Python web面试题整理 - 从放弃到入门 -day06
第四部分前端、框架和其他
Django:
1.django请求的生命周期?
- 概述
 首先我们知道HTTP请求及服务端响应中传输的所有数据都是字符串.
首先我们知道HTTP请求及服务端响应中传输的所有数据都是字符串.
在Django中,当我们访问一个的url时,会通过路由匹配进入相应的html网页中.
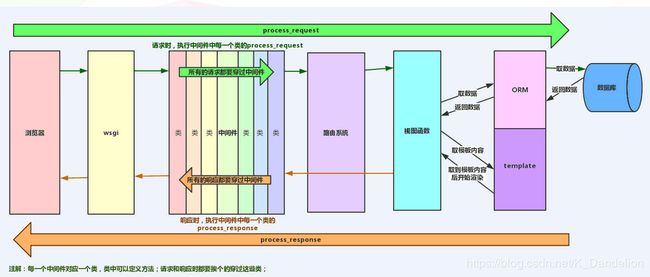
Django的请求生命周期是指当用户在浏览器上输入url到用户看到网页的这个时间段内,Django后台所发生的事情
而Django的生命周期内到底发生了什么呢??
当用户在浏览器中输入url时,浏览器会生成请求头和请求体发给服务端 请求头和请求体中会包含浏览器的动作(action),这个动作通常为get或者post,体现在url之中.
url经过Django中的wsgi,再经过Django的中间件,最后url到过路由映射表,在路由中一条一条进行匹配, 一旦其中一条匹配成功就执行对应的视图函数,后面的路由就不再继续匹配了.
视图函数根据客户端的请求查询相应的数据.返回给Django,然后Django把客户端想要的数据做为一个字符串返回给客户端.
客户端浏览器接收到返回的数据,经过渲染后显示给用户.
视图函数根据客户端的请求查询相应的数据后.如果同时有多个客户端同时发送不同的url到服务端请求数据
服务端查询到数据后,怎么知道要把哪些数据返回给哪个客户端呢??
因此客户端发到服务端的url中还必须要包含所要请求的数据信息等内容.
例如,http://www.aaa.com/index/?nid=user这个url中
客户端通过get请求向服务端发送的nid=user的请求,服务端可以通过request.GET.get(“nid”)的方式取得nid数据
客户端还可以通过post的方式向服务端请求数据.
当客户端以post的方式向服务端请求数据的时候,请求的数据包含在请求体里,这时服务端就使用request.POST的方式取得客户端想要取得的数据
需要注意的是,request.POST是把请求体的数据转换一个字典,请求体中的数据默认是以字符串的形式存在的.
2.什么是wsgi?
什么是WSGI协议
Web服务器网关接口,Web Server Gateway Interface (或简称 WSGI,读作“wizgy”)。
是一种协议、一种规定,遵守WSGI协议能够让web服务器和框架之间解耦,可以混合搭配服务器和框架,互相兼容。
.如何定义WSGI接口
在框架实现一个application函数(相当于框架的一个唯一入口),此函数要有两个参数,第一个是字典参数,第二个参数是服务器端一个函数的引用,用来处理header头。
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
return 'Hello World!'
上面的application()函数就是符合WSGI标准的一个HTTP处理函数,它接收两个参数:
environ:一个包含所有HTTP请求信息的dict对象;
start_response:一个发送HTTP响应的函数。
这个application()函数是由服务器来调用,服务器上要实现start_response()函数用来设置头信息。
3.列举django中的内置组件?
- 分页器的使用
- Form
- modelForm
- orm
- cookie和session
- 中间件
- 信号
内置组件详细解释
4.列举django中间件的5个方法?及django中间件的应用场景?
1、process_request : 请求进来时,权限认证 。
2、process_view : 路由匹配之后,能够得到视图函数
3、process_exception : 异常时执行
4、process_template_responseprocess : 模板渲染时执行
5、process_response : 请求有响应时执行
5.简述什么是FBV和CBV?
一个url对应一个视图函数,这个模式叫做FBV(Function Base Views)
除了FBV之处,Django中还有另外一种模式叫做CBV(Class Base views),即一个url对应一个类
例子:使用cbv模式来请求网页
路由信息:
urlpatterns = [
url(r'^fbv/',views.fbv),
url(r'^cbv/',views.CBV.as_view()),
]
视图函数配置:
from django.views import View
class CBV(View):
def get(self,request):
return render(request, "cbv.html")
def post(self,request):
return HttpResponse("cbv.get")
cbv.html网页的内容:
<body>
<form method="post" action="/cbv/">
{% csrf_token %}
<input type="text">
<input type="submit">
</form>
</body>
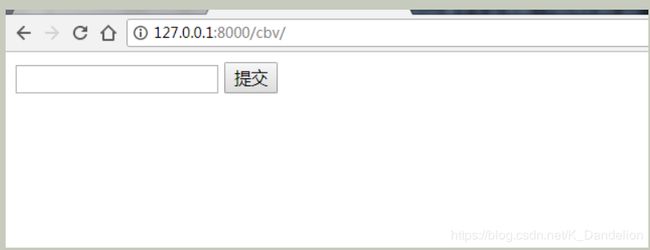
启动项目,在浏览器中输入http://127.0.0.1:8000/cbv/,回车,得到的网页如下:
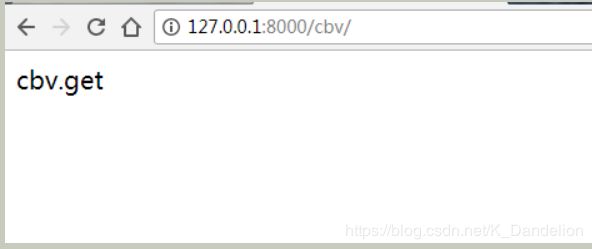
在input框中输入"hello",后回车,得到的网页如下:
 使用fbv的模式,在url匹配成功之后,会直接执行对应的视图函数.
使用fbv的模式,在url匹配成功之后,会直接执行对应的视图函数.
而如果使用cbv模式,在url匹配成功之后,会找到视图函数中对应的类,然后这个类回到请求头中找到对应的
Request Method.
如果是客户端以post的方式提交请求,就执行类中的post方法; 如果是客户端以get的方式提交请求,就执行类中的get方法
然后查找用户发过来的url,然后在类中执行对应的方法查询生成用户需要的数据.
2.1 fbv方式请求的过程
用户发送url请求,Django会依次遍历路由映射表中的所有记录,一旦路由映射表其中的一条匹配成功了,
就执行视图函数中对应的函数名,这是fbv的执行流程
2.2 cbv方式请求的过程
当服务端使用cbv模式的时候,用户发给服务端的请求包含url和method,这两个信息都是字符串类型
服务端通过路由映射表匹配成功后会自动去找dispatch方法,然后Django会通过dispatch反射的方式找到类中对应的方法并执行
类中的方法执行完毕之后,会把客户端想要的数据返回给dispatch方法,由dispatch方法把数据返回经客户端
例子,把上面的例子中的视图函数修改成如下:
from django.views import View
class CBV(View):
def dispatch(self, request, *args, **kwargs):
print("dispatch......")
res=super(CBV,self).dispatch(request,*args,**kwargs)
return res
def get(self,request):
return render(request, "cbv.html")
def post(self,request):
return HttpResponse("cbv.get")
打印结果:
<HttpResponse status_code=200, "text/html; charset=utf-8">
dispatch......
<HttpResponse status_code=200, "text/html; charset=utf-8">
需要注意的是:
以get方式请求数据时,请求头里有信息,请求体里没有数据
以post请求数据时,请求头和请求体里都有数据.
6.django的request对象是在什么时候创建的?
Request
我们知道当URLconf文件匹配到用户输入的路径后,会调用对应的view函数,并将 HttpRequest对象
作为第一个参数传入该函数。
Django 每一个view函数的第一个参数都是request,有没想过request里面到底有什么呢?
Django使用request和response对象在系统间传递状态。
当一个页面被请示时,Django创建一个包含请求元数据的 HttpRequest 对象。
然后Django调入合适的视图,把HttpRequest 作为视图函数的第一个参数 传入。每个视图要负责返回一个 HttpResponse
对象。
HttpRequest实例的属性包含了关于此次请求的大多数重要信息。 除了session外的所有属性都应该认为是只读的.
我们来看一看这个HttpRequest对象有哪些属性或者方法:
属性或者方法
7.如何给CBV程序添加装饰器?
#引入method_decorator模块
#1.直接在类上加装饰器
@method_decorator(test,name='dispatch')
class Loginview(View):
pass
#2.直接在处理的函数前加装饰器
@method_decorator(test)
def post(self,request,*args,**kwargs):
pass
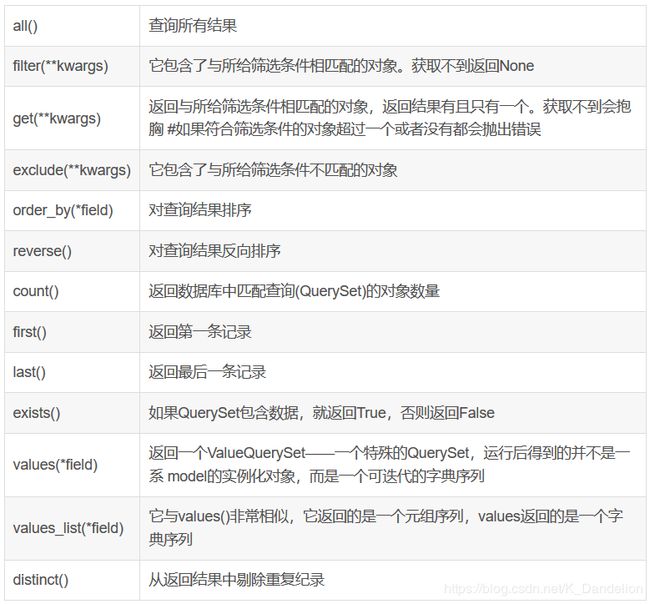
8.列举django orm中的所有方法?(QuerySet对象的所有方法)
9.only和defer的区别?
defer('id','name'):取出对象,字段除了id和name都有
only('id','name'):取的对象,只有id和name
如果点,依然能点出其它列,但是不要点了,因为取没有的列,会再次查询数据处。
ret=models.Author.objects.only('nid')
for i in ret:
# 查询不在的字段,会再次查询数据库,造成数据库压力大
print(i.name)
10.select_related和prefetch_related的区别?
总结
因为select_related()总是在单次SQL查询中解决问题,而prefetch_related()会对每个相关表进行SQL查询,因此select_related()的效率通常比后者高。
鉴于第一条,尽可能的用select_related()解决问题。只有在select_related()不能解决问题的时候再去想prefetch_related()。
你可以在一个QuerySet中同时使用select_related()和prefetch_related(),从而减少SQL查询的次数。
只有prefetch_related()之前的select_related()是有效的,之后的将会被无视掉。
select_related和prefetch_related描述
11.filter和exclude的区别?
context命名空间的component-scan通过扫描base-package属性指定的类包,从类的注解信息中获取bean的定义信息
<context:component-scan base-package="com.xxx" use-default-filters="true"/>
并通过和对信息进行过滤:
<context:component-scan base-package="com.xxx" use-default-filters="false">
<context:include-filter type="annotation" expression="org.springframework.stereotype.Controller" />
</context:component-scan>
<context:component-scan base-package="com.xxx">
<context:exclude-filter type="annotation" expression="org.springframework.stereotype.Controller" />
</context:component-scan>
其中,use-default-filters是一个不容忽视的属性,默认值为true,表示默认会对@Component、@Controller、@Service、@Reposity标注的bean进行扫描。context:component-scan先根据context:exclude-filter列出需要排除的黑名单,再通过context:include-filter列出需要包含的白名单。
下面的反例中,不但会扫描@Controller的bean,还会扫描@Component、@Service、@Reposity的bean
<context:component-scan base-package="com.xxx">
<context:include-filter type="annotation" expression="org.springframework.stereotype.Controller" />
</context:component-scan>
原因如上所述,use-default-filters默认为true,所以要显示指定为false
<context:component-scan base-package="com.xxx" use-default-filters="false">
<context:include-filter type="annotation" expression="org.springframework.stereotype.Controller" />
</context:component-scan>
总结:属性use-default-filters="false"和context:include-filter要一起使用,表示:只扫描指定注解的类。
12.列举django orm中三种能写sql语句的方法。
1.使用execute执行自定义的SQL
直接执行SQL语句(类似于pymysql的用法)
# 更高灵活度的方式执行原生SQL语句
from django.db import connection
cursor = connection.cursor()
cursor.execute("SELECT DATE_FORMAT(create_time, '%Y-%m') FROM blog_article;")
ret = cursor.fetchall()
print(ret)
2.使用extra方法 :queryset.extra(select={"key": "原生的SQL语句"})
3.使用raw方法
1.执行原始sql并返回模型
2.依赖model多用于查询
13.django orm 中如何设置读写分离?
对网站的数据库作读写分离(Read/Write Splitting)可以提高性能,在Django中对此提供了支持,下面我们来简单看一下。注意,还需要运维人员作数据库的读写分离和数据同步。
配置数据库
我们知道在Django项目的settings中,可以配置数据库,除了默认的数据库,我在下面又加了一个db2。因为是演示,我这里用的是默认的SQLite,如果希望用MySQL,看这里
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
},
'db2': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db2.sqlite3'),
},
}
创建models并执行数据库迁移
这里我简单创建一张产品表
from django.db import models
class Products(models.Model):
"""产品表"""
prod_name = models.CharField(max_length=30)
prod_price = models.DecimalField(max_digits=6, decimal_places=2)
创建完成后,执行数据库迁移操作:
python manage.py makemigrations # 在migrations文件夹下生成记录,迁移前检查
python manage.py migrate # 创建表
在migrations文件夹下生成记录,并在迁移前检查是否有问题,默认值检查defualt数据库,但是可以在后面的数据库路由类(Router)中通过allow_migrate()方法来指定是否检查其它的数据库。
其实第二步迁移默认有参数python manage.py migrate --database default ,在默认数据库上创建表。因此完成以上迁移后,执行python manage.py --database db2,再迁移一次,就可以在db2上创建相同的表。这样在项目根目录下,就有了两个表结构一样的数据库,分别是db.sqlite3和db2.sqlite3。
读写分离
手动读写分离
在使用数据库时,通过.using(db_name)来手动指定要使用的数据库
from django.shortcuts import HttpResponse
from . import models
def write(request):
models.Products.objects.using('default').create(prod_name='熊猫公仔', prod_price=12.99)
return HttpResponse('写入成功')
def read(request):
obj = models.Products.objects.filter(id=1).using('db2').first()
return HttpResponse(obj.prod_name)
自动读写分离
通过配置数据库路由,来自动实现,这样就不需要每次读写都手动指定数据库了。数据库路由中提供了四个方法。这里这里主要用其中的两个:def db_for_read()决定读操作的数据库,def db_for_write()决定写操作的数据库。
定义Router类
新建myrouter.py脚本,定义Router类:
class Router:
def db_for_read(self, model, **hints):
return 'db2'
def db_for_write(self, model, **hints):
return 'default'
配置Router
settings.py中指定DATABASE_ROUTERS
DATABASE_ROUTERS = ['myrouter.Router',]
可以指定多个数据库路由,比如对于读操作,Django将会循环所有路由中的db_for_read()方法,直到其中一个有返回值,然后使用这个数据库进行当前操作。
一主多从方案
网站的读的性能通常更重要,因此,可以多配置几个数据库,并在读取时,随机选取,比如:
class Router:
def db_for_read(self, model, **hints):
"""
读取时随机选择一个数据库
"""
import random
return random.choice(['db2', 'db3', 'db4'])
def db_for_write(self, model, **hints):
"""
写入时选择主库
"""
return 'default'
分库分表
在大型web项目中,常常会创建多个app来处理不同的业务,如果希望实现app之间的数据库分离,比如app01走数据库db1,app02走数据库
class Router:
def db_for_read(self, model, **hints):
if model._meta.app_label == 'app01':
return 'db1'
if model._meta.app_label == 'app02':
return 'db2'
def db_for_write(self, model, **hints):
if model._meta.app_label == 'app01':
return 'db1'
if model._meta.app_label == 'app02':
return 'db2'
更多请参考 官网
14.F和Q的作用?
一、F介绍
作用:操作数据表中的某列值,F()允许Django在未实际链接数据的情况下具有对数据库字段的值的引用,不用获取对象放在内存中再对字段进行操作,直接执行原生产sql语句操作。
通常情况下我们在更新数据时需要先从数据库里将原数据取出后方在内存里,
然后编辑某些属性,最后提交。例如:
obj = Order.objects.get(orderid='12')
obj.amount += 1
obj.order.save()
二、Q介绍
作用:对对象进行复杂查询,并支持&(and),|(or),~(not)操作符。
基本使用:
from django.db.models import Q
search_obj=Asset.objects.filter(Q(hostname__icontains=keyword)|Q(ip=keyword))
如果查询使用中带有关键字查询,Q对象一定要放在前面
Asset.objects.get(
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)),
question__startswith='Who')
参考:F和Q的作用
15.values和values_list的区别?
values : queryset类型的列表中是字典
values_list : queryset类型的列表中是元组
参考别人面试总结:django面试题(21道)