软件公司产品营销大数据分析(上)
机器学习案例详解的直播互动平台——
机器学习训练营(入群联系qq:2279055353)
下期直播案例预告:大数据预测商品的销售量波动趋势
案例背景
这个案例是关于俄罗斯著名的软件制作发行公司——1C公司,在2013年1月——2015年10月,软件产品在各个零售商店日常销售情况的数据分析。
-
数据来源:Kaggle 竞赛
-
代码实现:R 语言
数据文件
我们介绍这个案例的主要文件和数据。
sales_train.csv
从2013年1月到2015年10月,1C公司软件产品的日销售数据集。它包括的变量有:
-
date: 销售日期
-
date_block_num: 连续的月份值,2013年1月记为0,2月记为1,以此类推。
-
shop_id: 零售商店识别符
-
item_id: 产品识别符
-
item_price: 产品价格
-
item_cnt_day: 产品日销量
items.csv
数据集items.csv记录了产品的附加信息。
-
item_name: 产品名字
-
item_id: 产品识别符
-
item_category_id: 产品所属类别识别符
item_categories.csv
它包括产品类别名字item_category_name和产品类别识别符item_category_id两个变量。
shops.csv
它包括零售商店名字和识别符变量。
数据集下载
请到以下百度网盘下载上述数据集:
链接:https://pan.baidu.com/s/1QXIqX16vsDtTuy_QkU97Eg
提取码:aw5w
我们在对销售数据作细致的分析之前,需要对数据进行必要的准备。为此,先在R环境里加载一些必要的包。
library(readr)
library(data.table)
library(datasets)
library(dplyr)
library(lubridate)
library(ggplot2)
library(ggthemes)
library(plotly)
library(Amelia)
library(caTools)
library(class)
library(scales)
数据准备
导入数据集
我们先导入sales_train.csv, items_csv这两个数据集,并查看一下数据集的结构和维数。
dataset_sales_train <- read_csv("../input/sales_train.csv")
head(dataset_sales_train)

dataset_items <- read_csv("../input/items.csv")
head(dataset_items)

dim(dataset_sales_train)
dim(dataset_items)
特征加工
来自数据集dataset_items的变量item_category_id记载了产品所属的类别。这是一个重要的变量,所以我们想把它加入到
dataset_sales_train里。这需要通过合并这两个数据集来实现,合并后的变量item_name完全可以由item_id代替,因此可以将它从合并后的数据集里删除。
dataset_sales <- dataset_sales_train %>% left_join(dataset_items, by = c("item_id"))
dataset_sales$item_name <- NULL
dataset_sales <- as.data.frame(dataset_sales)
str(dataset_sales)
注意到,date列是字符型的,而它的实际含义是日期,所以我们把它转换成日期型的。进一步根据日期拆分出年、月、日、周的新变量。
dataset_sales$date <- dmy(dataset_sales$date)
dataset_sales$year <- year(dataset_sales$date)
dataset_sales$month <- month(dataset_sales$date)
dataset_sales$day <- day(dataset_sales$date)
dataset_sales$weekday <- weekdays(dataset_sales$date)
再把新变量year, weekday转换成因子型的。
dataset_sales$year <- as.factor(dataset_sales$year)
dataset_sales$weekday <- as.factor(dataset_sales$weekday)
head(dataset_sales)

在分析产品整体销量之前,我们先来统计一下每家商店在每个月份产品的销量。
dataset_sales_item_cnt_month <- dataset_sales %>%
group_by(year, month, shop_id, item_id) %>%
summarise(item_cnt_month = sum(item_cnt_day)) %>% ungroup()
dataset_sales <- dataset_sales %>% left_join(dataset_sales_item_cnt_month,
by = c("year", "month", "shop_id", "item_id"))
head(dataset_sales)
rm(dataset_sales_item_cnt_month)

探索性分析
理解数据
glimpse(dataset_sales)
str(dataset_sales)
summary(dataset_sales)
查看数据集里是否有缺失值、空值。
colSums(is.na(dataset_sales))
is.null(dataset_sales)
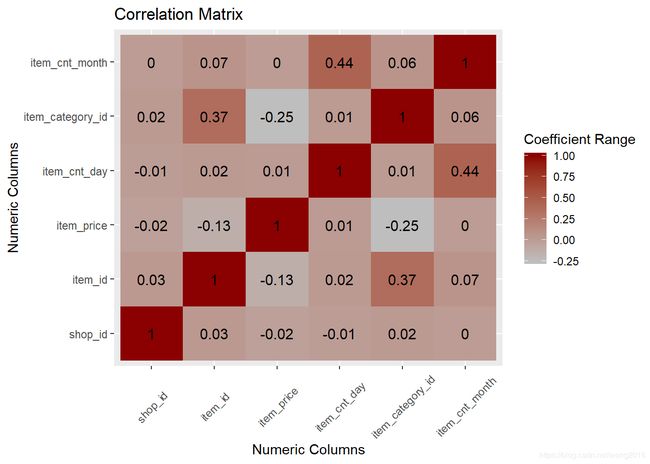
变量相关性
我们检查所有数值变量的相关性,并画出相关系数矩阵图。
num.cols <- sapply(dataset_sales, is.numeric)
dataset_sales_numcols <- dataset_sales[, num.cols]
dataset_sales_numcols$date_block_num <- NULL
dataset_sales_numcols$year <- NULL
dataset_sales_numcols$month <- NULL
dataset_sales_numcols$day <- NULL
cor(dataset_sales_numcols)
melted_corr <- melt(cor(dataset_sales_numcols))
ggplot(data = melted_corr, aes(x=Var1, y=Var2, fill=value)) +
geom_tile() +
scale_fill_gradient(low="grey", high="darkred") +
geom_text(aes(x=Var1, y=Var2, label=round(value, 2)), size=4) +
labs(title="Correlation Matrix", x="Numeric Columns", y="Numeric Columns",
fill="Coefficient Range") +
theme(axis.text.x=element_text(angle=45, vjust=0.5))
未完待续