oracle sql 高级编程学习笔记(十五)
如果在查询中有多张表,在优化器确定了每个表的访问方法之后,下一步就是要确定将这些表联结起来的最佳方法以及最恰当的顺序。任何时候在from子句中有多个表时,就需要进行联结,如果没有指定任何条件,会选择笛卡尔联结。
联结的方法有:嵌套循环联结,散列联结,排序-合并联结,笛卡尔联结。每种联结方法都有一定的最适合使用条件,每个联结方法都有两个分支,所访问的第一张表通常称为驱动表,访问的第二张表则称为内层表或被驱表。其他表的联结顺序都是由优化器使用所能得到表、列以及索引统计信息计算得到的选择比来进行评估。
如果在查询中有多张表,在优化器确定了每个表的访问方法之后,下一步就是要确定将这些
表联结起来的最佳方法以及最恰当的顺序。任何时候在from子句中有多个表时,就需要进行联结,
如果没有指定任何条件,会选择笛卡尔联结。
联结的方法有:嵌套循环联结,散列联结,排序-合并联结,笛卡尔联结。每种联结方法都有一定的最适合使用条件
每个联结方法都有两个分支,所访问的第一张表通常称为驱动表,访问的第二张表则称为内层表或被驱表。其他表的联结顺序都是由优化器使用所能得到表、列以及索引统计信息计算得到的选择比来进行评估。
一、嵌套循环联结
使用一次访问运算得到 的结果集中的每一行来与另一个表进行对碰。如果结果集的大小是有限的并且在用来
联结的列上建有索引的话,这种联结的效率通常是最高的。
顾名思义,嵌套循环联结就是一个循环嵌套在另一个循环中。外层循环基本来说就是一个只使用where子句中的属于驱动表的条件对它进行查询。
当数据行经过了外层条件筛选并被确认匹配条件后,这些行就会逐个进入到内层循环中。然后再基于联结列进行逐行检查看是否与被联结的表中的某一行相匹配。如果这个一行与第二次的检查相匹配,就将会被传递到查询计划的下一步或者如果没有更多步骤的话直接被包含在最终的结果集中。
这种类型的联结的强大之处在于所使用的内存是非常少的,因为数据行集一次只加工一行,所需要的开支也是非常小的。由于这个原因,除了使用一次加工一行这种方式建立一个很大的数据集需要较长时间这一点外,它也是适合进行大数据集加工的。嵌套循环联结的基本度量就是为了准备最终结果集所需要访问的数据块数目。
(与散列联结对应)嵌套循环:一般小表为驱动表,大表为被驱动表,由小表中满足条件的数据去大表中循环遍历查找满足条件的数据。一般来说大表的条件列上有索引会加快查询速度。小表被查询一次,大表扫描N次。
实例:
/*+ leading(dept) use_nl(emp)*/ 强制使用循环嵌套联结
select /*+ leading(d) use_nl(e)*/ e.ename,d.deptno,d.dname ,d.loc from emp e ,dept d where e.deptno=d.deptno;
这个查询将会像下面这段伪码一样来进行处理:
for each row in( select ename,deptno from emp) loop
for (select dname,loc from dept where deptno=outer.deptno) loop
if match then pass the row on to the next step
if inner join and no match then discart the row
if outer join and no match set inner column values to null
and pass the row on to the next step
end loop
end loop
执行计划
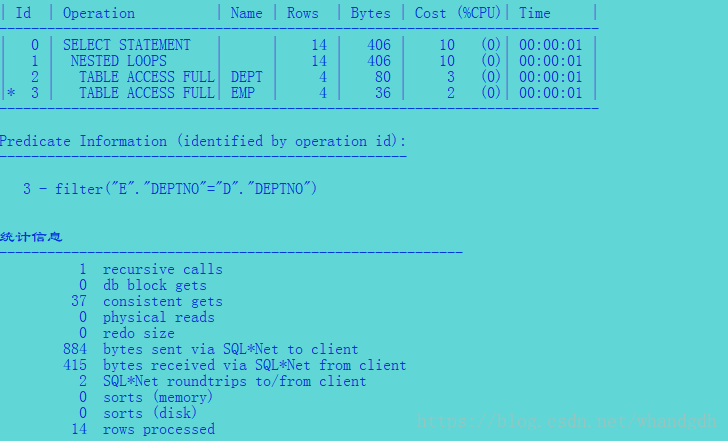
参考不强制使用嵌套循环联结时,执行计划选择的排序-合并联结
看到成本比嵌套循环联结少,且逻辑读取也比嵌套循环少了26次。
二、排序-合并联结
独立地读取需要联结的两张表,对每张表中的数据行(仅是那些满足where 子句中条件的数据行)按照联结键进行排序,然后对拍下后的数据行集进行合并。对这种联结方法来说排序的开销是非常大的,
对于不能够放入内存中的大的数据源来说,可能会使用临时磁盘空间来完成排序。这是非常耗内存和时间资源的。但是一旦数据排序完成了,合并的过程是非常快的。为了进行合并,数据库轮流操作两个列表,比较最上面的数据行,丢弃在排序队列中比另一列表中的最上面一行出现得最早的数据行,并只返回匹配的行。
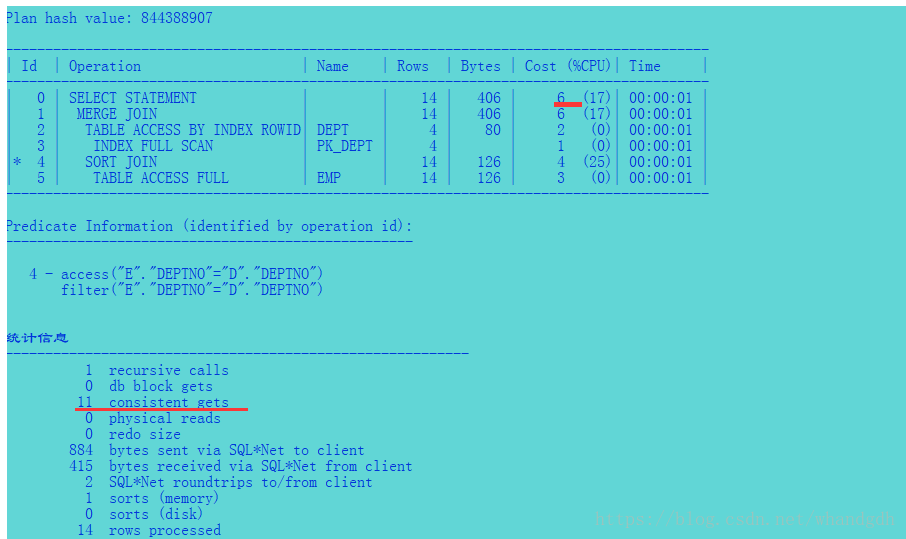
select e.ename,d.deptno,d.dname ,d.loc from emp e ,dept d where e.deptno=d.deptno;
这个查询将会像下面这段伪码一样来进行处理:
select empno,ename, deptno from emp order by deptno
select dname,loc,deptno from dept order by deptno
compare the rowsets and return rows where deptno in both lists match
for an outer join ,compare the rowsets and return allrows from the first
list setting column values for the other table to null
执行计划

在这个例子中。因为索引将按排序后的顺序返回数据,优化器选择使用索引全表扫描来读取数据,这就意味着可以
避免一次单独的排序运算。对于emp 表则必须进行全表扫描然后要单独进行排序,因为在deptno 这一列没有索引可以使用。在两个数据行集都准备好并排序后,它们将会被合并到一起。
排序-合并联结将会访问所需的数据块然后在内存中(或者如果没有足够内存的话使用临时磁盘空间)进行排序和合并。因此,当你对排序-合并联结和嵌套循环进行逻辑读取比较多的时候,尤其是对于一个更大的数据行源的查询,你可能会发现嵌套循环联结所需的块访问更多。但这是不是意味着排序-合并联结就是更好的选择呢?不一定,你必须把所有需要进行排序以及合并等步骤的工作都考虑进去,并意识到这些工作最终有可能比较多的块访问花费的时间更多。排序-合并联结一般最适合于数据筛选条件有限并返回有限数据行的查询。如果没有可用的更直接访问数据的索引时排序-合并联结也通常时较好的选择。总的来说,在条件为非等式的时候,排序-合并通常时最好的选择,
例如: where table.column1 between table2.column1 and table2.column2 这样的条件就比较适合排序-合并联结。
三、散列联结
与排序-合并联结类似,首先应用where 子句中的筛选标准来独立地读取要进行联结的两个表。
基于表和索引的统计信息,被确定为返回最少行数据的表被完全散列化到内存中。
这个散列表包含了原表所有的数据行并被基于将联结键转化为散列值的随机函数载入到散列桶中
只要有最够的内存空间,这个散列表将一致放在内存中,然而,没有足够的内存,散列表将会被写入到临时磁盘空间。
下一步就是读取另一张较大的表并对联结键应用散列函数。然后利用得到的散列值对较小的在内存中的散列表进行探测以寻找匹配的第一个表的数据所在
的散列桶,每个散列桶都有一个放在其中的数据行列表,这个列表被用来与探测行进行匹配。
如果匹配成功,则返回这一行数据,否则丢弃。较大的表只读取一次,并检查其中的每一行来寻找匹配。
这与嵌套循环联结的不同之处在于此处内层表被多次读取。因此在散列联结中较大的表是驱动表。
因此仅读取一次,而较小的散列表则被探测很多次,与嵌套回路联结执行计划不同,在执行计划输出中较小的散列表放在前面
而较大的探测表放在后面。(耗内存、CPU)
同样使用嵌套循环中的例子:
select /*+ leading(e) use_hash(d)*/ e.ename,d.deptno,d.dname ,d.loc from emp e ,dept d where e.deptno=d.deptn
这个查询将会被像下面这段伪码一样来进行处理
determine the smaller row set ,or in the case of an outer join
use the outer joined table
select deptno,dname,loc from dept
hash the deptno column and build a hash table
select ename ,deptno from emp
hash the deptno column and probe the hash table
if match made ,check bitmap to confirm row match
if no match made discard the row
来看执行计划
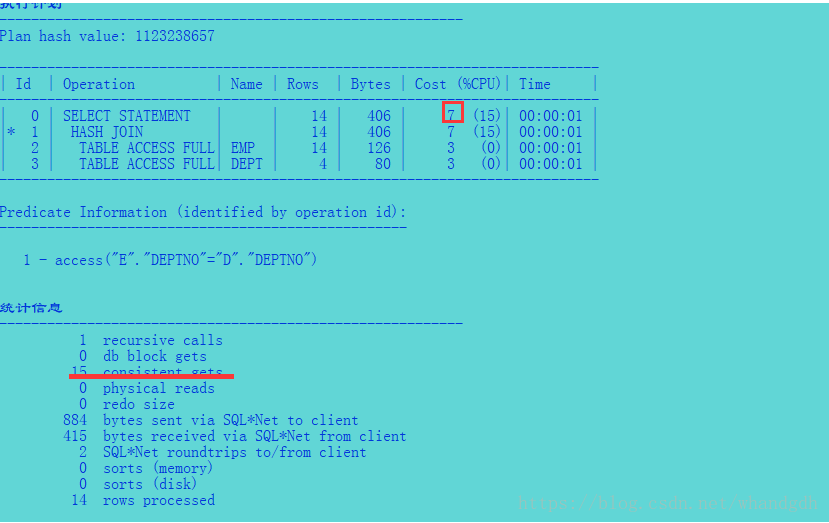
在散列联结中记住决定那个表时最小的不仅取决于数据行还取决于这些行的大小,因为整个行都必须要放在散列表中。当数据行源较大并且结果集也较大的情况下将更倾向于考虑散列联结,或者如果要联结的其中一张表确定总是给返回同一行数据行源,也很有可能会选用散列联结因为这样仅访问一次这张表。如果在这种情况下选用嵌套循环联结,这个数据源就会被一遍又一遍地访问,需要比单独访问一次多做很多工作。最后如果较小的表可以放到内存中,散列联结也会很收欢迎。散列联结中访问数据块的方式类似于排序-合并联结中的访问方式。建立散列表所需的数据块将被读取,然后剩下的工作将会针对存放在内存中(如果没有足够内存的话将会是临时磁盘空间)的散列数据来进行。因此当你对散列联结和排序-合并联结的逻辑读取进行比较的时候,访问的数据块数目几乎是相等的。相对于嵌套循环联结来说,逻辑读取会比较少,因为数据块仅仅被读取了一次,然后放到内存中(对于散列表)再进行访问或者只读取一次(对于探测表) 散列联结只有在相等联结的情况下才能进行。原因在于匹配时针对散列值来进行的,而在一个范围内来考虑散列值是没有意义的。
我们来看下ora_hash()函数,这个函数有三个参数,第一个是任何基本类型的输入,以及最大散列桶值(最小值为0),
以及一个种子值(默认值也是0)
具体使用如下

另外一个实例
create table emp_tmp(e_id number(6),gender varchar2(2));
create table loc_tmp(e_id number(6),loc varchar2(10));
begin
for i in 1..5000 loop
insert into emp_tmp values(i,'F');
END loop;
commit;
end;
begin
for i in 1..5000 loop
insert into loc_tmp values(i,'KM'||i);
END loop;
commit;
end;
alter table loc_tmp add primary key (loc);
select e.e_id,l.loc from emp_tmp e ,loc_tmp l
where e.e_id=l.e_id;

四、外联结
返回一张表的所有行以及另外一种表中满足条件的行数据,
Oracle 使用’+’ 字符来表明进行外联结。
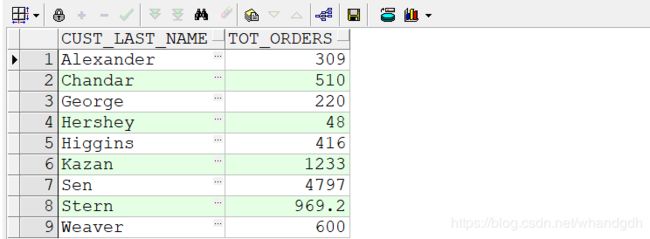
select c.cust_last_name ,nvl(sum(o.order_total),0) tot_orders from customers c ,orders o
where c.customer_id=o.customer_id
group by c.cust_last_name
having nvl(sum(o.order_total),0) between 0 and 5000
order by c.cust_last_name;
执行结果
使用外联结后:
select c.cust_last_name ,nvl(sum(o.order_total),0) tot_orders from customers c ,orders o
where c.customer_id=o.customer_id(+)
group by c.cust_last_name
having nvl(sum(o.order_total),0) between 0 and 5000
order by c.cust_last_name;
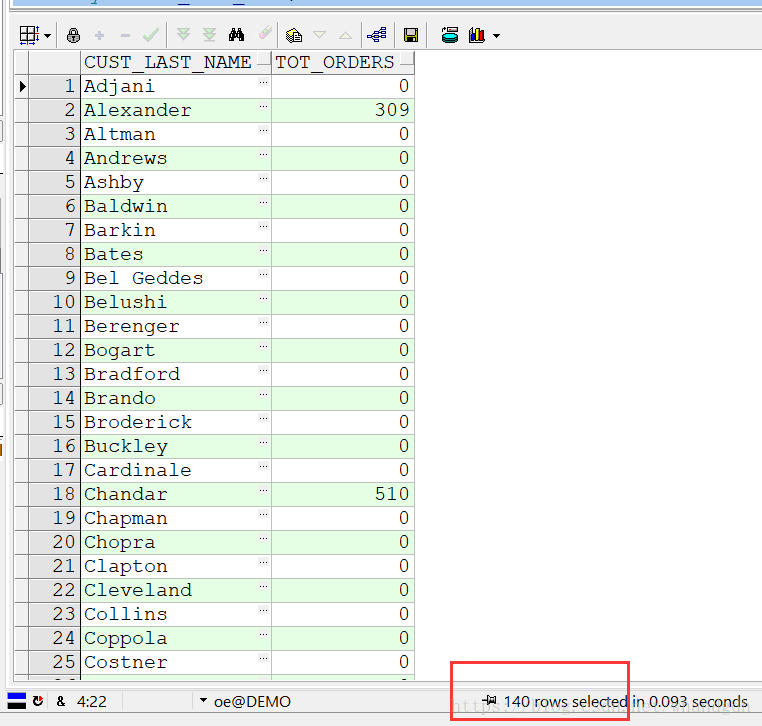
根据上面的结构可以知道,外联结的结果才是正确的,第一个sql没有考虑没有下订单的用户。没有下订单的用户再订单表里面是没有数据的。
ANSI 外联结的相同语法
select c.cust_last_name ,nvl(sum(o.order_total),0) tot_orders from customers c left outer join orders o
on c.customer_id=o.customer_id
group by c.cust_last_name
having nvl(sum(o.order_total),0) between 0 and 5000
order by c.cust_last_name;
当使用(+)时有ANSI没有的局限性,即当一张表与另外多张表进行外联结时,会报一张表最多只能与一张表进行外联结。
而ANSI 语法没有数目限制。oracle 外联结语法的还有一个局限性在于它不支持全外联结。全外联结将会从左到右以及从右到左对两个表进行联结,两个方向联结得到的结果只输出一次,避免重复。
注意全外联结非常的消耗资源,成本会很高。使用的时候一定要注意。