用 PyTorch 实现一个简单的分类器
回想了一下自己关于 pytorch 的学习路线,一开始找的各种资料,写下来都能跑,但是却没有给自己体会到学习的过程。有的教程一上来就是写一个 cnn,虽然其实内容很简单,但是直接上手容易让人找不到重点,学的云里雾里。有的教程又浅尝辄止,师傅领到了门槛跟前,总感觉自己还没有进门,教程就结束了。
所以我总结了一下自己当初学习的路线,准备继续深入巩固自己的 pytorch 基础;另一方面,也想从头整理一个教程,从没有接触过 pytorch 开始,到完成一些最新论文里面的工作。以自己的学习笔记整理为主线,大家可以针对参考。
第一篇笔记,我们先完成一个简单的分类器。主要流程分为以下三个部分:
1,自定义生成一个训练集,具体为在二维平面上的一些点,分为两类;
2,构建一个浅层神经网络,实现对特征的拟合,主要是明白在 pytorch 中网络结构如何搭建;
3,完成训练和测试部分的工作,熟悉 pytorch 如何对网络进行训练和测试。
1. 自定义生成数据集
n_data = torch.ones(100, 2)
x0 = torch.normal(2*n_data, 1)
y0 = torch.zeros(100)
x1 = torch.normal(-2*n_data, 1)
y1 = torch.ones(100)
x = torch.cat((x0, x1)).type(torch.FloatTensor)
y = torch.cat((y0, y1)).type(torch.LongTensor)
这篇文章我们先考虑在一个自己定义的简单数据集上实现分类,这样子可以最简单的了解一个神经网络的模型,如何用 pytorch 搭建起来。
这个代码对 numpy 比较熟悉的同学应该也可以猜出来它的内容,只是在 numpy 中是一个 numpy array,在 pytorch 中是一个 tensor。这里我简单的介绍一下这几行代码的作用,给有需要的同学捋顺思路。
首先 n_data 是基准数据,用来生成其它数据,内容为一个 100 行 2 列 的 tensor,其中的值都为 1。x0 是一类数据的坐标值,通过这个 n_data 来生成。
具体的生成的办法是用 torch.normal() 这个函数,第一个参数为 mean,第二个参数是 std。所以返回的结果 x0 是一个和 n_data 形状一样,但是其中的数据在以 2 为平均值,以 1 为标准差的正态分布中随机选取的。y0 则是一个 100 维的 tensor,其中的值都为 0。
我们可以这样理解 x0 和 y0,x0 的形状是 100 行 2 列的 tensor,其中的值以 2 为中心进行随机分布,符合正态分布,而这些点的标签我们设置为 y0,也就是 0。与此相反,x1 对应的中心为 -2,且标签为 y1,也就是每个点的标签都为 1。
最后生成的 x 和 y,就是将所有的数据合并起来,x0 和 x1 合并起来作为数据,y0 和 y1 合并起来作为标签。
2. 构建一个浅层神经网络
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.n_hidden = torch.nn.Linear(n_feature, n_hidden)
self.out = torch.nn.Linear(n_hidden, n_output)
def forward(self, x_layer):
x_layer = torch.relu(self.n_hidden(x_layer))
x_layer = self.out(x_layer)
x_layer = torch.nn.functional.softmax(x_layer)
return x_layer
net = Net(n_feature=2, n_hidden=10, n_output=2)
# print(net)
optimizer = torch.optim.SGD(net.parameters(), lr=0.02)
loss_func = torch.nn.CrossEntropyLoss()
上面的 Net() 类就是如何构建一个神经网络的步骤。我们如果是第一次用 pytorch 写一个神经网络,那么这个就是一个足够简单的例子了。其中的内容由两部分组成,分别是 __init__() 函数和 forward() 函数。
大家可以简单的这样子理解:__init__() 函数中,是对网络结构的定义,都有哪些层,每层又有什么功能。例如这个函数中,self.n_hidden 就是定义了一个线性拟合函数,也就是全连接层,在此处相当于一个向隐藏层的映射。输入是 n_feature,输出是隐藏层的神经元个数 n_hidden。然后 self.out 也一样是一个全连接层,输入是刚才的隐藏层的神经元个数 n_hidden,输出是最后的输出结果 n_output。
接着就是 forward() 函数,在这里相当于定义我们神经网络的执行顺序。所以这里可以看到,先对输入的 x_layer 执行上面的隐藏层函数,也就是第一个全连接 self.n_hidden(),然后对输出再执行激活函数 relu。接下来如法炮制,经过一个输出层 self.out(),得到最后的输出。然后将输出 x_layer 返回。
optimizer 就是这里定义的优化方式,其中的 lr 是学习率的参数。然后损失函数我们选择交叉熵损失函数,也就是上面的最后一行代码。优化算法和损失函数,可以在 pytorch 中直接选择不同的 api 接口,形式上直接参考上面这种固定形式便可。
3. 完成训练和测试
for i in range(100):
out = net(x)
# print(out.shape, y.shape)
loss = loss_func(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
接下来我们看一下如何进行训练的过程。net() 是我们对 Net() 类实例化出来的一个对象,所以利用 net() 可以直接完成模型的运行,out 就是模型预测出来的结果,loss 则是和真实值按照交叉熵损失函数计算出来的误差。
下面的三行代码是一个标准形式,表示了如何进行梯度的反向传播。到此其实我们的训练已经完成了,这个网络现在可以直接拿来对测试的数据集进行预测分类了。
# train result
train_result = net(x)
# print(train_result.shape)
train_predict = torch.max(train_result, 1)[1]
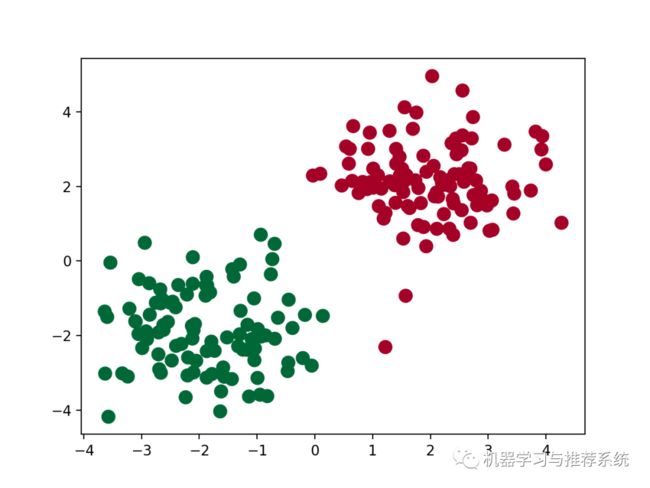
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=train_predict.data.numpy(), s=100, lw=0, cmap='RdYlGn')
plt.show()
为了让大家更好的理解这个模型的作用,这里我们来做一些可视化的工作,看看一个模型的学习效果。通过 python 很常见的一个数据可视化的库 matplotlib 可以实现这个目标,具体的 matplotlib 的用法就不介绍了。
这里的作用是显示出来训练好的模型对训练集的分类效果,可以理解为训练误差。
# test
t_data = torch.zeros(100, 2)
test_data = torch.normal(t_data, 5)
test_result = net(test_data)
prediction = torch.max(test_result, 1)[1]
plt.scatter(test_data[:, 0], test_data[:, 1], s=100, c=prediction.data.numpy(), lw=0, cmap='RdYlGn')
plt.show()
然后我们以 0 为 mean,随机生成一些数据,来看看模型会怎么去分类这些数据点。
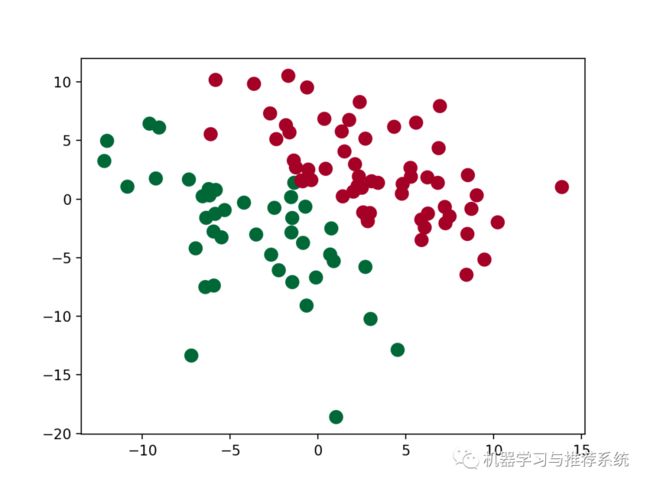
虽然没有画出来那条训练好的分割线,但是我们也可以看到模型学习了一个分割的界面,来将数据划分为两类。

推荐阅读:
一文读懂高并发情况下的常见缓存问题
用 Django 开发基于以太坊智能合约的 DApp
一文读懂 Python 分布式任务队列 celery
5 分钟解读 Python 中的链式调用
用 Python 创建一个比特币价格预警应用
▼点击成为社区会员 喜欢就点个在看吧