Tensorflow2.0 VGG实现图片分类
VGG16网络
论文链接:https://arxiv.org/abs/1409.1556
VGG网络是在2014年由牛津大学计算机视觉组和谷歌公司的研究员共同开发的。VGG由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用最大池化分开,所有隐层的激活单元都采用ReLU函数。通过反复堆叠3x3的小卷积核和2x2的最大池化层,VGGNet成功的搭建了16-19层的深度卷积神经网络。VGG的结构图如下:

数据集
数据集下载:http://download.tensorflow.org/example_images/flower_photos.tgz
采用五类花卉数据集,类别是:雏菊,蒲公英,玫瑰,向日葵,郁金香,如下图所示:

本次实验样本数量如下表:
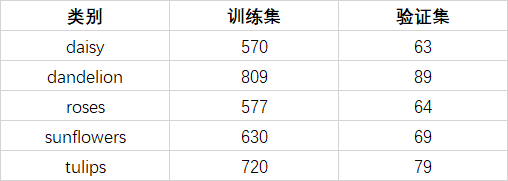
对数据集进行分类,90%训练集,10%验证集
代码
#导入相应的库
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers, models, Model, Sequential
import matplotlib.pyplot as plt
from tensorflow.keras.callbacks import ReduceLROnPlateau,EarlyStopping
import tensorflow as tf
import json
import os
# GPU 设置
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
#设置图片的大小,路径,batch_size,epoch
im_height = 224
im_width = 224
batch_size = 128
epochs = 15
image_path = "./data_set/flower_data/"
train_dir = image_path + "train"
validation_dir = image_path + "val"
# 图像预处理(训练集图片运用图像增强)
train_image_generator = ImageDataGenerator( rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# 图像预处理
validation_image_generator = ImageDataGenerator(rescale=1./255)
#训练集数据生成器,one-hot编码,打乱数据
train_data_gen = train_image_generator.flow_from_directory(directory=train_dir,
batch_size=batch_size,
shuffle=True,
target_size=(im_height, im_width),
class_mode='categorical')
#训练集图片总数
total_train = train_data_gen.n
#验证集数据生成器
val_data_gen = validation_image_generator.flow_from_directory(directory=validation_dir,
batch_size=batch_size,
shuffle=False,
target_size=(im_height, im_width),
class_mode='categorical')
#验证集图片总数
total_val = val_data_gen.n
#VGG16预训练网络
covn_base = tf.keras.applications.vgg16.VGG16(weights='imagenet',include_top=False)
covn_base.trainable = True
#冻结前面的层,训练最后四层
for layers in covn_base.layers[:-4]:
layers.trainable = False
#构建模型
model = tf.keras.Sequential()
model.add(covn_base)
model.add(tf.keras.layers.GlobalAveragePooling2D())
model.add(tf.keras.layers.Dense(256, activation='relu'))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(5, activation='softmax'))
model.summary()
#编译模型,初始学习率0.001
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=False),
metrics=["accuracy"])
#监视'val_loss',当两个epoch不变时,学习率减小为1/10
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=2, verbose=1)
#开始训练
history = model.fit(x=train_data_gen,
steps_per_epoch=total_train // batch_size,
epochs=epochs,
validation_data=val_data_gen,
validation_steps=total_val // batch_size,
callbacks=[reduce_lr])
# 记录准确率和损失值
history_dict = history.history
train_loss = history_dict["loss"]
train_accuracy = history_dict["accuracy"]
val_loss = history_dict["val_loss"]
val_accuracy = history_dict["val_accuracy"]
# 绘制损失值
plt.figure()
plt.plot(range(epochs), train_loss, label='train_loss')
plt.plot(range(epochs), val_loss, label='val_loss')
plt.legend()
plt.xlabel('epochs')
plt.ylabel('loss')
# 绘制准确率
plt.figure()
plt.plot(range(epochs), train_accuracy, label='train_accuracy')
plt.plot(range(epochs), val_accuracy, label='val_accuracy')
plt.legend()
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()
训练结果
训练到第15个epoch是时准确率达到92.5%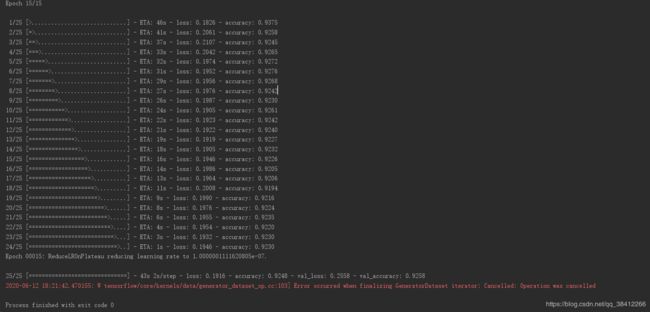
准确率

损失值
