码(XL PE)之间的差异。

新提出的两种融合策略,其中(a)为输入层面的跨语言 SAN,(b)为头层面的跨语言 SAN
方向三:文本理解
文本理解也是腾讯 AI Lab 重点关注的研究方向,自然语言理解系统 TexSmart 就是腾讯 AI Lab 在该领域实现的一项重要应用。本届 ACL,腾讯 AI Lab 继续呈现了在这一领域的最新探索成果,其中包括对长文本阅读理解的新解决方案、从高资源语言向低资源语言的泛化研究、基于对话的关系抽取以及新型关键词生成技术。
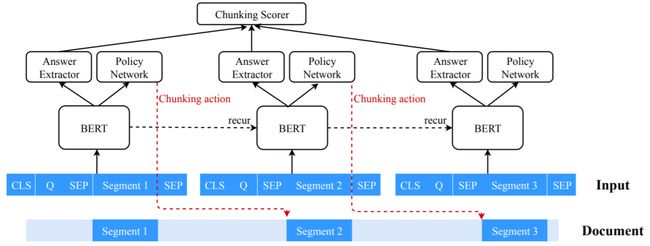
1. 长文阅读理解中的循环分块机制
Recurrent Chunking Mechanisms for Long-Text Machine Reading Comprehension
论文:https://arxiv.org/abs/2005.08056
本文由腾讯 AI Lab 独立完成,提出了一种可用以提升长文本阅读理解任务的循环分块机制,并有可能为其它类型的长文本任务带来启发。
本文重点讨论了对话型机器阅读理解(MRC)问题,其中模型的输入可能是冗长的文档和一系列相互关联的问题。为了处理长输入,以前的方法通常将它们分成等距段,并根据每个块独立地预测答案,而不考虑其它块的信息。结果,它们可能会形成无法覆盖完整答案或围绕问题答案所需正确答案的上下文不足的块。此外,它们的能力往往不足,无法很好地回答需要跨块信息的问题。本文提出让模型通过强化学习以更灵活的方式学习分块:模型可以确定将在任一方向处理的下一个分块。我们还应用了循环机制,以允许在块之间传输信息。我们在两个对话型 MRC 任务(CoQA和QuAC)上进行了实验,结果证明了新提出的循环式分块机制的有效性。我们可以获得的块更有可能包含完整的答案,同时能为真实的答案提供足够的上下文,以便更好地进行预测。
2. 基于元学习的低资源语言上下位预测的方法
Hypernymy Detection for Low-Resource Languages via Meta Learning
论文:https://www.aclweb.org/anthology/2020.acl-main.336/
代码:https://github.com/ccclyu/metaHypernymy
本文由腾讯 AI Lab 主导,与香港科技大学合作完成,提出了一种通过元学习实现低资源语言上下位预测。该方法可用于指导多语言、低资源的上下位预测的实现,并能给词汇级别的语义理解提供启发。
上下位预测是语义理解中重要的子任务,在问答系统和知识挖掘等任务中发挥着重要作用。但目前希腊语和荷兰语等低资源语言的上下位预测缺乏足够用于监督训练的标注数据。本文提出和探讨的问题是如何利用高资源语言(比如英语)的丰富数据帮助低资源语言的泛化学习。其中论文的基本假设是来自于人类对于概念认知的语言无关性,例如苹果和 apple 指的是同样的概念。文中设计实验分别比较了跨语言训练、多语言联合训练和元学习这三种不同的混合训练方式,结果表明简单的多语言联合训练并不会帮助低资源语言的学习,但论文中首次提出的元学习的方式可以通过学到一个适用于多种语言的模型初始化来有效地避免模型过拟合小数据,从而可实现在低资源语言上下位预测任务上的性能提升。
3. 基于对话的关系抽取
Dialogue-Based Relation Extraction
论文:https://arxiv.org/abs/2004.08056
代码:https://github.com/nlpdata/dialogre
数据集:https://dataset.org/dialogre
本文由腾讯 AI Lab 主导,与康奈尔大学合作完成,本文首次定义了基于对话的关系抽取任务并填补了对话型通用关系抽取数据资源的空白,在这一未被充分研究的领域走出了第一步。
本文提出了第一个标注的基于对话的关系抽取(RE)数据集DialogRE,旨在支持对出现在对话中的两个元素之间的关系进行预测。由于大多数事实跨越多个句子,我们进一步提供DialogRE作为研究跨句RE的平台。基于对对话型RE任务与传统RE任务之间的异同的仔细分析,我们提出说话者相关的信息在该任务中起着至关重要的作用。考虑到对话中交流的及时性,我们设计了一种新的指标来评估对话环境中 RE 方法的性能,并调研了 DialogRE 上几种具有代表性的RE方法的性能。实验结果表明,在表现最佳的基线模型上显示识别说话人元素在两种评价指标上都能带来性能提高。

DialogRE 数据集中的一段对话和相关实例
4. 图到文本生成中的结构化信息保留
Structural Information Preserving for Graph-to-Text Generation
论文:https://www.aclweb.org/anthology/2020.acl-main.712/
代码:https://github.com/Soistesimmer/AMR-multiview
本文由腾讯 AI Lab 主导,与厦门大学合作完成,文中提出了一种多视角框架,通过自编码学习丰富模型训练。
图到文本生成任务的目标是产生保留输入图所蕴含语义的句子。该任务存在一个关键缺陷:当前的模型在生成输出时,可能会弄乱甚至丢弃输入图的核心结构信息。本文提出利用更丰富的训练信号来解决此问题,这些信号可以指导我们的模型遵循输入的图结构信息。特别是,我们采用了两种类型的辅助训练信号,每种信号分别关注输入图的不同方面(也称为视图)。通过辅助信号的反向传播,以通过多任务训练更好地校准我们的模型。在两个用于图形到文本生成的基准上进行的实验表明,新提出的方法在最新的基准上是有效的。
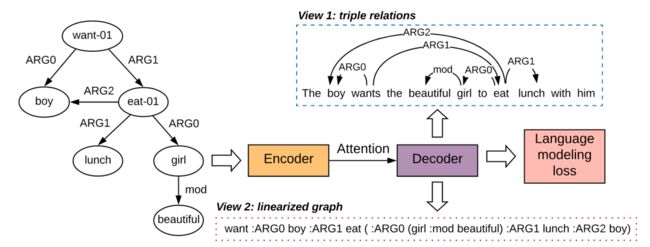
使用多视角自动编码损失的训练框架
5. 基于多任务训练框架的联合零指代还原和消解训练
ZPR2: Joint Zero Pronoun Recovery and Resolutionusing Multi-Task Learning and BERT
论文:https://www.aclweb.org/anthology/2020.acl-main.482
代码:https://github.com/freesunshine0316/lab-zp-joint
本文由腾讯 AI Lab 主导完成,提出了一种新型的零指代消解和还原的联合训练框架。
零代词的恢复和消解分别旨在恢复被丢弃的代词并指出其所指短语。本文提出通过同时解决这两个任务来更好地探索它们的交互,而先前的工作将它们独立对待。对于零代词消解,我们在更现实的环境中研究了此任务——在该环境下没有正确的句法树或只有自动树可用,而大多数先前的工作都是假设存在正确的句法树。在两个数据集上的测试表明,联合建模明显优于我们的基准系统,而该基准已经超越了现有技术水平。

模型架构,其中使用了 BERT 来表征每个包含 N 个词的输出句子以提供共享的特征
6. 基于互斥分层解码策略的深度关键词生成
Exclusive Hierarchical Decoding for Deep Keyphrase Generation
论文:https://arxiv.org/abs/2004.08511
本文由腾讯 AI Lab 与香港中文大学合作完成,提出了一个简单有效的层次解码策略,可以一次性生成多样且准确的关键词。
关键词生成(KG)的目的是将文档的主要思想概括成一组关键词。最近在这个问题中引入了一种新的设置:给定一个文档,模型需要预测一组关键词,并同时确定要生成的关键词的适当数量。此前的工作在此设置中采用了一种顺序解码过程来生成关键词。然而,这样的解码方法忽略了文档中的关键词中存在的内在层次性。此外,以前的工作往往会产生重复的关键词,进而造成时间和计算资源浪费。为了克服这些局限性,本文提出了一种互斥分层解码框架,该框架包括一个分层解码过程和软性或硬性互斥机制。分层解码过程是为了显式地建模一个关键词集合的分层构成性。软互斥机制和硬互斥机制都会在一定的窗口大小内保持对之前预测的关键词的跟踪,以增强生成的关键词的多样性。我们在多个 KG 基准数据集上进行了大量实验,结果证明新提出的方法可以有效生成更少重复和更准确的关键词。

新提出的互斥分层解码框架示意图。h_i 是第 i 个短语级解码步骤的隐藏状态,h_{i,j} 是对应的第 j 个词级解码隐藏状态

使用互斥损失的训练算法

使用互斥搜索的推理算法
重磅!自然语言处理技术交流群已成立!
欢迎各位NLPer加入自然语言处理技术交流群,目前群内已有上百人!本群旨在交流文本分类、语音识别、阅读理解、机器翻译、情感分析、信息检索、问答系统等自然语言处理领域内容。自然语言处理领域前沿信息将会第一时间在群里发布!欢迎大家进群一起交流学习!
添加请备注:研究方向+学校/公司+昵称(如文本分类+浙大+小民)
广告商、博主请绕道!

???? 长按识别添加,邀请您入群!