Python爬取英雄联盟所有英雄皮肤
一、得到所有英雄信息
通过查询英雄联盟首页上的英雄信息全英雄地址,发现所有英雄信息是存放在一个js下的json文件,文件地址所有英雄json
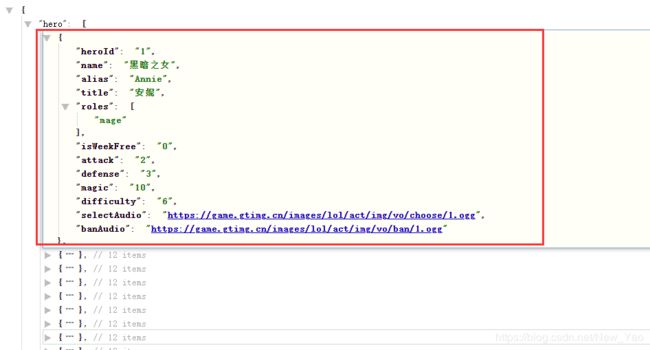
通过格式化此json文件,我们可以得到如下信息

通过分析得到hero为英雄信息,更进一步, 很容易猜到所有信息的含义,
二、确定英雄信息和英雄皮肤文件的关联关系
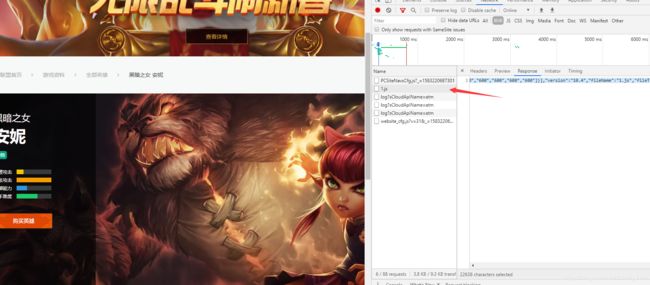
把这个js格式化出来查看,安妮信息地址 https://game.gtimg.cn/images/lol/act/img/js/hero/1.js

格式化后可以推断出url最后的n.js,n代表着英雄的heroId,继续查找
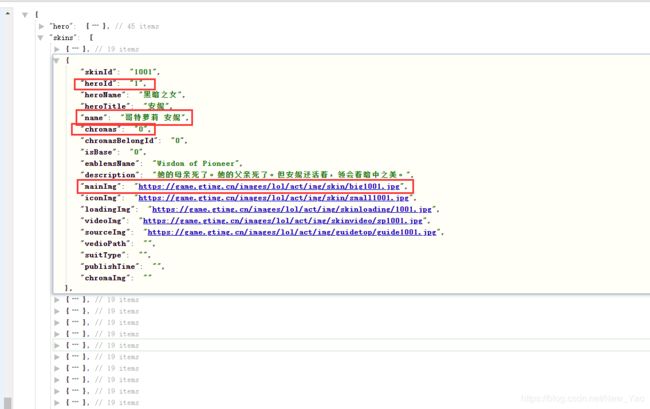
这里主要讲解一下chromas的意思,参数为0:是基础、1:炫彩,我们可以用这个参数来区分炫彩皮肤。
三、代码
# auth:jh
# date:2020年2月28日 15:00:03
import json
import os
import re
import random
import requests
from requests.exceptions import RequestException
# 本地保存地址
base_path = 'D:\\lol_hero_skin'
# 人机识别信息
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.122 Safari/537.36'}
# 处理文件名,window系统下有些字符不允许出现\/:*?"<>| K\DA皮肤引起此问题
def handle_str(_str):
temp = re.sub('[\\\/:*?"<>|]', '', _str)
if len(temp) == 0:
return ''.join(str(random.choice(range(10))) for _ in range(10))
return temp
# 下载图片
def download_img(img_url, _base_path, name):
r = requests.get(img_url, headers=headers, stream=True)
print(name, r.status_code) # 返回状态码
if r.status_code == 200:
name = handle_str(name)
open(_base_path + "\\" + name + '.jpg', 'wb').write(r.content) # 将内容写入图片
print("done")
del r
def load_hero_skin(heroId):
hero_img_url_prefix = 'https://game.gtimg.cn/images/lol/act/img/js/hero/'
hero_img_url_suffix = '.js'
response = requests.get(hero_img_url_prefix + heroId + hero_img_url_suffix, headers=headers)
html = json.loads(response.text) # 将网页内容以json返回
skinsList = html.get('skins') # 皮肤列表
heroName = html.get('hero').get('name') # 黑暗之女
heroTitle = html.get('hero').get('title') # 安妮
heroName = handle_str(heroName)
heroTitle = handle_str(heroTitle)
hero_skins_path = base_path + '\\' + heroName + ' ' + heroTitle
if not os.path.exists(hero_skins_path):
print('不存在,创建中。。。')
os.makedirs(hero_skins_path, 755)
for n in skinsList:
skinName = n.get('name')
_chromas = n.get('chromas') # 0:是基础、1:炫彩
mainImg = n.get('mainImg') # 皮肤图片地址
# print(skinName)
# print(_chromas)
# print(mainImg)
if _chromas == '0':
# 下载该图片
download_img(mainImg, hero_skins_path, skinName)
# 获取全部英雄对象json
def get_hero_json():
try:
hero_list_url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
response = requests.get(hero_list_url, headers=headers)
html = json.loads(response.text) # 将网页内容以json返回
print('版本:', html.get('version'))
print('文件名:', html.get('fileName'))
print('文件更新时间:', html.get('fileTime'))
print('总英雄数量:', len(html.get('hero')))
for i in html.get('hero'):
heroId = i.get('heroId')
load_hero_skin(heroId)
except RequestException:
return None
def main():
get_hero_json()
# 当.py文件被直接运行时,当.py文件以模块形式被导入时,if __name__ == '__main__'之下的代码块不被运行。
if __name__ == '__main__':
main()
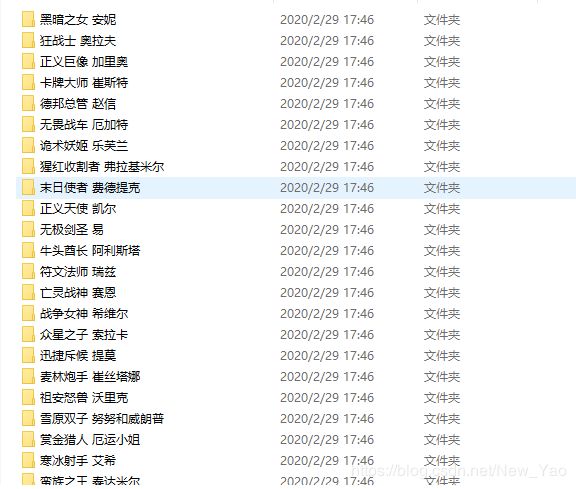
下载好后格式如下

使用及注意
- base_path 改为自己需要的地址即可运行
- 因为window系统下有些字符不允许出现/?"<>| K\DA皮肤引起此问题,此代码会特殊处理一下名字