ELK搭建
使用外国大佬的开源项目,基本不要改什么就可快速搭建一套单机版ELK用于练手。
注意:logstash已被我改造,如果以该项目构建ELK记得更改logstash.conf。
ELK项目github链接: https://github.com/deviantony/docker-elk
这里对es不做过多描述,主要针对filebeat和logstash讲解。
什么是Filebeat
Filebeat是一个轻量级的托运人,用于转发和集中日志数据。Filebeat作为代理安装在服务器上,监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
Filebeat的工作原理:启动Filebeat时,它会启动一个或多个输入,这些输入将查找您为日志数据指定的位置。对于Filebeat找到的每个日志,Filebeat启动一个收集器。每个收集器为新内容读取单个日志,并将新日志数据发送到libbeat,libbeat聚合事件并将聚合数据发送到您为Filebeat配置的输出。
官方流程图如下:
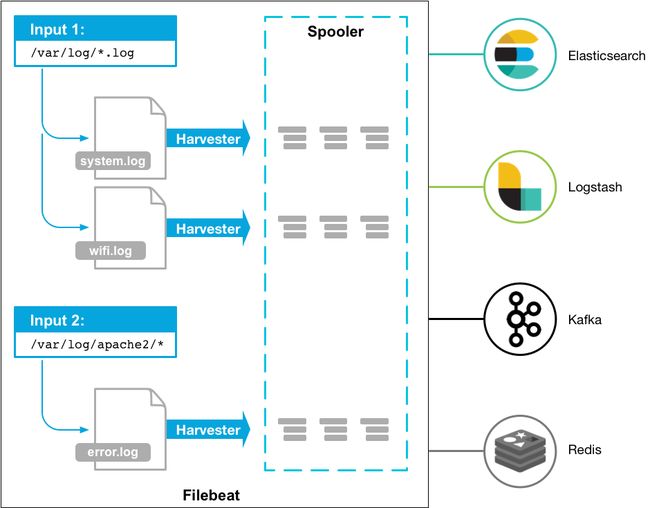
什么是Logstash
Logstash是一个具有实时流水线功能的开源数据收集引擎。Logstash可以动态统一来自不同来源的数据,并将数据标准化为您选择的目的地。为各种高级下游分析和可视化用例清理和民主化所有数据。
Logstash的优势:
- Elasticsearch的摄取主力
水平可扩展的数据处理管道,具有强大的Elasticsearch和Kibana协同作用 - 可插拔管道架构
混合,匹配和编排不同的输入,过滤器和输出,以便在管道协调中发挥作用 - 社区可扩展和开发人员友好的插件生态系统
提供超过200个插件,以及创建和贡献自己的灵活性
采用Springboot构建一个Demo测试
接着进入正文,先讲下我的需求。
1. 项目日志生成在某个路径,如/var/log/project,里面有warn,info,error目录,分别对应不同级别的日志,我需要采集这些日志。
2. 我需要采集特定格式的日志,如"[2018-11-24 08:33:43,253][ERROR][http-nio-8080-exec-4][com.hh.test.logs.LogsApplication][code:200,msg:测试录入错误日志,param:{}]"
3. 筛选采集到的日志,生成自定义字段,如datatime,level,thread,class,msg
ELK以搭好,由elasticsearch+logstash+kibana 组成,
本文的filebeat作用是采集特定目录下的日志,并将其发送出去,但是它只能采集并无法对数据进行筛选,这时候就用到logstash了,logstash拥有众多插件可提供过滤筛选功能,由于logstash本身是基于jdk的,所以占用内存较大,而filebeat相较下,占用的内存就不是很多了。有图有真相:
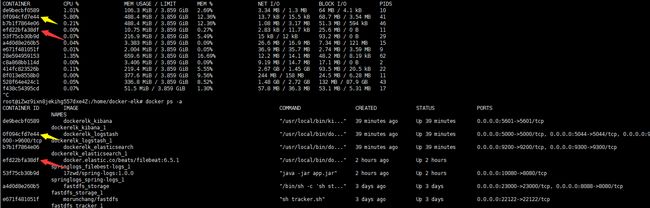
所以可采用如下的方案采集筛选日志:
- 每个项目都伴随着一个filebeat采集日志,你只需给他配置日志所在目录(可用正则匹配)即可,它会进行监视,如有新增日志会自动将日志采集发送到你配置的输出里,一般配 置的输出有kafka和redis、logstash、elasticsearch,这里为了筛选格式,采用logstash进行处理。
- 配置filebeat多模块,为众多项目配置日志目录路径进行日志采集并发送到logstash筛选过滤在转发给elasticsearch。
filebeat.yml配置
参考配置,只列出我用到的,详情见官方文档:
filebeat:
prospectors:
- type: log
//开启监视,不开不采集
enable: true
paths: # 采集日志的路径这里是容器内的path
- /var/log/elkTest/error/*.log
# 日志多行合并采集
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
# 为每个项目标识,或者分组,可区分不同格式的日志
tags: ["java-logs"]
# 这个文件记录日志读取的位置,如果容器重启,可以从记录的位置开始取日志
registry_file: /usr/share/filebeat/data/registry
output:
# 输出到logstash中,logstash更换为自己的ip
logstash:
hosts: ["logstash:5044"]
注:6.0以上该filebeat.yml需要挂载到/usr/share/filebeat/filebeat.yml,另外还需要挂载/usr/share/filebeat/data/registry 文件,避免filebeat容器挂了后,新起的重复收集日志。
logstash.conf配置
我用到的logstash并不是用来采集日志的,而是对日志进行匹配筛选,所以不要跟随项目启动,只需单独启动,暴露5044端口,能接收到filebeat发送日志即可,也就是说,它只是起到一个加工并转发给elasticsearch的作用而已。
配置参考:
input {
beats {
port => 5044
}
}
filter {
if "java-logs" in [tags]{
grok {
# 筛选过滤
match => {
"message" => "(?\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3})\]\[(?[A-Z]{4,5})\]\[(?[A-Za-z0-9/-]{4,40})\]\[(?[A-Za-z0-9/.]{4,40})\]\[(?.*)"
}
remove_field => ["message"]
}
# 不匹配正则则删除,匹配正则用=~
if [level] !~ "(ERROR|WARN|INFO)" {
# 删除日志
drop {}
}
}
}
output {
elasticsearch {
hosts => "elasticsearch:9200"
}
}
备注:
#grok 里边有定义好的现场的模板你可以用,但是更多的是自定义模板,规则是这样的,小括号里边包含所有一个key和value,例子:(?value),比如以下的信息,第一个我定义的key是data,表示方法为:? 前边一个问号,然后用<>把key包含在里边去。value就是纯正则了,这个我就不举例子了。这个有个在线的调试库,可以供大家参考,
http://grokdebug.herokuapp.com/
上面我自定义的格式是:
{
"date": [
[
"2018-11-24 02:38:13,995"
]
],
"level": [
[
"INFO"
]
],
"thread": [
[
"http-nio-8080-exec-1"
]
],
"class": [
[
"com.hh.test.logs.LogsApplication"
]
],
"msg": [
[
"code:200,msg:测试录入错误日志,param:java.lang.ArithmeticException: / by zero]"
]
]
}
效果展示
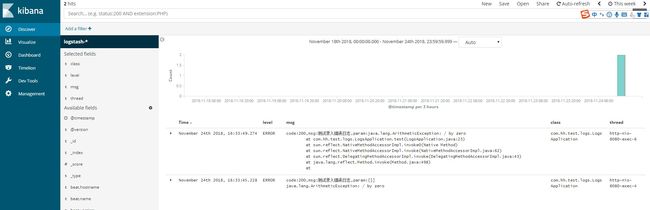
测试项目以上传到github
地址: https://github.com/liaozihong/ELK-CollectionLogs
参考链接:
ELK 之Filebeat 结合Logstash
Grok Debugger
ELK logstash 配置语法(24th)
Filebeat官方文档
Logstash官方文档