ZED Board从入门到精通系列(八)——Vivado HLS实现矩阵相乘
终于到了HLS部分。HLS是High Level Synthesis的缩写,是一种可以将高级程序设计语言C,C++,SystemC综合为RTL代码的工具。
生产力的发展推动了设计模式。在电子技术初级阶段,人们关注的是RLC电路,通过建立微分方程求解电路响应。门级电路是对RLC的初步封装,人们进而采用布尔代数、卡诺图进行电路设计与分析。之后随着集成电路进一步发展,门电路可以集成为寄存器、触发器、ROM等宏单元,设计工具也变得更为高度模块化。算法级别的电路设计,则一直没有特别好的工具,直到出现了HLS。HLS可以将算法直接映射为RTL电路,实现了高层次综合。从这个层面上讲,System Generator也是一种高层次综合工具,因为它将matlab算法描述综合为RTL代码。如果今后机器学习、人工智能获得重大突破,或许会出现将人类自然语言综合为RTL代码的工具,不知我们是否能见证它的面世。
HLS的学习资源可以参考http://xilinx.eetrend.com/article/5096。本节给出较为通用的矩阵与向量相乘例子,从全串行到全并行进行了一步步优化实现。
矩阵实验室Matlab是比较常用的数学仿真软件。本博主用的是R2013a版本。为了验证矩阵向量相乘正确性,我们先用matlab生成测试矩阵和向量,并利用matlab计算结果。代码如下:
clear;
clc;
close all;
N = 5;
A = randi([1,100],N,N);
b = randi(100,N,1);
c = A*b;
KKK_SaveToCHeaderFile(A,'A.h');
KKK_SaveToCHeaderFile(b,'b.h');
KKK_SaveToCHeaderFile(c,'c.h');这里给出的是A*b = c的简单例子,A为5X5矩阵,b为5X1向量,结果c为5X1向量。其中KKK_SaveToCHeaderFile()是将矩阵、向量保存为C语言数组的子函数,定义如下:
function [] = KKK_SaveToCHeaderFile(var,fn)
fid = fopen(fn,'w');
var = reshape(var.',1,[]);
fprintf(fid,'%d,\r\n',var);
fclose(fid);
给出测试例程中,A如下:
82 10 16 15 66
91 28 98 43 4
13 55 96 92 85
92 96 49 80 94
64 97 81 96 68
b如下:
76
75
40
66
18
得到的c如下:
9800
15846
16555
23124
22939
运行matlab脚本之后,生成三个文件:A.h,b.h,c.h,这些是作为HLS程序的输入数据和参考结果。下面我们用HLS工具实现上述矩阵X向量的功能。第一步,运行Vivado HLS。
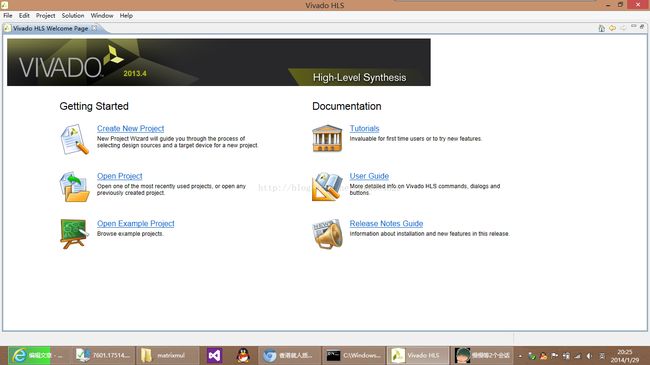
选择第一项,Create New Project,建立新工程MatrixMultiply

输入路径和工程名之后,点Next。
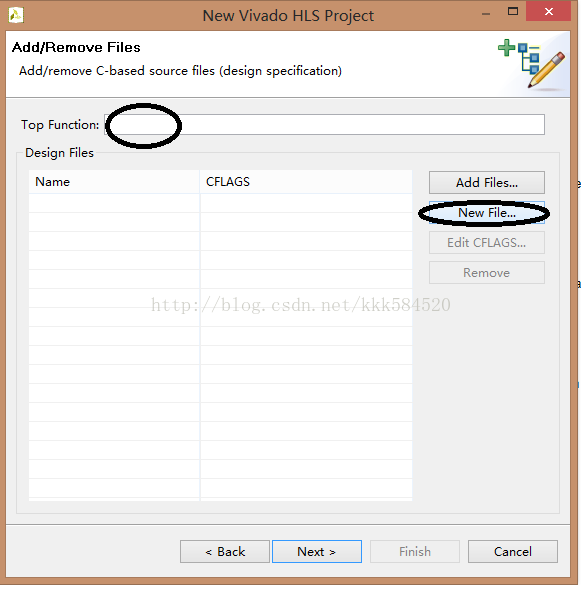
添加顶层模块文件。这里我们Top Functions输入MatrixMultiply,然后New File...,新建一个.c文件,命名为MatrixMultiply.c(后缀不要省略!),然后点Next
添加顶层文件测试脚本。这里New一个文件TestMatrixMultiply.c(后缀不要省略!),然后Add前面用Matlab生成的A.h,b.h,c.h,如下图所示: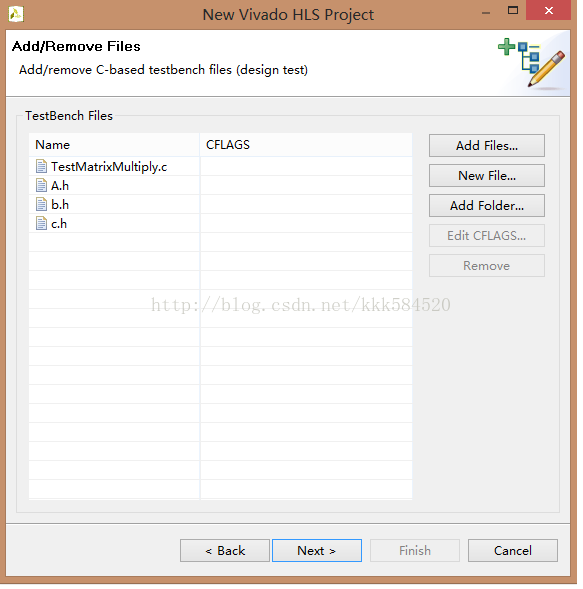
点Next,选择解决方案配置,如下图所示
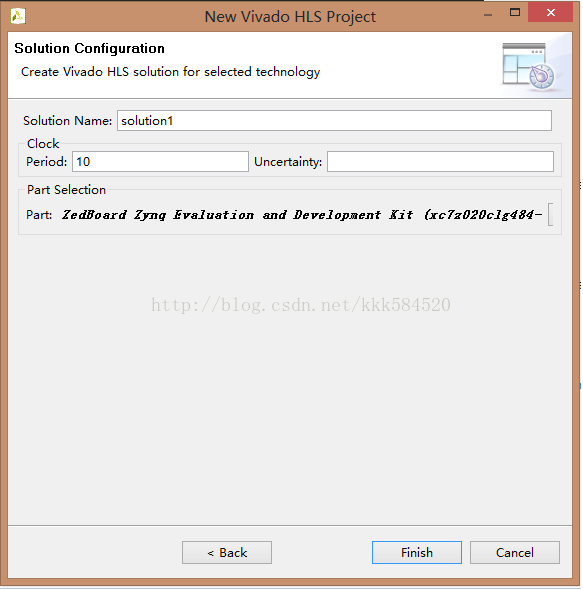
其余保持默认,只修改Part Selection部分,改为ZedBoard。改完后,Finish即可进入主界面,如下图所示

可以看出,Vivado HLS界面很像很像Xilinx SDK,不同的是前者负责PL部分开发,后者负责PS软件编写,定位不同决定了二者今后的路必然走向分歧。
将MatrixMultiply.c内容改为:
typedef int data_type;
#define N 5
void MatrixMultiply(data_type AA[N*N],data_type bb[N],data_type cc[N])
{
int i,j;
for(i = 0;i
将TestMatrixMultiply.c内容改为:
#include
typedef int data_type;
#define N 5
const data_type MatrixA[] = {
#include "A.h"
};
const data_type Vector_b[] = {
#include "b.h"
};
const data_type MatlabResult_c[] = {
#include "c.h"
};
data_type HLS_Result_c[N] = {0};
void CheckResult(data_type * matlab_result,data_type * your_result);
int main(void)
{
printf("Checking Results:\r\n");
MatrixMultiply(MatrixA,Vector_b,HLS_Result_c);
CheckResult(MatlabResult_c,HLS_Result_c);
return 0;
}
void CheckResult(data_type * matlab_result,data_type * your_result)
{
int i;
for(i = 0;i
首先进行C语言仿真验证,点这个按钮:

结果如下:
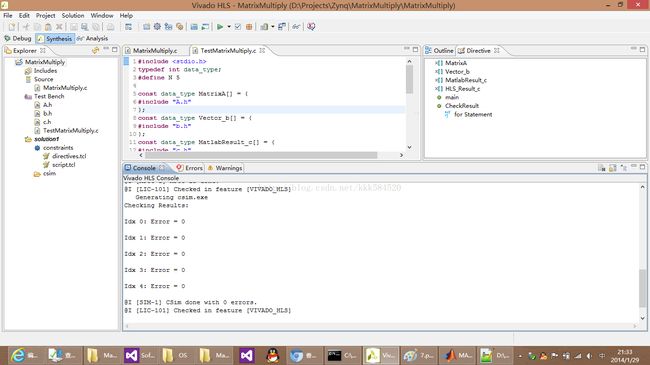
从C仿真输出看到,仿真结果与matlab计算结果一致,说明我们编写的C程序MatrixMultiply是正确的。
接下来进行综合,按C仿真后面那个三角形按钮,得到结果如下:

注意到,计算延迟为186个时钟周期。这是未经过优化的版本,记为版本1。
为了提高FPGA并行计算性能,我们接下来对它进行优化。
打开MatrixMultiply.c,点Directives页面,可以看到我们可以优化的对象。
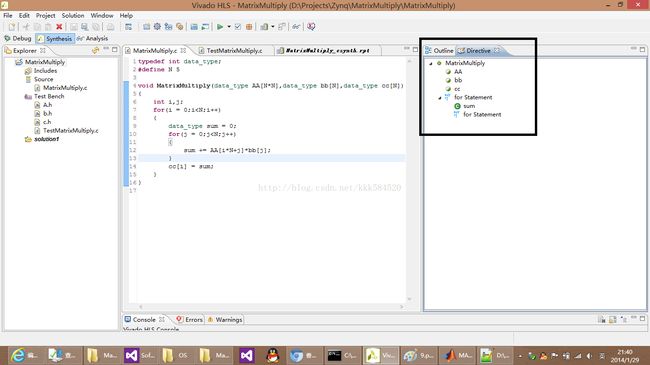
注意到矩阵和向量相乘是双层for循环结构。我们先展开最内层for循环,步骤如下:
右键点击最内侧循环,右键,然后Insert Directive...
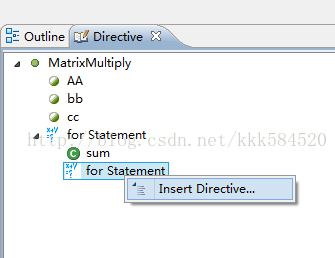
弹出对话框如下,Directives选择UNROLL,OK即可,后面所有都保持默认。
再次综合后,结果如下
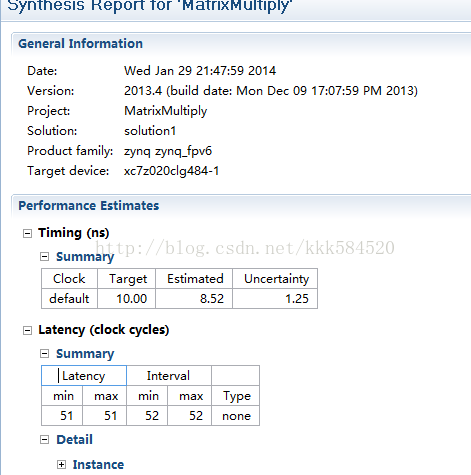
可见效果非常明显,延迟缩短到51个时钟周期。
用同样方法,展开外层循环,综合后结果如下:

计算延迟又降低了1/3!!!
可是代价呢?细心的你可能发现占用资源情况发生了较大变化,DSP48E1由最初的4个变为8个后来又成为76个!!!
FPGA设计中,延迟的降低,即速度提高,必然会导致面积的增大!
循环展开是优化的一个角度,另一个角度是从资源出发进行优化。我们打开Analysis视图,如下所示:
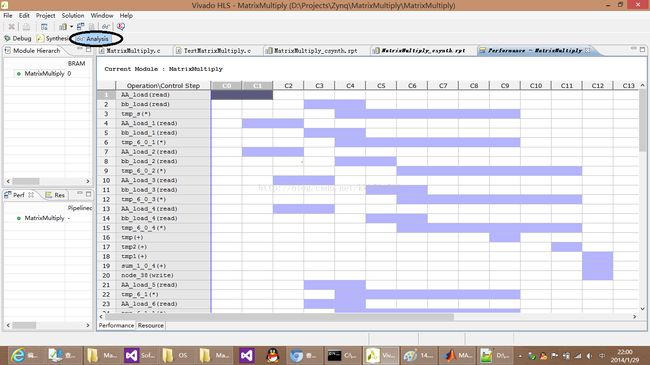
从分析视图可以看出各个模块的运行顺序,从而为优化提供更为明确的指引。我们发现AA_load导致了延迟,如果所有AA的值都能一次性并行取出,势必会加快计算效率!
回到Synthetic视图,为AA增加Directives:

选择Resources,再点Cores后面的方框,进入Vivado HLS core选择对话框

按上图进行选择。使用ROM是因为在计算矩阵和向量相乘时,AA为常数。确认。
仍然选择AA,增加Directives,如下图:
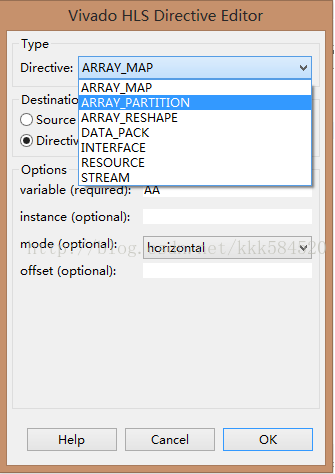
选择数组分解,mode选择完全complete,综合后结果如下图:
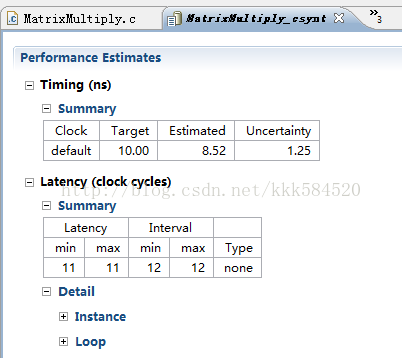
延迟进一步降低,已经降到11个时钟周期了!!!是否已经达到极限了呢???
答案是否定的。我们进入Analysis视图,看一下还有哪些地方可以优化的。经过对比发现bb也需要分解,于是按照上面的方法对bb进行资源优化,也用ROM-2P类型,也做全分解,再次综合,结果如下:

发现延迟进一步降低到8个时钟周期了!!!
老师,能不能再给力点?
可以的!!!!
我们进入分析视图,发现cc这个回写的步骤阻塞了整体流程,于是我们将cc也进行上述资源优化,只不过资源类型要变为RAM_2P,因为它是需要写入的。综合结果:
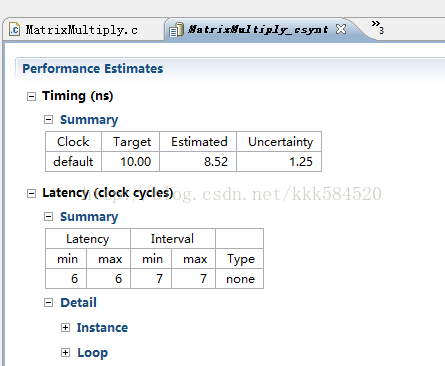
整体延迟已经降低到6个clk周期了!!!
再看Analysis视图:

延迟已经被压缩到极限了。。。。
老师,还能再给力点嘛?
答案是可以的!!!!
我们前面的所有运算都是基于整形数int,如果将数值精度降低,将大大节省资源。
注意现在DSP48E1需要100个!
看我们如何将资源再降下来。这就需要借助“任意精度”数据类型了。
HLS中除了C中定义的char,shrot,int,long,long long 之外,还有任意bit长度的int类型。我们将代码开头的data_type定义改为:
#include
typedef uint15 data_type;
由于matlab生成的随机数在1~100以内,乘积范围不会超过10000,于是取15bit就能满足要求。
首先验证下结果的正确性,用C Simulation试一下。结果如下:
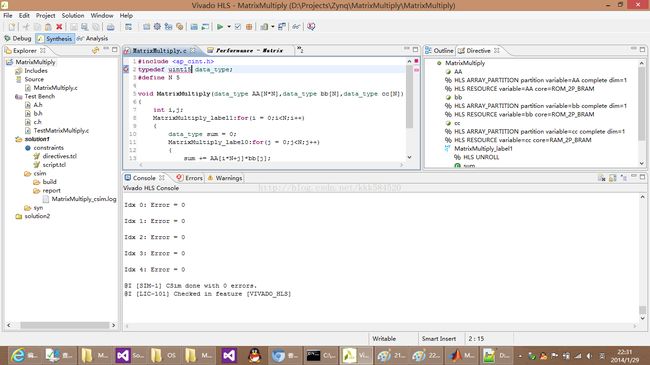
看来结果是正确的(当然也不排除数位不够,溢出后的结果相减也是0,需要你自己决定数值位宽)
综合一下,结果如下:
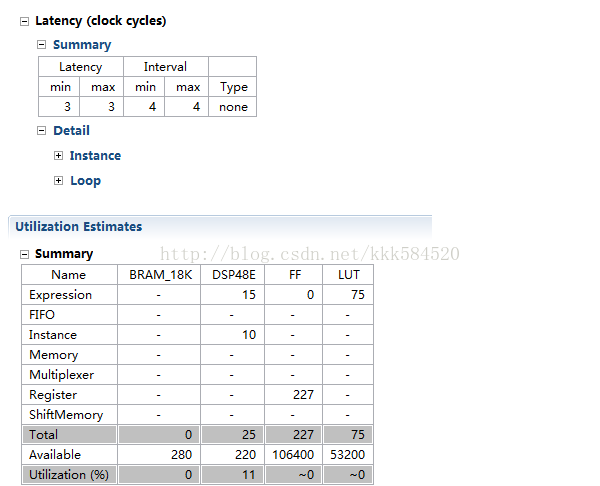
延迟缩短了一半,DSP48E1减少到原来的1/4!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
我和我的小伙伴们都震惊了!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
再看Analysis视图

可以发现我们的资源利用率已经达到极致,时序已经压缩到无以复加,实现了全并行计算,系统时钟完全可以达到100MHz,延迟仅3CLK,约30ns,相比matlab,得到约数百倍加速(matlab进行矩阵——向量相乘时采用浮点计算)。
通过本文实验,可以发现利用Vivado HLS实现从最初的C串行实现到全并行实现的步步优化,总结一下优化步骤:
(1)粗优化(循环展开、子函数内联)
(2)访存优化(块存储分散化、多端口存取)
(3)精优化(数值位宽优化、流水线优化)
(4)总线化(利用AXI4、AXI-Stream总线接口,降低整体访存需求)
利用HLS可以将原来的C算法快速部署到FPGA上,减少直接进行硬件编程的工作量。在很多情况下,优化手段可以和CUDA进行类比,相互借鉴。CUDA其实更接近软件接口,而HLS更接近硬件编程接口,或许今后两者会在新的层次上融合为统一架构语言。