摘要
像点击率预估这样的在线实时响应系统对响应时间要求非常严格,结构复杂,层数很深的深度模型不能很好地满足严苛的响应时间的限制。为了获得满足响应时间限制、具有优良表现的模型,我们提出了一个新型框架:训练阶段,同时训练繁简两个复杂度有明显差异的网络,简单的网络称为轻量网络(light net),复杂的网络称为助推器网络(booster net),它相比前者有更强的学习能力。两网络共享部分参数,分别学习类别标记。此外,轻量网络通过学习助推器的soft target来模仿助推器的学习过程,从而得到更好的训练效果。测试阶段,仅采用轻量网络进行预测。
我们的方法被称作“火箭发射”系统。在公开数据集和阿里巴巴的在线展示广告系统上,我们的方法在不提高在线响应时间的前提下,均提高了预测效果,展现了其在在线模型上应用的巨大价值。
已有方法介绍
目前有2种思路来解决模型响应时间的这个问题:一方面,可以在固定模型结构和参数的情况下,用计算数值压缩来降低inference时间,同时也有设计更精简的模型以及更改模型计算方式的工作,如Mobile Net和ShuffleNet等工作;另一方面,利用复杂的模型来辅助一个精简模型的训练,测试阶段,利用学习好的小模型来进行推断,如KD, MIMIC。这两种方案并不冲突,在大多数情况下第二种方案可以通过第一种方案进一步降低inference时间,同时,考虑到相对于严苛的在线响应时间,我们有更自由的训练时间,有能力训练一个复杂的模型,所以我们采用第二种思路,来设计了我们的方法。
研究动机及创新性
火箭发射过程中,初始阶段,助推器和飞行器一同前行,第二阶段,助推器剥离,飞行器独自前进。在我们的框架中,训练阶段,有繁简两个网络一同训练,复杂的网络起到助推器的作用,通过参数共享和信息提供推动轻量网络更好的训练;在预测阶段,助推器网络脱离系统,轻量网络独自发挥作用,从而在不增加预测开销的情况下,提高预测效果。整个过程与火箭发射类似,所以我们命名该系统为“火箭发射”。
训练方式创新
我们框架的创新在于它新颖的训练方式:
1、繁简两个模型协同训练,协同训练有以下好处:
a) 一方面,缩短总的训练时间:相比传统teacer-student范式中,teacher网络和student网络先后分别训练,我们的协同训练过程减少了总的训练时间,这对在线广告系统这样,每天获得大量训练数据,不断更新模型的场景十分有用。
b) 另一方面,助推器网络全程提供soft target信息给轻量网络,从而达到指导轻量网络整个求解过程的目的,使得我们的方法,相比传统方法,获得了更多的指导信息,从而取得更好的效果。
2、采用梯度固定技术:训练阶段,限制两网络soft target相近的loss,只用于轻量网络的梯度更新,而不更新助推器网络,从而使得助推器网络不受轻量网络的影响,只从真实标记中学习信息。这一技术,使得助推器网络拥有更强的自由度来学习更好的模型,而助推器网络效果的提升,也会提升轻量网络的训练效果。
结构创新
助推器网络和轻量网络共享部分层的参数,共享的参数可以根据网络结构的变化而变化。一般情况下,两网络可以共享低层。在神经网络中,低层可以用来学习信息表示,低层网络的共享,可以帮助轻量网络获得更好的信息表示能力。
方法框架
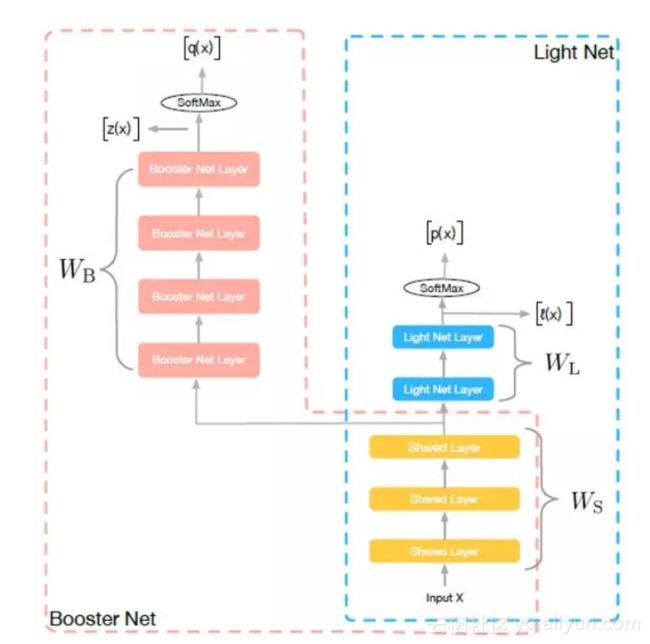
如图1所示,训练阶段,我们同时学习两个网络:Light Net 和Booster Net, 两个网络共享部分信息。我们把大部分的模型理解为表示层学习和判别层学习,表示层学习的是对输入信息做一些高阶处理,而判别层则是和当前子task目标相关的学习,我们认为表示层的学习是可以共享的,如multitask learning中的思路。所以在我们的方法里,共享的信息为底层参数(如图像领域的前几个卷积层,NLP中的embedding),这些底层参数能一定程度上反应了对输入信息的基本刻画。
整个训练过程,网络的loss如下:
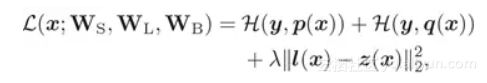
Loss包含三部分:第一项,为light net对ground truth的学习,第二项,为booster net对ground truth的学习,第三项,为两个网络softmax之前的logits的均方误差(MSE),该项作为hint loss, 用来使两个网络学习得到的logits尽量相似。
Co-Training
两个网络一起训练,从而booster net 会全程监督轻量网络的学习,一定程度上,booster net指导了light net整个求解过程,这与一般的teacher-student 范式下,学习好大模型,仅用大模型固定的输出作为soft target来监督小网络的学习有着明显区别,因为boosternet的每一次迭代输出虽然不能保证对应一个和label非常接近的预测值,但是到达这个解之后有利于找到最终收敛的解 。
Hint Loss
Hint Loss这一项在SNN-MIMIC中采用的是和我们一致的对softmax之前的logits做L2 Loss:
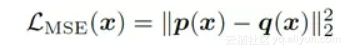
Hinton的KD方法是在softmax之后做KL散度,同时加入了一个RL领域常用的超参temperature T:
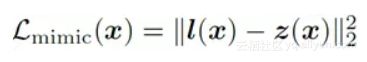
也有一个半监督的工作再softmax之后接L2 Loss:
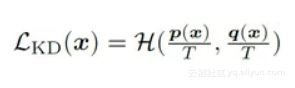

Gradient Block
由于booster net有更多的参数,有更强的拟合能力,我们需要给他更大的自由度来学习,尽量减少小网络对他的拖累,我们提出了gradient block的技术,该技术的目的是,在第三项hint loss进行梯度回传时,我们固定booster net独有的参数不更新,让该时刻,大网络前向传递得到的
,来监督小网络的学习,从而使得小网络向大网络靠近。
实验结果
实验方面,我们验证了方法中各个子部分的必要性。同时在公开数据集上,我们还与几个teacher-student方法进行对比,包括Knowledge Distillation(KD),Attention Transfer(AT)。为了与目前效果出色的AT进行公平比较,我们采用了和他们一致的网络结构宽残差网络(WRN)。实验网络结构如下:
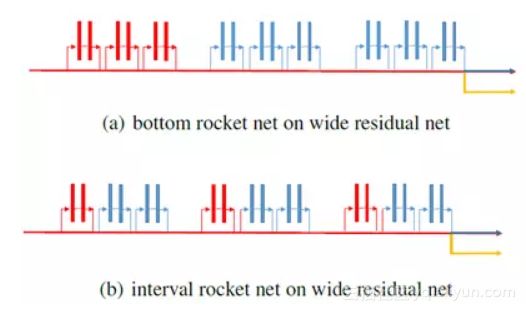
红色+黄色表示light net, 蓝色+红色表示booster net。(a)表示两个网络共享最底层的block,符合我们一般的共享结构的设计。(b)表示两网络共享每个group最底层的block,该种共享方式和AT在每个group之后进行attention transfer的概念一致。
各创新点的效果
我们通过各种对比实验,验证了参数共享和梯度固定都能带来效果的提升。
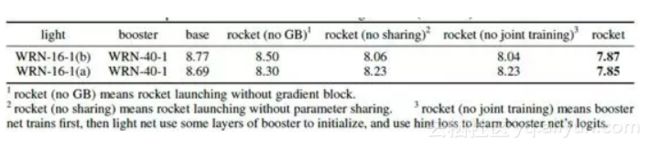
各种LOSS效果比较

轻量网络层数变化效果图
固定booster net, 改变light net的层数,rocket launching始终取得比KD要好的表现,这表明,light net始终能从booster net中获取有价值的信息。
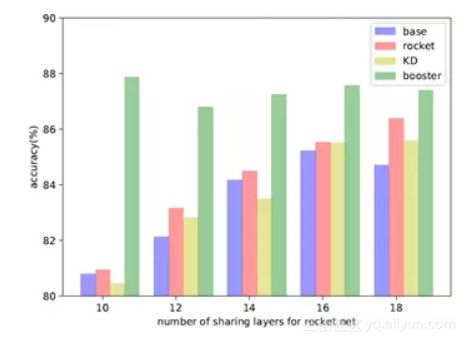
可视化效果
通过可视化实验,我们观察到,通过我们的方法,light net能学到booster net的底层group的特征表示。

公开数据集效果比较
除了自身方法效果的验证,在公开数据集上,我们也进行了几组实验。
在CIFAR-10上, 我们尝试不同的网络结构和参数共享方式,我们的方法均显著优于已有的teacher-student的方法。在多数实验设置下,我们的方法叠加KD,效果会进一步提升。

这里WRN-16-1,0.2M 表示wide residual net, 深度为16,宽度为1,参数量为0.2M。
同时在CIFAR-100和SVHN上,取得了同样优异的表现。

真实应用
同时,在阿里展示广告数据集上,我们的方法,相比单纯跑light net,可以将GAUC提升0.3%。
我们的线上模型在后面的全连接层只要把参数量和深度同时调大,就能有一个提高,但是在线的时候有很大一部分的计算耗时消耗在全连接层(embedding只是一个取操作,耗时随参数量增加并不明显),所以后端一个深而宽的模型直接上线压力会比较大。表格里列出了我们的模型参数对比以及离线的效果对比:

总结
在线响应时间对在线系统至关重要。本文提出的火箭发射式训练框架,在不提高预测时间的前提下,提高了模型的预测效果。为提高在线响应模型效果提供了新思路。目前Rocket Launching的框架为在线CTR预估系统弱化在线响应时间限制和模型结构复杂化的矛盾提供了可靠的解决方案,我们的技术可以做到在线计算被压缩8倍的情况下性能不变。在日常可以减少我们的在线服务机器资源消耗,双十一这种高峰流量场景更是保障算法技术不降级的可靠方案。
本文作者:热爱论文的
阅读原文
本文来自云栖社区合作伙伴“阿里技术”,如需转载请联系原作者。