在tensorflow2.2中使用Keras自定义模型的指标度量
使用Keras和tensorflow2.2可以无缝地为深度神经网络训练添加复杂的指标
Keras对基于DNN的机器学习进行了大量简化,并不断改进。这里,我们将展示如何基于混淆矩阵(召回、精度和f1)实现度量,并展示如何在tensorflow 2.2中非常简单地使用它们。
当考虑一个多类问题时,人们常说,如果类是不平衡的,那么准确性就不是一个好的度量标准。虽然这是肯定的,但是当所有的类新练的不完全拟合时,即使数据集是平衡的,准确性也是一个糟糕的度量标准。
在本文中,我将使用Fashion MNIST来进行说明。然而,这并不是本文的唯一目标,因为这可以通过在训练结束时简单地在验证集上绘制混淆矩阵来实现。我们在这里讨论的是轻松扩展keras.metrics的能力。用来在训练期间跟踪混淆矩阵的度量,可以用来跟踪类的特定召回、精度和f1,并使用keras按照通常的方式绘制它们。
在训练中获得班级特定的召回、精度和f1至少对两件事有用:
我们可以看到训练是否稳定,每个类的损失在图表中显示的时候没有跳跃太多
我们可以使用一些技巧-早期停止甚至动态改变类权值。
自tensorflow 2.2以来,添加了新的模型方法train_step和test_step,将这些定制度量集成到训练和验证中变得非常容易。还有一个关联predict_step,我们在这里没有使用它,但它的工作原理是一样的。
我们首先创建一个自定义度量类。虽然还有更多的步骤,它们在参考的jupyter笔记本中有所体现,但重要的是实现API并与Keras 训练和测试工作流程的其余部分集成在一起。这就像实现和update_state一样简单,update_state接受真实的标签和预测,reset_states重新初始化度量。
class ConfusionMatrixMetric(tf.keras.metrics.Metric):
def update_state(self, y_true, y_pred,sample_weight=None):
self.total_cm.assign_add(self.confusion_matrix(y_true,y_pred))
return self.total_cm
def result(self):
return self.process_confusion_matrix()
def confusion_matrix(self,y_true, y_pred):
"""
Make a confusion matrix
"""
y_pred=tf.argmax(y_pred,1)
cm=tf.math.confusion_matrix(y_true,y_pred,dtype=tf.float32,num_classes=self.num_classes)
return cm
def process_confusion_matrix(self):
"returns precision, recall and f1 along with overall accuracy"
cm=self.total_cm
diag_part=tf.linalg.diag_part(cm)
precision=diag_part/(tf.reduce_sum(cm,0)+tf.constant(1e-15))
recall=diag_part/(tf.reduce_sum(cm,1)+tf.constant(1e-15))
f1=2*precision*recall/(precision+recall+tf.constant(1e-15))
return precision,recall,f1
在正常的Keras工作流中,方法结果将被调用,它将返回一个数字,不需要做任何其他事情。然而,在我们的例子中,我们返回了三个张量:precision、recall和f1,而Keras不知道如何开箱操作。
由于tensorflow 2.2,可以透明地修改每个训练步骤中的工作(例如,在一个小批量中进行的训练),而以前必须编写一个在自定义训练循环中调用的无限函数,并且必须注意用tf.功能启用自动签名。
class MySequential(keras.Sequential):
def train_step(self, data):
# Unpack the data. Its structure depends on your model and
# on what you pass to `fit()`. x, y = data with tf.GradientTape() as tape:
y_pred = self(x, training=True) # Forward pass
# Compute the loss value.
# The loss function is configured in `compile()`.
loss = self.compiled_loss(
y,
y_pred,
regularization_losses=self.losses,
) # Compute gradients
trainable_vars = self.trainable_variables
gradients = tape.gradient(loss, trainable_vars) # Update weights
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
self.compiled_metrics.update_state(y, y_pred)
output={m.name: m.result() for m in self.metrics[:-1]}
if 'confusion_matrix_metric' in self.metrics_names:
self.metrics[-1].fill_output(output)
return output
现在可以创建(使用上面的类而不是keras.Sequential)、编译并训练一个顺序模型(处理函数和子类化API的过程非常简单,只需实现上面的函数)。生成的历史记录现在有了val_F1_1等元素。
这样做的好处是,我们可以看到各个批次是如何训练的
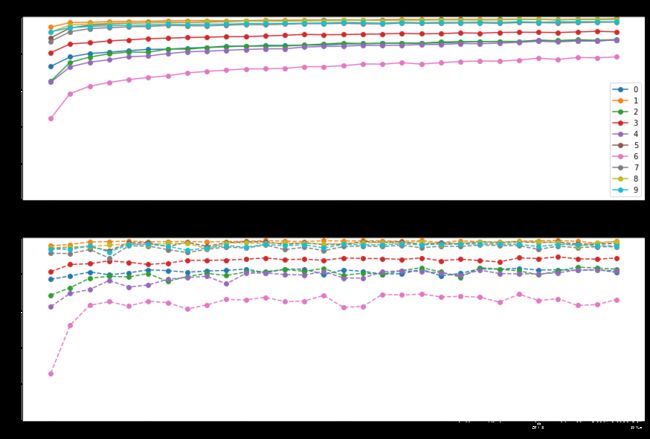
我们看到class 6的训练非常糟糕,验证集的F1值为。6左右,但是训练本身是稳定的(情节没有太多跳跃)。
最后,让我们看看混淆矩阵,看看类6发生了什么

在混淆矩阵中,真实类在y轴上,预测类在x轴上。我们看到,shirt(6),被错误标记为t-shirt(0),pullovers(2)和coats (4)。相反,错误标记为shirts的情况主要发生在t-shirts上。
这种类型的错误是合理的,我将在另一篇文章中讨论在这种情况下如何改进培训。
最后做一个总结:我们只用了一些简单的代码就使用Keras无缝地为深度神经网络训练添加复杂的指标,通过这些代码能够帮助我们在训练的时候更高效的工作。以下是本文的代码:
https://github.com/borundev/ml_cookbook/blob/master/Custom%20Metric%20(Confusion%20Matrix)%20and%20train_step%20method.ipynb
作者:Borun Chowdhury Ph.D.
deephub翻译组