Chromium硬件加速渲染的OpenGL命令执行过程分析
在Chromium中,由于GPU进程的存在,WebGL端、Render端和Browser端的GPU命令是代理给GPU进程执行的。Chromium将它们要执行的GPU命令进行编码,然后写入到一个命令缓冲区中,最后传递给GPU进程。GPU进程从这个命令缓冲区读出GPU命令之后,就进行解码,然后调用对应的OpenGL函数。本文就详细分析WebGL端、Render端和Browser端执行GPU命令的过程。
老罗的新浪微博:http://weibo.com/shengyangluo,欢迎关注!
《Android系统源代码情景分析》一书正在进击的程序员网(http://0xcc0xcd.com)中连载,点击进入!
在前面Chromium硬件加速渲染的OpenGL上下文绘图表面创建过程分析一文提到,WebGL端、Render端和Browser端OpenGL上下文都是通过一个WebGraphicsContext3DCommandBufferImpl对象描述的,相应的WebGraphicsContext3DCommandBufferImpl类关系图如下所示:
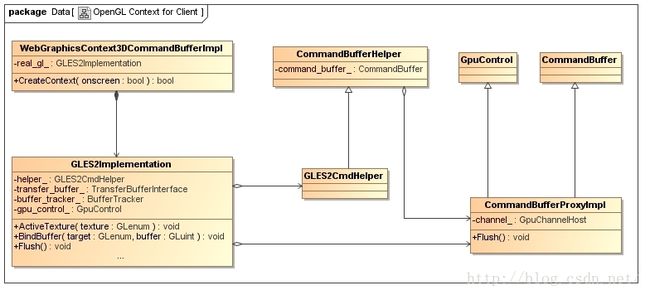
图1 WebGraphicsContext3DCommandBufferImpl类关系图
WebGraphicsContext3DCommandBufferImpl类的成员变量real_gl_指向一个GLES2Implementation对象。这个GLES2Implementation对象负责提供OpenGL接口给WebGL端、Render端和Browser端使用,是在WebGraphicsContext3DCommandBufferImpl类的成员函数CreateContext中创建的。
GLES2Implementation类的成员变量helper_指向一个GLES2CmdHelper对象,这个GLES2CmdHelper负责将WebGL端、Render端和Browser端通过GLES2Implementation类调用的OpenGL接口编码为GPU命令写入到一个命令缓冲区中。例如,WebGL端、Render端和Browser端调用GLES2Implementation类的成员函数ActiveTexture和BindBuffer时,GLES2CmdHelper类会将它们分别编码为gles2::cmds::ActiveTexture和gles2::cmds::BindBuffer命令写入到GPU命令缓冲区中。
当GLES2Implementation类的成员函数Flush被调用的时候,前面写入到命令缓冲区的GPU命令会提交给GPU进程。这个命令缓冲区是与GPU进程共享的,因此WebGL端、Render端和Browser端向GPU进程提交GPU命令时,只需要向其发送一个IPC消息即可。GLES2CmdHelper类是从CommandBufferHelper类继承下来的,后者的成员变量command_buffer_指向一个CommandBufferProxyImpl对象。从前面Chromium硬件加速渲染的OpenGL上下文绘图表面创建过程分析一文可以知道,这个CommandBufferProxyImpl对象是在GpuChannelHost类的成员函数CreateViewCommandBuffer或者CreateOffscreenCommandBuffer中创建的。CommandBufferHelper类通过调用CommandBufferProxyImpl类的成员函数Flush即可向GPU进程发送一个提交GPU命令的IPC消息。这个IPC消息最终通过CommandBufferProxyImpl类的成员变量channel_描述的一个GPU通道,即一个GpuChannelHost对象,发送给GPU进程的。
WebGL端、Render端和Browser端向GPU进程提交的GPU命令可能附带有资源数据,例如TexSubImage2DImpl命令附带有纹理数据,这些资源数据通过额外的共享缓冲区传递给GPU进程。用来传递资源数据的共享缓冲区由GLES2Implementation类的成员变量transfer_buffer_和buffer_tracker_描述。GLES2Implementation类的成员变量buffer_tracker_指向一个BufferTracker对象,这个BufferTracker对象用来传递特殊GPU命令附带的资源数据,并且也可以用来实现异步纹理上传。通用GPU命令附带的资源数据则通过GLES2Implementation类的成员变量transfer_buffer_描述的一个TransferBufferInterface接口进行传递。
GLES2Implementation类还有一个成员变量gpu_control_,它同样是指向在GpuChannelHost类的成员函数CreateViewCommandBuffer或者CreateOffscreenCommandBuffer中创建的CommandBufferProxyImpl对象。通过这个成员变量,可以在OpenGL上下文中插入一些同步点(Sync Point),用来在不同的OpenGL上下文中实现资源同步访问。
从上面的分析可以知道,GLES2Implementation类对WebGL端、Render端和Browser端来说是至关重要的,因此接下来我们分析WebGraphicsContext3DCommandBufferImpl类的成员变量real_gl_指向的GLES2Implementation对象的创建过程。如前所述,这个GLES2Implementation对象是在WebGraphicsContext3DCommandBufferImpl类的成员函数CreateContext中创建的,如下所示:
bool WebGraphicsContext3DCommandBufferImpl::CreateContext(bool onscreen) {
......
// Create the GLES2 helper, which writes the command buffer protocol.
gles2_helper_.reset(new gpu::gles2::GLES2CmdHelper(command_buffer_.get()));
if (!gles2_helper_->Initialize(mem_limits_.command_buffer_size)) {
......
}
......
// Create a transfer buffer used to copy resources between the renderer
// process and the GPU process.
transfer_buffer_ .reset(new gpu::TransferBuffer(gles2_helper_.get()));
......
// Create the object exposing the OpenGL API.
bool bind_generates_resources = false;
real_gl_.reset(
new gpu::gles2::GLES2Implementation(gles2_helper_.get(),
gles2_share_group,
transfer_buffer_.get(),
bind_generates_resources,
lose_context_when_out_of_memory_,
command_buffer_.get()));
......
if (!real_gl_->Initialize(
mem_limits_.start_transfer_buffer_size,
mem_limits_.min_transfer_buffer_size,
mem_limits_.max_transfer_buffer_size,
mem_limits_.mapped_memory_reclaim_limit)) {
......
}
......
}在创建GLES2Implementation对象之前,WebGraphicsContext3DCommandBufferImpl类的成员函数CreateContext首先创建了一个GLES2CmdHelper对象,并且保存在成员变量gles2_helper_中。这个GLES2CmdHelper对象的创建过程如下所示:
GLES2CmdHelper::GLES2CmdHelper(CommandBuffer* command_buffer)
: CommandBufferHelper(command_buffer) {
}参数command_buffer指向的是一个CommandBufferProxyImpl对象,它被传递给GLES2CmdHelper类的父类CommandBufferHelper的构造函数处理,如下所示:
CommandBufferHelper::CommandBufferHelper(CommandBuffer* command_buffer)
: command_buffer_(command_buffer),
...... {
}CommandBufferHelper类的构造函数将参数command_buffer指向的CommandBufferProxyImpl对象保存在成员变量command_buffer_中,以便以后可以使用。
回到WebGraphicsContext3DCommandBufferImpl类的成员函数CreateContext中,创建了一个GLES2CmdHelper对象之后,接下来就会调用它的成员函数Initialize进行初始化。GLES2CmdHelper类的成员函数Initialize是从父类CommandBufferHelper继承下来的,因此接下来我们分析CommandBufferHelper类的成员函数Initialize的实现,如下所示:
bool CommandBufferHelper::Initialize(int32 ring_buffer_size) {
ring_buffer_size_ = ring_buffer_size;
return AllocateRingBuffer();
}CommandBufferHelper类的成员函数Initialize要做的事情就是创建一块GPU命令缓冲区。这块GPU命令缓冲区的大小由参数ring_buffer_size指定,并且保存在成员变量ring_buffer_size_中。
CommandBufferHelper类的成员函数Initialize是通过调用另外一个成员函数AllocateRingBuffer创建GPU命令缓冲区的,如下所示:
bool CommandBufferHelper::AllocateRingBuffer() {
......
int32 id = -1;
scoped_refptr buffer =
command_buffer_->CreateTransferBuffer(ring_buffer_size_, &id);
......
ring_buffer_ = buffer;
ring_buffer_id_ = id;
command_buffer_->SetGetBuffer(id);
entries_ = static_cast(ring_buffer_->memory());
total_entry_count_ = ring_buffer_size_ / sizeof(CommandBufferEntry);
// Call to SetGetBuffer(id) above resets get and put offsets to 0.
// No need to query it through IPC.
put_ = 0;
CalcImmediateEntries(0);
return true;
} CommandBufferHelper类的成员函数AllocateRingBuffer首先是调用成员变量command_buffer_指向的一个CommandBufferProxyImpl对象的成员函数CreateTransferBuffer创建一块与GPU进程共享的内存。创建出来的共享内存使用一个gpu::Buffer对象描述,并且这个gpu::Buffer对象保存在成员变量ring_buffer_中。同时,创建出来的共享内存具有一个ID值,这个ID值保存在成员变量ring_buffer_id_中。
CommandBufferHelper类的成员函数AllocateRingBuffer接下来再调用成员变量command_buffer_指向的一个CommandBufferProxyImpl对象的成员函数SetGetBuffer告诉GPU进程,使用刚才创建出来的共享内存作为GPU命令缓冲区。
上述GPU命令缓冲区的内存地址可以通过调用前面获得的gpu::Buffer对象的成员函数memory获得。CommandBufferHelper类将GPU命令缓冲区看作是一个CommandBufferEntry数组。CommandBufferEntry是一个4个字节大小的联合体,它的定义如下所示:
// Union that defines possible command buffer entries.
union CommandBufferEntry {
CommandHeader value_header;
uint32_t value_uint32;
int32_t value_int32;
float value_float;
};我们主要是使用CommandBufferEntry联合体的成员变量value_header,它是一个类型为CommandHeader的结构体,用来描述一个GPU命令头,它的定义如下所示:
struct CommandHeader {
uint32_t size:21;
uint32_t command:11;
GPU_EXPORT static const int32_t kMaxSize = (1 << 21) - 1;
......
};从这里就可以看到,一个GPU命令头由两部分组成。第一个部分用来指定GPU命令的大小,占21位。第二部分用来指定GPU命令的ID,占11位。这意味着单单依赖GPU命令缓冲区,一个GPU命令加上其附带的数据,最大长度为CommandHeader::kMaxSize,即2^21 -1。如果一个GPU命令加上其附带的数据的大小超过CommandHeader::kMaxSize,那么就需要借助另外的共享内存缓冲区传递给GPU进程。
回到CommandBufferHelper类的成员函数AllocateRingBuffer中,CommandBufferHelper类将GPU命令缓冲区看作是一个CommandBufferEntry数组,这个数组的地址和大小就分别保存在成员变量entries_和total_entry_count_中。这里有一点需要注意的是,一个GPU命令在上述数组中可能会占据若干个CommandBufferEntry中。
CommandBufferHelper类的成员函数AllocateRingBuffer再接下来将成员变量put_的值初始为0,表示第一个GPU命令从上述CommandBufferEntry数组的位置0开始写入。这也意味着CommandBufferHelper类的成员变量put_是下一个GPU命令在上述CommandBufferEntry数组中的写入位置。
CommandBufferHelper类的成员函数AllocateRingBuffer最后调用另外一个成员函数CalcImmediateEntries计算当前CommandBufferEntry数组可用的CommandBufferEntry数量,并且保存在成员变量immediate_entry_count_中。以后CommandBufferHelper类会通过判断成员变量immediate_entry_count_来决定是否要通知GPU进程从GPU命令缓冲区读出已经写入的GPU命令并且进行处理,以便腾出空间写入后面的GPU命令。
接下来,我们继续分析CommandBufferProxyImpl类的成员函数CreateTransferBuffer和SetGetBuffer的实现,以便了解GPU命令缓冲区的创建过程。
CommandBufferProxyImpl类的成员函数CreateTransferBuffer的实现如下所示:
scoped_refptr CommandBufferProxyImpl::CreateTransferBuffer(
size_t size,
int32* id) {
......
int32 new_id = channel_->ReserveTransferBufferId();
scoped_ptr shared_memory(
channel_->factory()->AllocateSharedMemory(size));
if (!shared_memory)
return NULL;
......
if (!shared_memory->Map(size))
return NULL;
base::SharedMemoryHandle handle =
channel_->ShareToGpuProcess(shared_memory->handle());
......
if (!Send(new GpuCommandBufferMsg_RegisterTransferBuffer(route_id_,
new_id,
handle,
size))) {
......
}
*id = new_id;
scoped_refptr buffer(
gpu::MakeBufferFromSharedMemory(shared_memory.Pass(), size));
return buffer;
} CommandBufferProxyImpl类的成员函数CreateTransferBuffer的执行过程如下所示:
1. 调用成员变量channel_指向的一个GpuChannelHost对象的成员函数ReserveTransferBufferId分配一个ID,这个ID将作为接下来创建的一个块共享内存的ID。
2. 调用成员变量channel_指向的一个GpuChannelHost对象的成员函数factory获得一个GpuChannelHostFactory对象,然后调用该GpuChannelHostFactory对象的成员函数AllocateSharedMemory分配一块共享内存。这块共享内存使用一个SharedMemory对象描述。在Android平台上,创建出来的共享内存就是一块匿名共享内存。关于Android的匿名共享内存,可以参考Android系统匿名共享内存Ashmem(Anonymous Shared Memory)简要介绍和学习计划这个系列的文章。
3. 调用SharedMemory类的成员函数Map将前面创建出来的共享内存映射到当前进程的地址内间来,以便可以直接进行内存访问。
4. 调用成员变量channel_指向的一个GpuChannelHost对象的成员函数ShareToGpuProcess将为前面创建出来的共享内存创建一个句柄,以便接下来发送给GPU进程。
5. 向GPU进程发送一个类型为GpuCommandBufferMsg_RegisterTransferBuffer的IPC消息,通知它将前面创建出来的共享内存映射到自己的进程地址空间来,并且与前面分配出的ID对应起来。
6. 将前面创建的共享内存封装为一个gpu::Buffer对象,并且将该gpu::Buffer对象返回给调用者。
接下来,我们继续分析GPU进程接收和处理类型为GpuCommandBufferMsg_RegisterTransferBuffer的IPC消息。这个IPC消息由运行GPU进程中的与当前正在处理的CommandBufferProxyImpl对象对应的GpuCommandBufferStub对象的成员函数OnMessageReceived接收,如下所示:
bool GpuCommandBufferStub::OnMessageReceived(const IPC::Message& message) {
......
bool handled = true;
IPC_BEGIN_MESSAGE_MAP(GpuCommandBufferStub, message)
......
IPC_MESSAGE_HANDLER(GpuCommandBufferMsg_RegisterTransferBuffer,
OnRegisterTransferBuffer);
......
IPC_MESSAGE_UNHANDLED(handled = false)
IPC_END_MESSAGE_MAP()
......
return handled;
}GpuCommandBufferStub类的成员函数OnMessageReceived将类型为GpuCommandBufferMsg_RegisterTransferBuffer的IPC消息分发给成员函数OnRegisterTransferBuffer处理,如下所示:
void GpuCommandBufferStub::OnRegisterTransferBuffer(
int32 id,
base::SharedMemoryHandle transfer_buffer,
uint32 size) {
......
scoped_ptr shared_memory(
new base::SharedMemory(transfer_buffer, false));
if (!shared_memory->Map(size)) {
......
}
if (command_buffer_) {
command_buffer_->RegisterTransferBuffer(
id, gpu::MakeBackingFromSharedMemory(shared_memory.Pass(), size));
}
} GpuCommandBufferStub类的成员函数OnRegisterTransferBuffer根据传递过来的共享内存句柄创建了一个SharedMemory对象,并且通过调用这个SharedMemory对象的成员函数Map将传递过来的共享内存映射到自己的进程地址空间来。
从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文可以知道,GpuCommandBufferStub类的成员变量command_buffer_指向的是一个CommandBufferService对象,GpuCommandBufferStub类的成员函数OnRegisterTransferBuffer调用这个CommandBufferService对象的成员函数RegisterTransferBuffer将传递过来的共享内存与传递过来的ID对应起来。
CommandBufferService类的成员函数RegisterTransferBuffer的实现如下所示:
bool CommandBufferService::RegisterTransferBuffer(
int32 id,
scoped_ptr buffer) {
return transfer_buffer_manager_->RegisterTransferBuffer(id, buffer.Pass());
} CommandBufferService类的成员变量transfer_buffer_manager_指向的是一个TransferBufferManager对象,这里调用它的成员函数RegisterTransferBuffer管理参数buffer描述的一个共享内存,并且将该共享内存与参数id描述的ID对应起来。
CommandBufferProxyImpl类的成员函数CreateTransferBuffer创建共享内存的过程就分析到这里,接下来我们继续分析CommandBufferProxyImpl类的成员函数SetGetBuffer的实现,如下所示:
void CommandBufferProxyImpl::SetGetBuffer(int32 shm_id) {
......
Send(new GpuCommandBufferMsg_SetGetBuffer(route_id_, shm_id));
......
}CommandBufferProxyImpl类的成员函数SetGetBuffer向GPU进程发送一个类型为GpuCommandBufferMsg_SetGetBuffer的IPC消息。这个IPC消息由运行在GPU进程中的与当前正在处理的CommandBufferProxyImpl对象对应的GpuCommandBufferStub对象的成员函数OnMessageReceived接收,如下所示:
bool GpuCommandBufferStub::OnMessageReceived(const IPC::Message& message) {
......
bool handled = true;
IPC_BEGIN_MESSAGE_MAP(GpuCommandBufferStub, message)
......
IPC_MESSAGE_HANDLER_DELAY_REPLY(GpuCommandBufferMsg_SetGetBuf
OnSetGetBuffer);
......
IPC_MESSAGE_UNHANDLED(handled = false)
IPC_END_MESSAGE_MAP()
......
return handled;
}GpuCommandBufferStub类的成员函数OnMessageReceived将类型为GpuCommandBufferMsg_SetGetBuffer的IPC消息分发给成员函数OnSetGetBuffer处理,如下所示:
void GpuCommandBufferStub::OnSetGetBuffer(int32 shm_id,
IPC::Message* reply_message) {
......
if (command_buffer_)
command_buffer_->SetGetBuffer(shm_id);
Send(reply_message);
} GpuCommandBufferStub类的成员函数OnSetGetBuffer调用成员变量command_buffer_指向的一个CommandBufferService对象的成员函数SetGetBuffer将参数shm_id描述的一块共享内存作为GPU命令缓冲区。
CommandBufferService类的成员函数SetGetBuffer的实现如下所示:
void CommandBufferService::SetGetBuffer(int32 transfer_buffer_id) {
......
ring_buffer_ = GetTransferBuffer(transfer_buffer_id);
ring_buffer_id_ = transfer_buffer_id;
int32 size = ring_buffer_ ? ring_buffer_->size() : 0;
num_entries_ = size / sizeof(CommandBufferEntry);
put_offset_ = 0;
SetGetOffset(0);
if (!get_buffer_change_callback_.is_null()) {
get_buffer_change_callback_.Run(ring_buffer_id_);
}
......
}CommandBufferService类的成员函数SetGetBuffer首先调用另外一个成员函数GetTransferBuffer获得参数transfer_buffer_id对应的共享内存,如下所示:
scoped_refptr CommandBufferService::GetTransferBuffer(int32 id) {
return transfer_buffer_manager_->GetTransferBuffer(id);
} 参数id描述的就是前面创建的共享内存的ID。前面提到,这块内存是交给CommandBufferService类的成员变量transfer_buffer_manager_指向的一个TransferBufferManager对象管理,因此这里可以通过它来获得参数id描述的共享内存。
回到CommandBufferService类的成员函数SetGetBuffer中,获得了参数transfer_buffer_id描述的共享内存之后,就保存在成员变量ring_buffer_中,并且也将该共享内存的ID保存在成员变量ring_buffer_id_中。
与前面分析的CommandBufferHelper类一样,CommandBufferService类也将GPU命令缓冲区看作是一个CommandBufferEntry数组,并且将该CommandBufferEntry数组的地址保存成员变量num_entries_中。
CommandBufferService类的成员函数SetGetBuffer接下来将成员变量put_offset_的值初始化为0,表示Client端还没有GPU命令需要处理。以后每当Client端向GPU进程提供新的GPU命令时,CommandBufferService类的成员变量put_offset_都会进行更新,表示Client端最新提供的GPU命令在上述CommandBufferEntry数组的偏移位置。
CommandBufferService类的成员函数SetGetBuffer接下来调用另外一个成员函数SetGetOffset将另外一个成员变量get_offset_设置为0,如下所示:
void CommandBufferService::SetGetOffset(int32 get_offset) {
......
get_offset_ = get_offset;
}CommandBufferService类的成员变量get_offset_表示下一个要处理的GPU命令在CommandBufferEntry数组中的偏移位置。每处理一个GPU命令,这个成员变量的值都会被更新。
再回到 CommandBufferService类的成员函数SetGetBuffer中,它最后检查成员变量get_buffer_change_callback_是否指向一个Callback。如是指向了一个Callback,那么就会调用执行它,以便可以通知它Client端设置了一个GPU命令缓冲区。这个Callback的执行过程我们后面再分析。
这样,GPU命令缓冲区就创建好了。回到WebGraphicsContext3DCommandBufferImpl类的成员函数CreateContext中,创建和初始化了一个GLES2CmdHelper对象之后,接着再创建一个TransferBuffer对象,并且保存在成员变量transfer_buffer_中。这个TransferBuffer对象的创建过程如下所示:
TransferBuffer::TransferBuffer(
CommandBufferHelper* helper)
: helper_(helper),
...... {
}TransferBuffer类的构造函数主要是将参数helper描述的一个GLES2CmdHelper对象保存在成员变量helper_中。
回到WebGraphicsContext3DCommandBufferImpl类的成员函数CreateContext中,创建了一个GLES2CmdHelper对象和一个TransferBuffer对象之后,接下来就可以创建一个GLES2Implementation对象,并且保存在成员变量real_gl_中了。这个GLES2Implementation对象的创建过程如下所示:
GLES2Implementation::GLES2Implementation(
GLES2CmdHelper* helper,
ShareGroup* share_group,
TransferBufferInterface* transfer_buffer,
bool bind_generates_resource,
bool lose_context_when_out_of_memory,
GpuControl* gpu_control)
: helper_(helper),
transfer_buffer_(transfer_buffer),
......,
gpu_control_(gpu_control),
...... {
......
share_group_ =
(share_group ? share_group : new ShareGroup(bind_generates_resource));
......
}GLES2Implementation类的构造函数分别把参数helper、transfer_buffer和gpu_control指向的GLES2CmdHelper对象、TransferBuffer对象和CommandBufferProxyImpl对象保存在成员变量helper_、transfer_buffer_和gpu_control_中。
当参数share_group的值不等于NULL的时候,它指向的是一个gpu::gles2::ShareGroup对象,这个gpu::gles2::ShareGroup对象会保存在GLES2Implementation类的成员变量share_group_中。在前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文中提到,这个gpu::gles2::ShareGroup对象描述的是一个资源共享组,位于这个资源共享组中的OpenGL上下文可以共享OpenGL资源,例如Buffer、纹理、FBO、RBO和Program等。
当参数share_group的值等于NULL时,表明当前正在初始化的OpenGL上下文目前不与其它OpenGL上下文位于同一个资源共享组中。这时候就需要创建一个新的资源共享组,并且保存在正在创建的GLES2Implementation对象的成员变量share_group_中。
回到WebGraphicsContext3DCommandBufferImpl类的成员函数CreateContext中,创建了一个GLES2Implementation对象之后,接下来就调用它的成员函数Initialize对其进行初始化,如下所示:
bool GLES2Implementation::Initialize(
unsigned int starting_transfer_buffer_size,
unsigned int min_transfer_buffer_size,
unsigned int max_transfer_buffer_size,
unsigned int mapped_memory_limit) {
......
if (!transfer_buffer_->Initialize(
starting_transfer_buffer_size,
kStartingOffset,
min_transfer_buffer_size,
max_transfer_buffer_size,
kAlignment,
kSizeToFlush)) {
return false;
}
mapped_memory_.reset(
new MappedMemoryManager(
helper_,
base::Bind(&GLES2Implementation::PollAsyncUploads,
// The mapped memory manager is owned by |this| here, and
// since its destroyed before before we destroy ourselves
// we don't need extra safety measures for this closure.
base::Unretained(this)),
mapped_memory_limit));
......
buffer_tracker_.reset(new BufferTracker(mapped_memory_.get()));
......
return true;
}GLES2Implementation类的成员函数Initialize首先是调用TransferBuffer类的成员函数Initialize对成员变量transfer_buffer_指向的一个TransferBuffer对象进行初始化,实际上就是为它分配一块可以与GPU进程共享的内存,用来将OpenGL命令附带的数据从WebGL端、Render端和Browser端传递到GPU进程中去。
此外,GLES2Implementation类的成员函数Initialize还会创建一个BufferTracker对象保存在成员变量buffer_tracker_中。前面提到,这个BufferTracker对象用来传输一些特殊GPU命令附带的资源数据,并且也可以用来实现异步纹理上传。BufferTracker对象像TransferBuffer对象一样,也是通过共享内存将数据传递给GPU进程。这些共享内存通过一个称为MappedMemoryManager的对象进行管理,也就是分配和释放。因此,GLES2Implementation类的成员函数Initialize在创建BufferTracker对象之前,首先创建一个MappedMemoryManager对象,并且保存在成员变量mapped_memory_中。
在接下来的一篇文章中分析Chromium的纹理上传机制时,我们再分析TransferBuffer类和BufferTracker类的实现。
现在我们将目光集中到GPU进程,分析它接收和处理WebGL端、Render端和Browser端发送过来的GPU命令涉及的类关系图,如图2所示:

图2 GPU进程接收和处理GPU命令过程涉及的类关系图
前面提到,WebGL端、Render端和Browser端是通过一个CommandBufferProxyImpl对象的成员函数Flush向GPU进程发送一个提交GPU命令的IPC消息。这个IPC消息由对应的一个GpuCommandBufferStub对象接收,并且分发给其成员函数OnAsyncFlush进行处理。
GpuCommandBufferStub类有一个成员变量command_buffer_,它指向的是一个CommandBufferService对象,GpuCommandBufferStub类的成员函数OnAsyncFlush调用其成员函数Flush处理接收到的提交GPU命令的IPC消息。CommandBufferService类是从CommandBufferBase类继承下来的,后者实现了CommandBuffer接口。
CommandBufferService类的成员函数Flush在处理提交GPU命令的IPC消息的过程中,又会调用GpuCommandBufferStub类的成员函数PutChanged告知相应的GpuCommandBufferStub对象,其对应的Client端有新的GPU命令需要处理。这时候GpuCommandBufferStub类的成员函数PutChanged调用成员变量scheduler_指向的一个GpuScheduler对象的成员函数PutChanged对新的GPU命令进行处理。
GpuScheduler类有一个成员变量parser_,它指向的是一个CommandParser对象,GpuScheduler类的成员函数PutChanged调用它的成员函数ProcessCommand对新的GPU命令进行处理。CommandParser类的成员函数ProcessCommand从GPU命令缓冲区逐个读出新提交的GPU命令,并且利用成员变量handler_指向的一个GLES2DecoderImpl对象对读出来的GPU命令进行解码,以及调用对应的OpenGL函数。GLES2DecoderImpl类继承了GLES2Decoder类,GLES2Decoder类又继承了CommonDecoder类,CommonDecoder类又实现了AsyncAPIInterface接口。
假设WebGL端、Render端和Browser端在GPU命令缓冲区写入了gles2::cmds::ActiveTexture和gles2::cmds::BindBuffer两个命令后,调用CommandBufferProxyImpl类的成员函数Flush向GPU进程发送一个IPC消息,以及GPU进程可以处理上述两个命令。CommandBufferProxyImpl类的成员函数Flush在向GPU进程发送IPC消息之前,会向GPU命令缓冲区写入一个gles2::cmds::Flush命令。也就是说,这时候GPU命令缓冲区有gles2::cmds::ActiveTexture、gles2::cmds::BindBuffer和gles2::cmds::Flush三个命令需要处理。GPU进程通过GLES2DecoderImpl类将上述三个命令解码出来之后,就会分别调用成员函数DoActiveTexture、DoBindBuffer和DoFlush进行处理。这三个成员函数又分别调用了OpenGL函数glActiveTexture、glBindBuffer和glFlush,从而处理完成Client端提交的GPU命令。
在结合源码详细分析上述GPU命令的执行过程之前,我们先分析GPU进程接收和处理GPU命令过程涉及到的GpuCommandBufferStub类、CommandBufferService类、GpuScheduler类、CommandParser类和GLES2DecoderImpl类的关系。
从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文可以知道,WebGL端、Render端和Browser端在创建OpenGL上下文的过程中,会向GPU进程发送一个类型为GpuCommandBufferMsg_Initialize的IPC消息。这个IPC消息由GpuCommandBufferStub类的成员函数OnInitialize进行处理,如下所示:
void GpuCommandBufferStub::OnInitialize(
base::SharedMemoryHandle shared_state_handle,
IPC::Message* reply_message) {
......
command_buffer_.reset(new gpu::CommandBufferService(
context_group_->transfer_buffer_manager()));
......
decoder_.reset(::gpu::gles2::GLES2Decoder::Create(context_group_.get()));
scheduler_.reset(new gpu::GpuScheduler(command_buffer_.get(),
decoder_.get(),
decoder_.get()));
......
decoder_->set_engine(scheduler_.get());
......
if (!decoder_->Initialize(surface_,
context,
!surface_id(),
initial_size_,
disallowed_features_,
requested_attribs_)) {
......
}
......
command_buffer_->SetPutOffsetChangeCallback(
base::Bind(&GpuCommandBufferStub::PutChanged, base::Unretained(this)));
command_buffer_->SetGetBufferChangeCallback(
base::Bind(&gpu::GpuScheduler::SetGetBuffer,
base::Unretained(scheduler_.get())));
......
} 这个函数定义在文件external/chromium_org/content/common/gpu/gpu_command_buffer_stub.cc中。
GpuCommandBufferStub类的成员变量context_group_指向的是一个gpu::gles2::ContextGroup对象。从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文可以知道,这个gpu::gles2::ContextGroup对象描述的是一个资源共享组,调用它的成员函数transfer_buffer_manager可以获得一个TransferBufferManager对象。有了这个TransferBufferManager对象之后,GpuCommandBufferStub类的成员函数OnInitialize就可以以它为参数创建一个CommandBufferService对象,并且保存在成员变量command_buffer_。
GpuCommandBufferStub类的成员函数OnInitialize在最后会调用上述创建的CommandBufferService对象的成员函数SetPutOffsetChangeCallback和SetGetBufferChangeCallback设置两个Callback对象到它里面去,如下所示:
void CommandBufferService::SetPutOffsetChangeCallback(
const base::Closure& callback) {
put_offset_change_callback_ = callback;
}
void CommandBufferService::SetGetBufferChangeCallback(
const GetBufferChangedCallback& callback) {
get_buffer_change_callback_ = callback;
}CommandBufferService类的成员函数SetPutOffsetChangeCallback和SetGetBufferChangeCallback分别把上述两个Callback对象保存在成员变量put_offset_change_callback_和get_buffer_change_callback_中。
结合前面的调用过程,我们就可以知道,CommandBufferService类的成员变量put_offset_change_callback_和get_buffer_change_callback_指向的Callback对象绑定的函数分别为GpuCommandBufferStub类的成员函数PutChanged和GpuScheduler类的成员函数SetGetBuffer。
回到GpuCommandBufferStub类的成员函数OnInitialize中,它创建了一个CommandBufferService对象之后,接下来调用GLES2Decoder类的静态成员函数Create创建了一个GLES2DecoderImpl对象,并且保存在成员变量decoder_中。
GLES2Decoder类的静态成员函数Create的实现如下所示:
GLES2Decoder* GLES2Decoder::Create(ContextGroup* group) {
return new GLES2DecoderImpl(group);
}从这里可以看到,GLES2Decoder类的静态成员函数Create返回的是一个GLES2DecoderImpl对象。
回到GpuCommandBufferStub类的成员函数OnInitialize中,它创建了一个GLES2DecoderImpl对象之后,接下来又创建了一个GpuScheduler对象,并且保存在成员变量scheduler_中。
GpuScheduler对象的创建过程,即GpuScheduler类的构造函数的实现,如下所示:
GpuScheduler::GpuScheduler(CommandBufferServiceBase* command_buffer,
AsyncAPIInterface* handler,
gles2::GLES2Decoder* decoder)
: command_buffer_(command_buffer),
handler_(handler),
decoder_(decoder),
...... {}GpuScheduler类的构造函数主要是将参数command_buffer指向的一个CommandBufferService对象保存在成员变量command_buffer_中,并且将参数handler和decoder指向的同一个GLES2DecoderImpl对象分别以不同的类型保存在成员变量handler_和decoder_中。
回到GpuCommandBufferStub类的成员函数OnInitialize中,它创建了一个GpuScheduler对象之后,接下来会将该GpuScheduler对象设置到前面创建的GLES2DecoderImpl对象中去,这是通过调用GLES2DecoderImpl类的成员函数set_engine实现的。
GLES2DecoderImpl类的成员函数set_engine是从父类CommonDecoder继承下来的,后者的实现如下所示:
class GPU_EXPORT CommonDecoder : NON_EXPORTED_BASE(public AsyncAPIInterface) {
public:
......
void set_engine(CommandBufferEngine* engine) {
engine_ = engine;
}
......
private:
......
CommandBufferEngine* engine_;
......
};CommonDecoder类的成员函数set_engine将参数engine指向的一个GpuScheduler对象保存在成员变量engine_中。
回到GpuCommandBufferStub类的成员函数OnInitialize中,它将成员变量scheduler_指向的GpuScheduler对象保存在成员变量decoder_指向的GLES2DecoderImpl对象的内部之后,接下来调用GLES2DecoderImpl类的成员函数Initialize对该GLES2DecoderImpl对象进行初始化。
GLES2DecoderImpl类的成员函数Initialize的实现如下所示:
bool GLES2DecoderImpl::Initialize(
const scoped_refptr& surface,
const scoped_refptr& context,
bool offscreen,
const gfx::Size& size,
const DisallowedFeatures& disallowed_features,
const std::vector& attribs) {
......
context_ = context;
surface_ = surface;
......
} GLES2DecoderImpl类的成员函数Initialize会将参数surface和context指向的GLSurface对象和GLContext对象分别保存在成员变量surface_和context_中。从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文可以知道,参数context指向的GLContext对象描述的是一个OpenGL上下文,而参数surface指向的GLSurface对象描述的是一个绘图表面。在接下来一篇文章中分析OpenGL上下文的调度过程时,我们就会看到这两个成员变量是如何使用的。
以上就是图2涉及到的各个类的关系。明白了它们的关系之后,回到前面分析的CommandBufferService类的成员函数SetGetBuffer中。前面提到,WebGL端、Render端和Browser端创建了一块可以与GPU进程共享的内存之后,会将该内存的ID发送给GPU进程,以便可以告诉GPU进程,这个ID描述的共享内存就是一个GPU命令缓冲区。CommandBufferService类的成员函数SetGetBuffer将这个GPU命令缓冲区的相关信息保存在内部之后,就会调用成员变量get_buffer_change_callback_指向的一个Callback对象的成员函数Run。
从前面的分析可以知道,CommandBufferService类的成员变量get_buffer_change_callback_指向的一个Callback对象绑定的函数为GpuScheduler类的成员函数SetGetBuffer,因此,当该Callback对象的成员函数Run被调用时,GpuScheduler类的成员函数SetGetBuffer也会被调用。
GpuScheduler类的成员函数SetGetBuffer的实现如下所示:
bool GpuScheduler::SetGetBuffer(int32 transfer_buffer_id) {
scoped_refptr ring_buffer =
command_buffer_->GetTransferBuffer(transfer_buffer_id);
......
if (!parser_.get()) {
parser_.reset(new CommandParser(handler_));
}
parser_->SetBuffer(
ring_buffer->memory(), ring_buffer->size(), 0, ring_buffer->size());
SetGetOffset(0);
return true;
} 参数transfer_buffer_id描述的就是GPU命令缓冲区的ID,GpuScheduler类的成员函数SetGetBuffer根据这个ID值调用成员变量command_buffer_指向的一个CommandBufferService对象的成员函数GetTransferBuffer就可以获得一个Buffer对象,通过该Buffer对象就可以获得当前正在处理的GpuScheduler对象所使用的GPU命令缓冲区的信息,例如它的内存地址和大小等信息。
从前面的分析可以知道,GpuScheduler类的成员变量handler_指向的是一个GLES2DecoderImpl对象,GpuScheduler类的成员函数SetGetBuffer以它为参数,创建了一个CommandParser对象,并且保存在成员变量parser_中。
CommandParser对象的创建过程,即CommandParser类的构造函数的实现,如下所示:
CommandParser::CommandParser(AsyncAPIInterface* handler)
: ......,
handler_(handler) {
}CommandParser类的构造函数主要是将参数handler指向的一个GLES2DecoderImpl对象保存在成员变量handler_中。
回到GpuScheduler类的成员函数SetGetBuffer,它创建了一个CommandParser对象之后,接下来将参数transfer_buffer_id描述的GPU命令缓冲区的地址和大小等信息设置给CommandParser对象,这是通过调用CommandParser类的成员函数SetBuffer实现的,如下所示:
void CommandParser::SetBuffer(
void* shm_address,
size_t shm_size,
ptrdiff_t offset,
size_t size) {
......
get_ = 0;
put_ = 0;
char* buffer_begin = static_cast(shm_address) + offset;
buffer_ = reinterpret_cast(buffer_begin);
entry_count_ = size / 4;
} 与前面分析的CommandBufferHelper类和CommandBufferService类一样,CommandParser类也将GPU命令缓冲区看作是一个CommandBufferEntry数组,并且将该CommandBufferEntry数组的地址和大小分别保存成员变量buffer_和entry_count_中。
此外,CommandParser类的成员函数SetBuffer还会将成员变量get_和put_的值设置为0。其中,成员变量get_表示下一次要处理的GPU命令在上述CommandBufferEntry数组的起始偏移位置,而成员变量put_表示最新提交的GPU命令在上述CommandBufferEntry数组的结束偏移位置。
接下来,我们结合源代码,以glBindBuffer和glFlush两个GPU命令为例,分析WebGL端、Render端和Browser端执行GPU命令的过程。
前面提到,WebGL端、Render端和Browser端是通过GLES2Implementation类提供的接口执行GPU命令的。GLES2Implementation类提供了成员函数BindBuffer和Flush来实现GPU命令glBindBuffer和glFlush。
在分析GPU命令glBindBuffer的实现之前,我们首先要分析另外一个GPU命令glGenBuffers的实现,因为GPU命令glBindBuffer的第二个参数指定的Buffer ID是由它分配的。GLES2Implementation类提供了成员函数GenBuffers来实现GPU命令glGenBuffers。
GLES2Implementation类的成员函数GenBuffers的实现如下所示:
void GLES2Implementation::GenBuffers(GLsizei n, GLuint* buffers) {
......
GetIdHandler(id_namespaces::kBuffers)->MakeIds(this, 0, n, buffers);
......
helper_->GenBuffersImmediate(n, buffers);
if (share_group_->bind_generates_resource())
helper_->CommandBufferHelper::Flush();
......
}这个函数定义在文件external/chromium_org/gpu/command_buffer/client/gles2_implementation_impl_autogen.h。
GLES2Implementation类的成员函数GenBuffers首先调用另外一个成员函数GetIdHandler获得一个类型为id_namespaces::kBuffers的资源ID分配器,如下所示:
IdHandlerInterface* GLES2Implementation::GetIdHandler(int namespace_id) const {
return share_group_->GetIdHandler(namespace_id);
}前面提到,GLES2Implementation类的成员变量share_group_指向的是一个gpu::gles2::ShareGroup对象,这个gpu::gles2::ShareGroup对象描述的是一个资源共享组,这里调用它的成员函数GetIdHandler获得一个类型为id_namespaces::kBuffers的资源ID分配器。如下所示:
class GLES2_IMPL_EXPORT ShareGroup
: public gpu::RefCountedThreadSafe {
public:
......
IdHandlerInterface* GetIdHandler(int namespace_id) const {
return id_handlers_[namespace_id].get();
}
......
private:
......
scoped_ptr id_handlers_[id_namespaces::kNumIdNamespaces];
......
}; gpu::gles2::ShareGroup类的成员函数GetIdHandler以参数namespace_id为索引,在成员变量id_handlers_描述的一个IdHandlerInterface数组中获得一个IdHandlerInterface接口返回给调用者,作为一个资源ID分配器使用。
gpu::gles2::ShareGroup类的成员变量id_handlers_描述的IdHandlerInterface数组是在构造函数中初始化的,如下所示:
ShareGroup::ShareGroup(bool bind_generates_resource)
: bind_generates_resource_(bind_generates_resource) {
if (bind_generates_resource) { {
for (int i = 0; i < id_namespaces::kNumIdNamespaces; ++i) {
if (i == id_namespaces::kProgramsAndShaders) {
id_handlers_[i].reset(new NonReusedIdHandler());
} else {
id_handlers_[i].reset(new IdHandler());
}
}
} else {
for ({nt i = 0; i < id_namespaces::kNumIdNamespaces; ++i) {
if (i == id_namespaces::kProgramsAndShaders) {
id_handlers_[i].reset(new NonReusedIdHandler());
} else {
id_handlers_[i].reset(new StrictIdHandler(i));
}
}
}
}
......
}这个函数定义在文件external/chromium_org/gpu/command_buffer/client/share_group.cc中。
gpu::gles2::ShareGroup类的构造函数主要就是为不同的资源分别创建一个ID分配器,用来负责生成资源ID。在分析gpu::gles2::ShareGroup类的构造函数的实现之前,我们首先分析一下资源ID的概念。
资源ID有Client端和Service端之分。Client端资源ID是给WebGL端、Render端和Browser端使用的,而Service端是给GPU进程使用的,它们是一一对应关系。例如,WebGL端、Render端和Browser端请求GPU进程执行glBindBuffer命令时,会指定一个Client端的Buffer ID。GPU进程在处理glBindBuffer命令时,会将它里面包含的Client端Buffer ID取出来,然后找到对应的Service端Buffer ID,最后以Service端Buffer ID为参数,调用真正的OpenGL函数glBindBuffer。
那么,Client端和Service端资源ID是如何一一对应起来的呢?以Buffer ID为例,WebGL端、Render端和Browser端通过调用GLES2Implementation类的成员函数GenBuffers生成Buffer ID的。GLES2Implementation类的成员函数GenBuffers在生成Buffer ID之后,会将生成的Buffer ID封装在一个gles2::cmds::GenBuffersImmediate命令中,并且写入到GPU命令缓冲区中去。GPU进程在处理这个gles2::cmds::GenBuffersImmediate命令的时候,首先是将里面的Buffer ID取出来,作为Client端资源ID,接下来调用真正的OpenGL函数glGenBuffersARB生成一个Buffer ID,作为Service端ID,并且与前面获得的Client端资源ID对应起来。
注意,对WebGL端、Render端和Browser端来说,它们只知道Client端资源ID,Service端资源ID对它们来说是完全透明的。因此,在WebGL端、Render端和Browser端,如果两个在同一个资源共享组中的OpenGL上下文需要共享一个OpenGL资源,它们只需要使用同一个Client端ID即可。
回到gpu::gles2::ShareGroup类的构造函数中,它将参数bind_generates_resource的值保存在其成员变量bind_generates_resoure_中。
当一个gpu::gles2::ShareGroup对象的成员变量bind_generates_resource_的值等于true时,表示GPU进程为位于该gpu::gles2::ShareGroup对象描述的资源共享组中的WebGL端、Render端或者Browser端执行gles2::cmds::glBindXXX类命令时,第二个参数指定的对象名,也就是一个资源ID,不必是之前通过gles2::cmds::glGenXXX命令生成的。如果不是通过gles2::cmds::glGenXXX命令生成的,那么GPU进程在执行gles2::cmds::glBindXXX类命令时会自动模拟gles2::cmds::glGenXXX命令生成。
考虑一个情景。两个WebGL端OpenGL上下文位于同一个资源共享组中,并且描述该资源共享组的gpu::gles2::ShareGroup对象的成员变量bind_generates_resource_的值等于true。其中第一个OpenGL上下文调用GLES2Implementation类的成员函数GenBuffers生成了一个Buffer ID,然后将该Buffer ID交给第二个OpenGL上下文。第二个OpenGL上下文调用GLES2Implementation类的成员函数BindBuffer使用该Buffer ID。
假设第二个OpenGL上下文先将GPU命令缓冲区提父给GPU进程处理,那么GPU进程在处理该GPU命令缓冲区中的gles2::cmds::BindBuffer命令时,就会发现它指定的Buffer ID不是通过gles2::cmds::GenBuffersImmediate命令生成的,于是就会模拟gles2::cmds::GenBuffersImmediate命令生成。这样会造成GPU进程处理第一个OpenGL上下文的GPU命令缓冲区中的gles2::cmds::GenBuffersImmediate命令时会出错,因为它指定的Buffer ID之前在处理第二个OpenGL上下文的GPU命令缓冲区时已经生成过了。
为了解决上述问题,一个OpenGL上下文在调用GLES2Implementation类的成员函数GenBuffers生成Buffer ID之后,就会马上请求GPU进程生成对应的Service端Buffer ID,使得在同一个资源共享组中的其它共享的OpenGL上下文可以马上使用该Buffer ID。
另一方面,当一个gpu::gles2::ShareGroup对象的成员变量bind_generates_resource_的值等于false时,表示GPU进程为位于该gpu::gles2::ShareGroup对象描述的资源共享组中的WebGL端、Render端或者Browser端执行gles2::cmds::glBindXXX类命令时,第二个参数指定的资源ID,必须要事先通过gles2::cmds::glGenXXX命令生成,否则的话,就会报错。
我们看到,在gpu::gles2::ShareGroup类的构造函数中,当参数bind_generates_resoure等于true时,除了类型为id_namespaces::kProgramsAndShaders的资源ID,其作资源ID都是通过IdHandler类生成的,而当参数bind_generates_resource等于false时,除了类型为id_namespaces::kProgramsAndShaders的资源ID,其作资源ID都是通过StrictIdHandler类生成的。IdHandler类与StrictIdHandler类都实现了IdHandlerInterface接口,不过前者在生成Client端资源ID时,会马上请求GPU进程生成对应的Service端资源ID,这样就可以解决上面提到的处理gles2::cmds::GenBuffersImmediate命令时的出错问题。
从前面的分析可以知道,一个新的gpu::gles2::ShareGroup对象是在GLES2Implementation类的构造函数创建的。GLES2Implementation类的构造函数在创建新的gpu::gles2::ShareGroup对象的时候,使用的参数bind_generates_resoure是从WebGraphicsContext3DCommandBufferImpl类的成员函数CreateContext传递进来的,它的值被指定为false。这意味着前面分析的GLES2Implementation类的成员函数GenBuffers调用成员函数GetIdHandler获得的是一个StrictIdHandler对象,接下来它调用该StrictIdHandler对象的成员函数MakeIds生成一个Buffer ID,如下所示:
class StrictIdHandler : public IdHandlerInterface {
public:
......
virtual void MakeIds(GLES2Implementation* gl_impl,
GLuint /* id_offset */,
GLsizei n,
GLuint* ids) OVERRIDE {
base::AutoLock auto_lock(lock_);
// Collect pending FreeIds from other flush_generation.
CollectPendingFreeIds(gl_impl);
for (GLsizei ii = 0; ii < n; ++ii) {
if (!free_ids_.empty()) {
// Allocate a previously freed Id.
ids[ii] = free_ids_.top();
free_ids_.pop();
// Record kIdInUse state.
DCHECK(id_states_[ids[ii] - 1] == kIdFree);
id_states_[ids[ii] - 1] = kIdInUse;
} else {
// Allocate a new Id.
id_states_.push_back(kIdInUse);
ids[ii] = id_states_.size();
}
}
}
private:
......
base::Lock lock_;
std::vector id_states_;
std::stack free_ids_;
}; StrictIdHandler类的成员函数MakeIds首先调用成员函数CollectPendingFreeIds回收参数gl_impl描述的OpenGL上下文已经不再使用的资源ID。这些回收的资源ID保存在成员变量free_ids_ 描述的一个std::stack中。
StrictIdHandler类的成员函数MakeIds接下来首先检查成员变量free_ids_ 描述的一个std::stack是否为空。如果不为空,那么就复用里面的资源ID。否则的话,再通过成员变量id_states_描述的一个std::vector生成新的资源ID。
回到GLES2Implementation类的成员函数GenBuffers中,它生成了Client端资源ID之后,接下来调用成员变量helper_指向的一个GLES2CmdHelper对象的成员函数GenBuffersImmediate往GPU命令缓冲区写入一个gpu::gles2::GenBuffersImmediate命令,最后检查成员变量share_group_描述的一个gpu::gles2::ShareGroup对象的成员变量bind_generates_resource_的值是否等于true。如果等于true,如前所述,那么就需要马上向GPU进程提交前面写入的gpu::gles2::GenBuffersImmediate命令,以便GPU进程可以为前面分配的Client端资源ID生成对应的Service端资源ID。我们假设成员变量share_group_描述的gpu::gles2::ShareGroup对象的成员变量bind_generates_resource_的值等于false,这时候前面写入的gpu::gles2::GenBuffersImmediate命令就会在以后再提交给GPU进程处理。
接下来,我们继续分析GLES2CmdHelper类的成员函数GenBuffersImmediate的实现,以便可以了解往GPU命令缓冲区写入一个gpu::gles2::GenBuffersImmediate命令的过程。
GLES2CmdHelper类的成员函数GenBuffersImmediate实现在external/chromium_org/gpu/command_buffer/client/gles2_cmd_helper_autogen.h中,这个文件被直接include在GLES2CmdHelper类定义内部,如下所示:
class GPU_EXPORT GLES2CmdHelper : public CommandBufferHelper {
public:
......
// Include the auto-generated part of this class. We split this because it
// means we can easily edit the non-auto generated parts right here in this
// file instead of having to edit some template or the code generator.
#include "gpu/command_buffer/client/gles2_cmd_helper_autogen.h"
......
};因此,我们直接从external/chromium_org/gpu/command_buffer/client/gles2_cmd_helper_autogen.h文件中找到GLES2CmdHelper类的成员函数GenBuffersImmediate的实现,如下所示:
void GenBuffersImmediate(GLsizei n, GLuint* buffers) {
const uint32_t size = gles2::cmds::GenBuffersImmediate::ComputeSize(n);
gles2::cmds::GenBuffersImmediate* c =
GetImmediateCmdSpaceTotalSize(size);
if (c) {
c->Init(n, buffers);
}
} struct GenBuffersImmediate {
typedef GenBuffersImmediate ValueType;
......
static uint32_t ComputeDataSize(GLsizei n) {
return static_cast(sizeof(GLuint) * n); // NOLINT
}
static uint32_t ComputeSize(GLsizei n) {
return static_cast(sizeof(ValueType) +
ComputeDataSize(n)); // NOLINT
}
......
gpu::CommandHeader header;
int32_t n;
}; 从这里可以看到,一个gles2::cmds::GenBuffersImmediate命令由三部分组成:
1. 一个CommandHeader头。前面提到,一个CommandHeader头为4个字节,其中前21位表示GPU命令的长度,后11位表示GPU命令的类型。
2. 参数n,表示后面携带的Buffer ID的个数,每一个Buffer ID用一个GLuint描述。
3. 一组Buffer ID,长度为sizeof(GLuint) * n。
回到GLES2CmdHelper类的成员函数GenBuffersImmediate中,计算好gles2::cmds::GenBuffersImmediate命令的长度后,它接着调用另外一个成员函数GetImmediateCmdSpaceTotalSize从GPU命令缓冲区分配空间,如下所示:
GLES2CmdHelper类的成员函数GetImmediateCmdSpaceTotalSize是从父类CommandBufferHelper继承下来的,它的实现如下所示:
class GPU_EXPORT CommandBufferHelper {
public:
......
// Typed version of GetSpace for immediate commands.
template
T* GetImmediateCmdSpaceTotalSize(size_t total_space) {
......
int32 space_needed = ComputeNumEntries(total_space);
T* data = static_cast(GetSpace(space_needed));
......
return data;
}
......
}; 前面提到,GPU命令缓冲区是一个CommandBufferEntry数组。也就是说,GPU命令缓冲区是以CommandBufferEntry为单位进行分配的。因此,CommandBufferHelper类的成员函数GetImmediateCmdSpaceTotalSize首先调用一个全局函数ComputeNumEntries计算参数total_space描述的空间占用多少个CommandBufferEntry。
函数ComputeNumEntries的实现如下所示:
// Computes the number of command buffer entries needed for a certain size. In
// other words it rounds up to a multiple of entries.
inline uint32_t ComputeNumEntries(size_t size_in_bytes) {
return static_cast(
(size_in_bytes + sizeof(uint32_t) - 1) / sizeof(uint32_t)); // NOLINT
} 从前面的分析可以知道,一个CommandBufferEntry就是一个uint32_t,因此函数ComputeNumEntries将参数size_in_bytes对齐到sizeof(uint32_t)个字节后,再除以sizeof(uint32_t),就可以得到长度size_in_bytes的空间占用的CommandBufferEntry个数。
回到CommandBufferHelper类的成员函数GetImmediateCmdSpaceTotalSize中,获得了gles2::cmds::GenBuffersImmediate命令占用的CommandBufferEntry个数之后, 再调用成员函数GetSpace从GPU命令缓冲区中分配空间。分配得到的空间最终转化为一个gles2::cmds::GenBuffersImmediate结构体返回给调用者。
CommandBufferHelper类的成员函数GetSpace的实现如下所示:
class GPU_EXPORT CommandBufferHelper {
public:
......
void* GetSpace(int32 entries) {
#if defined(CMD_HELPER_PERIODIC_FLUSH_CHECK)
// Allow this command buffer to be pre-empted by another if a "reasonable"
// amount of work has been done. On highend machines, this reduces the
// latency of GPU commands. However, on Android, this can cause the
// kernel to thrash between generating GPU commands and executing them.
++commands_issued_;
if (flush_automatically_ &&
(commands_issued_ % kCommandsPerFlushCheck == 0)) {
PeriodicFlushCheck();
}
#endif
// Test for immediate entries.
if (entries > immediate_entry_count_) {
WaitForAvailableEntries(entries);
if (entries > immediate_entry_count_)
return NULL;
}
DCHECK_LE(entries, immediate_entry_count_);
// Allocate space and advance put_.
CommandBufferEntry* space = &entries_[put_];
put_ += entries;
immediate_entry_count_ -= entries;
DCHECK_LE(put_, total_entry_count_);
return space;
}
......
}前面提到,CommandBufferHelper类的成员变量entry_指向的是一个CommandBufferEntry数组,这个CommandBufferEntry数组描述的即为GPU命令缓冲区。CommandBufferHelper类的成员变量put_描述的是下一个写入的GPU命令在CommandBufferEntry数组中的起始位置。因此,CommandBufferHelper类的成员函数GetSpace将entry_[put_]的地址作为要分配的空间的起始地址。将空间分配出去后,要调用成员变量put_的值,即将它的值加上参数entries的值,其中,参数entries描述的是要分配的空间占用的CommandBufferEntry个数。
CommandBufferHelper类的成员变量immediate_entry_count_描述的是空闲的GPU命令缓冲中可以连续分配的CommandBufferEntry的个数。这里之所以强调是连续分配,是因为空闲的GPU命令缓冲区可能不是连续的。GPU命令缓冲区是一个Ring Buffer,也就是一个循环使用的Buffer。空闲的区间可能有一部分在缓冲区的末部,另一部在缓冲区的首部。这两部分空闲缓冲区不是连续的。
如果接下来不连续的空闲缓冲区大小不满足请求分配的空间的大小,即成员变量immediate_entry_count_的值小于或者等于参数entries的值,那么CommandBufferHelper类的成员函数GetSpace会调用成员函数WaitForAvailableEntries请求GPU进程处理GPU命令缓冲区的命令,以便腾出更多的连续空闲空间出来。
另一方面,如果定义了宏CMD_HELPER_PERIODIC_FLUSH_CHECK,并且CommandBufferHelper类的成员变量flush_automatically_还会周期性地检查是否需要提交GPU命令给GPU进程处理。检查的频率为每写入kCommandsPerFlushCheck(100)个GPU命令一次。如果需要检查,那么就调用CommandBufferHelper类的成员函数PeriodicFlushCheck进行。
接下来,我们继续分析CommandBufferHelper类的成员函数PeriodicFlushCheck和WaitForAvailableEntries的实现,以便了解WebGL端、Render端和Browser端向GPU进程提交GPU命令的过程。
CommandBufferHelper类的成员函数PeriodicFlushCheck的实现如下所示:
void CommandBufferHelper::PeriodicFlushCheck() {
clock_t current_time = clock();
if (current_time - last_flush_time_ > kPeriodicFlushDelay * CLOCKS_PER_SEC)
Flush();
}CommandBufferHelper类的成员函数PeriodicFlushCheck会检查当前时间和上次提交GPU命令的时间的差值。如果这个差值大于kPeriodicFlushDelay * CLOCKS_PER_SEC(大概3.3ms),那么就会调用成员函数Flush向GPU进程提交GPU命令。后面分析WebGL端、Render端和Browser端请求GPU进程执行glFlush命令时,我们再分析CommandBufferHelper类的成员函数Flush的实现。
CommandBufferHelper类的成员函数WaitForAvailableEntries的实现如下所示:
void CommandBufferHelper::WaitForAvailableEntries(int32 count) {
......
if (put_ + count > total_entry_count_) {
......
int32 curr_get = get_offset();
if (curr_get > put_ || curr_get == 0) {
......
Flush();
if (!WaitForGetOffsetInRange(1, put_))
return;
curr_get = get_offset();
......
}
// Insert Noops to fill out the buffer.
int32 num_entries = total_entry_count_ - put_;
while (num_entries > 0) {
int32 num_to_skip = std::min(CommandHeader::kMaxSize, num_entries);
cmd::Noop::Set(&entries_[put_], num_to_skip);
put_ += num_to_skip;
num_entries -= num_to_skip;
}
put_ = 0;
}
CalcImmediateEntries(count);
if (immediate_entry_count_ < count) {
// Try again with a shallow Flush().
Flush();
CalcImmediateEntries(count);
if (immediate_entry_count_ < count) {
......
if (!WaitForGetOffsetInRange(put_ + count + 1, put_))
return;
CalcImmediateEntries(count);
......
}
}
}CommandBufferHelper类的成员变量total_entry_count_表示GPU命令缓冲区的大小,另外一个成员变量put_表示下一次要写入到GPU命令缓冲区的GPU命令的起始位置,本地变量curr_get表示未处理的GPU命令的起始位置,参数count表示需要分配的空间大小,它们的关系描述GPU命令缓冲区的使用情况,如图3所示:

图3 GPU命令缓冲区使用情况
如果CommandBufferHelper类的成员变量immediate_entry_count_的值小于等于参数count的值,那么GPU命令缓冲区的使用情况就如D和E所示,这时候CommandBufferHelper类的成员函数WaitForAvailableEntries什么也不用做。
其余分A、B和C三种情况讨论:
A. curr_get > put_,并且put_ + count > total_entry_count_。这时候[put_, curr_get)是空闲的,但它的大小小于count,不满足分配条件。这时候需要请求GPU进程从curr_get开始处理GPU命令,直到形成B所示的情形。
B. put_ > curr_get,并且put_ + count > total_entry_count_。这时候[put_, total_entry_count_)和[0, curr_get)是空闲的,但是[put_, total_entry_count_)的大小小于count,不满足分配条件。这时候需要将[put_, total_entry_count_)区间置空,以便将put_向前推进,返回到GPU命令缓冲区的前半部分,如C和D所示。如果如D所示,则结束。
C. curr_get > put_,并且put_ + count > curr_get。这时候[put_, curr_get)是空闲的,但它的大小小于count,不满足分配条件。这时候需要继续请求GPU进程从curr_get开始处理GPU命令,直到形成D所示的情形。
CommandBufferHelper类的成员函数WaitForAvailableEntries的实现就如上面描述的逻辑进行的。不过有一点需要注意的是,CommandBufferHelper类的成员函数WaitForAvailableEntries每次调用成员函数Flush请求GPU进程处理GPU命令缓冲区中的GPU命令时,都需要调用另外一个成员函数WaitForGetOffsetInRange进行等待,直到curr_get的值达到指定的范围。
接下来我们就继续分析CommandBufferHelper类的成员函数WaitForGetOffsetInRange的实现,如下所示:
bool CommandBufferHelper::WaitForGetOffsetInRange(int32 start, int32 end) {
......
command_buffer_->WaitForGetOffsetInRange(start, end);
return command_buffer_->GetLastError() == gpu::error::kNoError;
}CommandBufferHelper类的成员函数WaitForGetOffsetInRange调用成员变量command_buffer_指向的一个CommandBufferProxyImpl对象的成员函数WaitForGetOffsetInRange等待GPU进程处理GPU命令缓冲区中新提交的GPU命令,直到下一个未处理GPU命令在GPU命令缓冲区中的位置介于[start, end]之间。注意,start的值可以大于end的值,这时候要求下一个未处理GPU命令在GPU命令缓冲区中的位置大于等于start或者小于等于end。
CommandBufferProxyImpl类的成员函数WaitForGetOffsetInRange的实现如下所示:
void CommandBufferProxyImpl::WaitForGetOffsetInRange(int32 start, int32 end) {
......
TryUpdateState();
if (!InRange(start, end, last_state_.get_offset) &&
last_state_.error == gpu::error::kNoError) {
gpu::CommandBuffer::State state;
if (Send(new GpuCommandBufferMsg_WaitForGetOffsetInRange(
route_id_, start, end, &state)))
OnUpdateState(state);
}
......
}CommandBufferProxyImpl类的成员函数WaitForGetOffsetInRange首先调用另外一个函数TryUpdateState检查GPU进程已经处理到的GPU命令缓冲区位置。这个位置保存在成员变量last_state_描述的一个State对象的成员变量get_offset_中。如果这个位置不是位于参数start和end指定的范围,那么就向GPU进程发送一个类型为GpuCommandBufferMsg_WaitForGetOffsetInRange的IPC消息。这个IPC消息是一个同步类型的消息。
类型为GpuCommandBufferMsg_WaitForGetOffsetInRange的IPC消息是由与当前正处理的CommandBufferProxyImpl对象对应的一个GpuCommandBufferStub对象的成员函数OnMessageReceived接收的,如下所示:
bool GpuCommandBufferStub::OnMessageReceived(const IPC::Message& message) {
......
bool handled = true;
IPC_BEGIN_MESSAGE_MAP(GpuCommandBufferStub, message)
......
IPC_MESSAGE_HANDLER_DELAY_REPLY(GpuCommandBufferMsg_WaitForGetOffsetInRange,
OnWaitForGetOffsetInRange);
......
IPC_MESSAGE_UNHANDLED(handled = false)
IPC_END_MESSAGE_MAP()
CheckCompleteWaits();
......
return handled;
}从这里可以看到,GpuCommandBufferStub类的成员函数OnMessageReceived将类型为GpuCommandBufferMsg_WaitForGetOffsetInRange的IPC消息分发给成员函数OnWaitForGetOffsetInRange处理。
GpuCommandBufferStub类的成员函数OnWaitForGetOffsetInRange的实现如下所示:
void GpuCommandBufferStub::OnWaitForGetOffsetInRange(
int32 start,
int32 end,
IPC::Message* reply_message) {
......
wait_for_get_offset_ =
make_scoped_ptr(new WaitForCommandState(start, end, reply_message));
CheckCompleteWaits();
}GpuCommandBufferStub类的成员函数OnWaitForGetOffsetInRange首先将参数start、end和reply_message封装在一个WaitForCommandState对象中,并且将该WaitForCommandState对象保存在成员变量wait_for_get_offset_中,接着调用另外一个成员函数CheckCompleteWaits检查GPU进程是否已经处理了GPU命令缓冲区中的命令,并且处理的位置介于start和end之间。
GpuCommandBufferStub类的成员函数CheckCompleteWaits的实现如下所示:
void GpuCommandBufferStub::CheckCompleteWaits() {
if (wait_for_token_ || wait_for_get_offset_) {
gpu::CommandBuffer::State state = command_buffer_->GetLastState();
......
if (wait_for_get_offset_ &&
(gpu::CommandBuffer::InRange(wait_for_get_offset_->start,
wait_for_get_offset_->end,
state.get_offset) ||
state.error != gpu::error::kNoError)) {
ReportState();
GpuCommandBufferMsg_WaitForGetOffsetInRange::WriteReplyParams(
wait_for_get_offset_->reply.get(), state);
Send(wait_for_get_offset_->reply.release());
wait_for_get_offset_.reset();
}
}
}这个函数定义在文件external/chromium_org/content/common/gpu/gpu_command_buffer_stub.cc中。
当GpuCommandBufferStub类的成员变量wait_for_token_或者wait_for_get_offset_的值不等于NULL时,GpuCommandBufferStub类的成员函数CheckCompleteWaits会检查当前GPU命令缓冲区的状态,并且作相应的处理。如上所述,GpuCommandBufferStub类的成员变量wait_for_get_offset_指向的是一个WaitForCommandState对象,表示Client端正在等待GPU命令缓冲区被处理到一定范围。当GpuCommandBufferStub类的成员变量wait_for_token_不等于NULL时,它指向的是另一个WaitForCommandState对象,表示Client端处理在GPU命令缓冲区中插入的一个Token。关于GPU命令缓冲区的Token机制,我们在接下来一篇文章中再分析。
对于GpuCommandBufferStub类的成员变量wait_for_get_offset_的值不等于NULL的情况,GpuCommandBufferStub类的CheckCompleteWaits主要是检查GPU命令缓冲区被处理的当前处理位置是否位于它指向的WaitForCommandState对象描述的范围。如果是的话,那么就会回复之前接收到的类型为GpuCommandBufferMsg_WaitForGetOffsetInRange的IPC消息,以便Client端可以结束等待。
回忆前面分析的Client端,它在向GPU进程发送类型为GpuCommandBufferMsg_WaitForGetOffsetInRange的IPC消息之前,已经向GPU进程发出了一个处理GPU命令缓冲区中新提供的GPU命令的请求,因此,这时候GPU命令缓冲区新提供的GPU已经被处理,使得GPU命令缓冲区当被处理的位置满足指定的范围。
此外,我们还看到,每一次GpuCommandBufferStub类的成员函数OnMessageReceived被调用时,也就是每次当前正在处理的GpuCommandBufferStub对象接收到Client端发送过来的IPC消息时,都会调用GpuCommandBufferStub类的成员函数CheckCompleteWaits检查GPU命令缓冲区的状态。这样如果有Client端正在等待GPU命令缓冲区被处理到一定范围,并且GPU命令缓冲区当前被处理的位置能满足这个范围,那么该Client端也能结束等待。
回到前面分析的CommandBufferProxyImpl类的成员函数WaitForGetOffsetInRange中,当它发送给GPU进程的类型为GpuCommandBufferMsg_WaitForGetOffsetInRange的IPC消息被回复时,当前线程就结束等待,并且返回到 CommandBufferHelper类的成员函数WaitForAvailableEntries中,然后就可以从GPU命令缓冲区中获得一块满足要求的空间。这块空间返回到GLES2CmdHelper类的成员函数GenBuffersImmediate中之后,被当作一个gles2::cmds::GenBuffersImmediate结构体。最后该gles2::cmds::GenBuffersImmediate结构体的成员函数Init被调用,以便可以往前面从GPU命令缓冲区中获得的空间写入一个gles2::cmds::GenBuffersImmediate命令。
gles2::cmds::GenBuffersImmediate类的成员函数Init的实现如下所示:
struct GenBuffersImmediate {
......
static const CommandId kCmdId = kGenBuffersImmediate;
......
void SetHeader(GLsizei n) {
header.SetCmdByTotalSize(ComputeSize(n));
}
void Init(GLsizei _n, GLuint* _buffers) {
SetHeader(_n);
n = _n;
memcpy(ImmediateDataAddress(this), _buffers, ComputeDataSize(_n));
}
......
gpu::CommandHeader header;
int32_t n;
}; gles2::cmds::GenBuffersImmediate类的成员函数Init首先是调用成员函数SetHeader写入成员变量header描述的GPU命令头部,接着将参数n和buffers的值写入到GPU命令头部的末尾,也就是将生成的Buffer ID个数以及Buffer ID列表写入到GPU命令头部的末尾。
GPU命令头部是通过调用CommandHeader类的成员函数SetCmdByTotalSize写入的,如下所示:
struct CommandHeader {
uint32_t size:21;
uint32_t command:11;
......
void Init(uint32_t _command, int32_t _size) {
......
command = _command;
size = _size;
}
......
template
void SetCmdByTotalSize(uint32_t size_in_bytes) {
......
Init(T::kCmdId, ComputeNumEntries(size_in_bytes));
}
}; 从这里可以看到,CommandHeader类的成员函数SetCmdByTotalSize将描述当前正在处理的GPU头部的一个uint32_t的前21位设置为前面写入的gles2::cmds::GenBuffersImmediate命令附带的参数的长度,并且将该uint32_t的后11位的值设置为GenBuffersImmediate::kCmdId,即kGenBuffersImmediate,表示这是一个gles2::cmds::GenBuffersImmediate命令。
这一步执行完成之后,Client端就完成往GPU命令缓冲区写入一个gles2::cmds::GenBuffersImmediate命令的操作了。接下来我们继续分析往GPU命令缓冲区写入一个gles2::cmds::BindBuffer的操作,这是通过调用GLES2Implementation类的成员函数BindBuffer实现的,如下所示:
void GLES2Implementation::BindBuffer(GLenum target, GLuint buffer) {
......
if (BindBufferHelper(target, buffer)) {
helper_->BindBuffer(target, buffer);
}
......
}GLES2Implementation类的成员函数BindBuffer首先调用另外一个成员函数BindBufferHelper记录当前绑定的Buffer的ID,如下所示:
bool GLES2Implementation::BindBufferHelper(
GLenum target, GLuint buffer_id) {
......
bool changed = false;
switch (target) {
case GL_ARRAY_BUFFER:
if (bound_array_buffer_id_ != buffer_id) {
bound_array_buffer_id_ = buffer_id;
changed = true;
}
break;
case GL_ELEMENT_ARRAY_BUFFER:
changed = vertex_array_object_manager_->BindElementArray(buffer_id);
break;
case GL_PIXEL_PACK_TRANSFER_BUFFER_CHROMIUM:
bound_pixel_pack_transfer_buffer_id_ = buffer_id;
break;
case GL_PIXEL_UNPACK_TRANSFER_BUFFER_CHROMIUM:
bound_pixel_unpack_transfer_buffer_id_ = buffer_id;
break;
default:
changed = true;
break;
}
......
return changed;
}从这里可以看到,GLES2Implementation类的成员函数BindBufferHelper根据不同的绑定目标将被绑定的Buffer ID记录在不同的成员变量中。
回到GLES2Implementation类的成员函数BindBuffer中,它接下来调用成员变量helper_描述的一个GLES2CmdHelper对象的成员函数BindBuffer往GPU命令缓冲区写入一个gles2:::cmds::BindBuffer命令。
GLES2CmdHelper类的成员函数BindBuffer是从父类CommandBufferHelper继承下来的,它的实现如下所示:
void BindBuffer(GLenum target, GLuint buffer) {
gles2::cmds::BindBuffer* c = GetCmdSpace();
if (c) {
c->Init(target, buffer);
}
} CommandBufferHelper类的成员函数BindBuffer与前面分析的成员函数GenBuffersImmediate是类似的,它首先调用另外一个成员函数GetCmdSpace从GPU命令缓冲区获得一块空闲的内存,接着将该内存块封装成一个gles2::cmds::BindBuffer结构体,最后调用该gles2::cmds::BindBuffer结构体的成员函数Init往前面获得的内存块写入一个gles2:::cmds::BindBuffer命令。
最后,我们分析Client端向GPU进程提交GPU命令的过程,这是通过调用GLESImplementation类的成员函数Flush实现的,如下所示:
void GLES2Implementation::Flush() {
......
// Insert the cmd to call glFlush
helper_->Flush();
// Flush our command buffer
// (tell the service to execute up to the flush cmd.)
helper_->CommandBufferHelper::Flush();
}GLESImplementation类的成员函数Flush首先是调用成员变量helper_描述的一个GLES2CmdHelper对象的成员函数Flush往GPU命令缓冲区写入一个gles2:::cmds::Flush命令,接着再调用该GLES2CmdHelper对象的父类CommandBufferHelper的成员函数Flush请求GPU进程处理前面新写入到GPU命令缓冲区中的命令。
GLES2CmdHelper类的成员函数Flush是从父类CommandBufferHelper继承下来的,它的实现如下所示:
void Flush() {
gles2::cmds::Flush* c = GetCmdSpace();
if (c) {
c->Init();
}
} CommandBufferHelper类的成员函数Flush与前面分析的成员函数GenBuffersImmediate和BindBuffer是类似的,它首先调用另外一个成员函数GetCmdSpace从GPU命令缓冲区获得一块空闲的内存,接着将该内存块封装成一个gles2::cmds::Flush结构体,最后调用该gles2::cmds::Flush结构体的成员函数Init往前面获得的内存块写入一个gles2:::cmds::Flush命令。
CommandBufferHelper的成员函数Flush的实现如下所示:
void CommandBufferHelper::Flush() {
......
if (usable() && last_put_sent_ != put_) {
......
last_put_sent_ = put_;
command_buffer_->Flush(put_);
......
}
}CommandBufferHelper的成员函数Flush首先检查上次请求GPU进程执行GPU命令以来,GPU命令缓冲区的写入位置是否发生变化。如果发生变化,那么就说明GPU命令缓冲区又有新写入的还没有提供的GPU命令,这时候就会调用成员变量command_buffer_描述的一个CommandBufferProxyImpl对象的成员函数Flush请求GPU进程执行新写入到GPU命令缓冲区中的GPU命令。
CommandBufferProxyImpl类的成员函数Flush的实现如下所示:
void CommandBufferProxyImpl::Flush(int32 put_offset) {
......
last_put_offset_ = put_offset;
Send(new GpuCommandBufferMsg_AsyncFlush(route_id_,
put_offset,
++flush_count_));
}参数put_offset描述的是GPU命令缓冲区的最新写入位置,也就是最后写入的GPU命令的位置,CommandBufferProxyImpl类的成员函数Flush首先将它的值保存在成员变量last_put_offset_中,接着再向GPU进程发送一个类型为GpuCommandBufferMsg_AsyncFlush的IPC消息。
类型为GpuCommandBufferMsg_AsyncFlush的IPC消息是由与当前正处理的CommandBufferProxyImpl对象对应的一个GpuCommandBufferStub对象的成员函数OnMessageReceived接收的,如下所示:
bool GpuCommandBufferStub::OnMessageReceived(const IPC::Message& message) {
......
bool handled = true;
IPC_BEGIN_MESSAGE_MAP(GpuCommandBufferStub, message)
......
IPC_MESSAGE_HANDLER(GpuCommandBufferMsg_AsyncFlush, OnAsyncFlush);
......
IPC_MESSAGE_UNHANDLED(handled = false)
IPC_END_MESSAGE_MAP()
......
return handled;
}从这里可以看到,GpuCommandBufferStub类的成员函数OnMessageReceived将类型为GpuCommandBufferMsg_AsyncFlush的IPC消息分发给成员函数OnAsyncFlush处理。
GpuCommandBufferStub类的成员函数OnAsyncFlush的实现如下所示:void GpuCommandBufferStub::OnAsyncFlush(int32 put_offset, uint32 flush_count) {
......
if (flush_count - last_flush_count_ < 0x8000000U) {
last_flush_count_ = flush_count;
command_buffer_->Flush(put_offset);
} else {
// We received this message out-of-order. This should not happen but is here
// to catch regressions. Ignore the message.
NOTREACHED() << "Received a Flush message out-of-order";
}
......
}参数put_offset表示GPU命令缓冲区当前最新写入位置。另外一个参数flush_count表示Client端提交GPU命令的次数。这个次数必须是递增的,GpuCommandBufferStub类的成员函数OnAsyncFlush才会调用成员变量command_buffer_指向的一个CommandBufferService对象的成员函数Flush处理GPU命令缓冲区新提交的命令。否则的话,就什么也不做。
CommandBufferService类的成员函数Flush的实现如下所示:
void CommandBufferService::Flush(int32 put_offset) {
......
put_offset_ = put_offset;
if (!put_offset_change_callback_.is_null())
put_offset_change_callback_.Run();
} CommandBufferService类的成员函数Flush首先将GPU命令缓冲区当前最新写入位置记录在成员变量put_offset_中,接着检查成员变量put_offset_change_callback_的值。如果成员变量put_offset_change_callback_的值不等于NULL,那么就调用它指向的一个Callback对象的成员函数Run。
前面提到,CommandBufferService类的成员变量put_offset_change_callback_指向的Callback对象绑定的函数为GpuCommandBufferStub类的成员函数PutChanged,因此接下来我们继续分析GpuCommandBufferStub类的成员函数PutChanged的实现,如下所示:
void GpuCommandBufferStub::PutChanged() {
......
scheduler_->PutChanged();
}GpuCommandBufferStub类的成员函数PutChanged调用了成员变量scheduler_指向的一个GpuScheduler对象的成员函数PutChanged,通知其GPU命令缓冲区有新的命令需要处理。
GpuScheduler类的成员函数PutChanged的实现如下所示:
void GpuScheduler::PutChanged() {
......
if (!IsScheduled())
return;
while (!parser_->IsEmpty()) {
if (IsPreempted())
break;
......
error = parser_->ProcessCommand();
......
}
......
}GpuScheduler类的成员函数PutChanged首先调用成员函数IsScheduled检查当前激活的OpenGL上下文是否允许调度。如果不允许调度,那么GpuScheduler类的成员函数PutChanged就什么也不做直接返回。
GpuScheduler类的成员函数PutChanged接下来调用成员变量parser_指向的一个CommandParser对象的成员函数IsEmpty检查GPU命令缓冲区中是否有新的命令需要处理。如果有新的命令需要处理,并且当前激活的OpenGL上下文不被抢占,即调用GpuScheduler类的成员函数IsPreempted得到的返回值不等于true,那么GpuScheduler类的成员函数PutChanged就会调用成员变量parser_指向的一个CommandParser对象的成员函数ProcessCommand从GPU命令缓冲区读出一个新命令来处理。这个过程一直循环进行,直到所有提交的GPU命令处理完毕,或者当前激活的OpenGL上下文被抢占为止。
关于OpenGL上下文的调度和抢占,我们在后面的文章再详细分析,现在我们主要关注GPU命令的处理过程,即CommandParser类的成员函数ProcessCommand的实现,如下所示:
error::Error CommandParser::ProcessCommand() {
CommandBufferOffset get = get_;
......
CommandHeader header = buffer_[get].value_header;
......
error::Error result = handler_->DoCommand(
header.command, header.size - 1, buffer_ + get);
......
if (get == get_ && result != error::kDeferCommandUntilLater)
get_ = (get + header.size) % entry_count_;
return result;
} 前面分析CommandParser类的成员函数SetBuffer时提到,CommandParser类的成员变量buffer_指向的是一个CommandBufferEntry数组,这个CommandBufferEntry数组即为GPU命令缓冲区,另外一个成员变量get_描述的是下一个要从CommandBufferEntry数组中读取的GPU命令的偏移位置。
CommandParser类的成员函数ProcessCommand通过上述两个成员变量就可以得到下一个要处理的GPU命令的头部,保存在变量header中。CommandParser类的成员函数ProcessCommand接下来调用成员变量handler_指向的一个GLES2DecoderImpl对象的成员函数DoCommand对前面得到的GPU命令进行处理。
CommandParser类的成员函数ProcessCommand处理完成当前获得的GPU命令后,通过这个GPU命令的头部信息计算下一个要处理的GPU命令在成员变量buffer_指向的CommandBufferEntry数组的偏移位置,并且保存在成员变量get_中,以便下次CommandParser类的成员函数ProcessCommand下次被调用时,可以直接读出下一个要处理的GPU命令。
接下来,我们继续分析GPU命令的处理过程,即GLES2DecoderImpl类的成员函数DoCommand的实现,如下所示:
error::Error GLES2DecoderImpl::DoCommand(
unsigned int command,
unsigned int arg_count,
const void* cmd_data) {
......
unsigned int command_index = command - kStartPoint - 1;
if (command_index < arraysize(g_command_info)) {
const CommandInfo& info = g_command_info[command_index];
unsigned int info_arg_count = static_cast(info.arg_count);
if ((info.arg_flags == cmd::kFixed && arg_count == info_arg_count) ||
(info.arg_flags == cmd::kAtLeastN && arg_count >= info_arg_count)) {
......
uint32 immediate_data_size =
(arg_count - info_arg_count) * sizeof(CommandBufferEntry); // NOLINT
switch (command) {
#define GLES2_CMD_OP(name) \
case cmds::name::kCmdId: \
result = Handle ## name( \
immediate_data_size, \
*static_cast(cmd_data)); \
break; \
GLES2_COMMAND_LIST(GLES2_CMD_OP)
#undef GLES2_CMD_OP
}
} else {
result = error::kInvalidArguments;
}
} else {
result = DoCommonCommand(command, arg_count, cmd_data);
}
......
return result;
} 在分析GLES2DecoderImpl类的成员函数DoCommand的实现之前,我们首先分析全局变量g_command_info的定义。它描述的是一个CommandInfo数组,如下所示:
const CommandInfo g_command_info[] = {
#define GLES2_CMD_OP(name) { \
cmds::name::kArgFlags, \
cmds::name::cmd_flags, \
sizeof(cmds::name) / sizeof(CommandBufferEntry) - 1, }, /* NOLINT */
GLES2_COMMAND_LIST(GLES2_CMD_OP)
#undef GLES2_CMD_OP
};这个CommandInfo数组的元素由宏GLES2_COMMAND_LIST定义,如下所示:
#define GLES2_COMMAND_LIST(OP) \
......
OP(BindBuffer) /* 259 */ \
......
OP(Flush) /* 303 */ \
......
OP(GenBuffersImmediate) /* 307 */ \
......每一个CommandInfo数组元素都是通过宏GLES2_CMD_OP定义的。例如,BindBuffer、Flush和GenBuffersImmediate对应的元素展开后就分别为:
{
cmds::BindBuffer::kArgFlags,
cmds::BindBuffer::cmd_flags,
sizeof(cmds::BindBuffer) / sizeof(CommandBufferEntry) - 1, }
{
cmds::Flush::kArgFlags,
cmds::Flush::cmd_flags,
sizeof(cmds::Flush) / sizeof(CommandBufferEntry) - 1, }
{
cmds::GenBuffersImmediate::kArgFlags,
cmds::GenBuffersImmediate::cmd_flags,
sizeof(cmds::GenBuffersImmediate) / sizeof(CommandBufferEntry) - 1, }// A struct to hold info about each command.
struct CommandInfo {
uint8 arg_flags; // How to handle the arguments for this command
uint8 cmd_flags; // How to handle this command
uint16 arg_count; // How many arguments are expected for this command.
};从这里可以看到,CommandInfo结构体有三个成员变量arg_flags、cmd_flags和arg_count,用来描述GPU命令及其参数的处理方式,以及参数个数。
回到GLES2DecoderImpl类的成员函数DoCommand中,它首先根据参数command计算当前要处理的GPU命令对应的CommandInfo结构体在全局变量g_command_info描述的CommandInfo数组的索引command_index。如果计算出来的索引超出CommandInfo数组的大小,那么就说明当前要处理的GPU命令不是一个OpenGL ES 2命令,这时候就GLES2DecoderImpl类的成员函数DoCommand调用另外一个成员函数DoCommonCommand来处理它。
如果当前要处理的GPU命令是一个OpenGL ES 2命令,那么GLES2DecoderImpl类的成员函数DoCommand接下来就验证该GPU命令附带的参数的正确性。如果一个GPU命令附带的参数个数是固定的(cmd::kFixed),那么就必须要保证它附带的参数个数,即参数arg_count的值,等于对应的CommandInfo结构体规定的参数个数。另一方面,如果一个GPU命令附带的参数个数规定有最小值(cmd::kAtLeastN),那么就必须要保证它附带的参数个数大于等于对应的CommandInfo结构体规定的最小参数个数。
通过参数正确性验证之后,GLES2DecoderImpl类的成员函数DoCommand再通过一个switch语句根据参数command的值调用相应的成员函数来处理GPU命令。这个switch语句的case子句由宏GLES2_COMMAND_LIST和GLES2_CMD_OP定义。以BindBuffer、Flush和GenBuffersImmediate三个GPU命令,它们对应的case子句分别为:
case cmds::BindBuffer::kCmdId:
result = HandleBindBuffer(immediate_data_size,
*static_cast(cmd_data));
break;
case cmds::Flush::kCmdId:
result = HandleFlush(immediate_data_size,
*static_cast(cmd_data));
break;
case cmds::GenBuffersImmediate::kCmdId:
result = HandleGenBuffersImmediate(immediate_data_size,
*static_cast(cmd_data));
break; 前面提到,如果当前要处理的GPU命令不是一个OpenGL ES 2命令,那么GLES2DecoderImpl类的成员函数DoCommand调用另外一个成员函数DoCommonCommand来处理它。GLES2DecoderImpl类的成员函数DoCommonCommand是从父类CommonDecoder继承下来的,它的实现如下所示:
error::Error CommonDecoder::DoCommonCommand(
unsigned int command,
unsigned int arg_count,
const void* cmd_data) {
if (command < arraysize(g_command_info)) {
const CommandInfo& info = g_command_info[command];
unsigned int info_arg_count = static_cast(info.arg_count);
if ((info.arg_flags == cmd::kFixed && arg_count == info_arg_count) ||
(info.arg_flags == cmd::kAtLeastN && arg_count >= info_arg_count)) {
uint32 immediate_data_size =
(arg_count - info_arg_count) * sizeof(CommandBufferEntry); // NOLINT
switch (command) {
#define COMMON_COMMAND_BUFFER_CMD_OP(name) \
case cmd::name::kCmdId: \
return Handle ## name( \
immediate_data_size, \
*static_cast(cmd_data)); \
COMMON_COMMAND_BUFFER_CMDS(COMMON_COMMAND_BUFFER_CMD_OP)
#undef COMMON_COMMAND_BUFFER_CMD_OP
}
} else {
return error::kInvalidArguments;
}
}
return error::kUnknownCommand;
} CommonDecoder类的成员函数DoCommonCommand的实现与前面分析的GLES2DecoderImpl类的成员函数DoCommand是类似的,不过它处理的GPU命令由以下的CommandInfo数组确定:
const CommandInfo g_command_info[] = {
#define COMMON_COMMAND_BUFFER_CMD_OP(name) { \
cmd::name::kArgFlags, \
cmd::name::cmd_flags, \
sizeof(cmd::name) / sizeof(CommandBufferEntry) - 1, }, /* NOLINT */
COMMON_COMMAND_BUFFER_CMDS(COMMON_COMMAND_BUFFER_CMD_OP)
#undef COMMON_COMMAND_BUFFER_CMD_OP
};这个CommandInfo数组的元素由宏COMMON_COMMAND_BUFFER_CMDS定义,如下所示:
#define COMMON_COMMAND_BUFFER_CMDS(OP) \
OP(Noop) /* 0 */ \
OP(SetToken) /* 1 */ \
OP(SetBucketSize) /* 2 */ \
OP(SetBucketData) /* 3 */ \
OP(SetBucketDataImmediate) /* 4 */ \
OP(GetBucketStart) /* 5 */ \
OP(GetBucketData) /* 6 */ \这意味着CommonDecoder类的成员函数DoCommonCommand负责处理Noop、SetToken、SetBucketSize、SetBucketData、SetBucketDataImmediate、GetBucketStart和GetBucketData这7个非OpenGL ES 2命令,对应的处理函数分别为CommonDecoder类的成员函数CommonDecoder::HandleXXX函数。
前面我们假设Client端往GPU命令缓冲区写入了GenBuffersImmediate、BindBuffer和Flush三个GPU命令,接下来我们就分别分析GPU进程是如何执行它们的,也就是分析GLES2DecoderImpl类的成员函数HandleGenBuffersImmediate、HandleBindBuffer和HandleFlush的实现。
GLES2DecoderImpl类的成员函数HandleGenBuffersImmediate的实现如下所示:
error::Error GLES2DecoderImpl::HandleGenBuffersImmediate(
uint32_t immediate_data_size,
const gles2::cmds::GenBuffersImmediate& c) {
GLsizei n = static_cast(c.n);
uint32_t data_size;
if (!SafeMultiplyUint32(n, sizeof(GLuint), &data_size)) {
return error::kOutOfBounds;
}
GLuint* buffers =
GetImmediateDataAs(c, data_size, immediate_data_size);
if (buffers == NULL) {
return error::kOutOfBounds;
}
if (!GenBuffersHelper(n, buffers)) {
return error::kInvalidArguments;
}
return error::kNoError;
} GLES2DecoderImpl类的成员函数HandleGenBuffersImmediate读出GenBuffersImmediate命令的参数n和buffers之后,就调用另外一个成员函数GenBuffersHelper进行处理。
GLES2DecoderImpl类的成员函数GenBuffersHelper的实现如下所示:
bool GLES2DecoderImpl::GenBuffersHelper(GLsizei n, const GLuint* client_ids) {
for (GLsizei ii = 0; ii < n; ++ii) {
if (GetBuffer(client_ids[ii])) {
return false;
}
}
scoped_ptr service_ids(new GLuint[n]);
glGenBuffersARB(n, service_ids.get());
for (GLsizei ii = 0; ii < n; ++ii) {
CreateBuffer(client_ids[ii], service_ids[ii]);
}
return true;
} 这个函数定义在文件external/chromium_org/gpu/command_buffer/service/gles2_cmd_decoder.cc中。
GLES2DecoderImpl类的成员函数GenBuffersHelper首先调用另外一个成员函数GetBuffer检查参数client_ids描述的Client ID是否已经有对应的Service ID。如果已经有的话,那么GLES2DecoderImpl类的成员函数GenBuffersHelper的返回值就会等于false,表示在处理GenBuffersImmediate命令时出现了错误。
通过上述检查之后,GLES2DecoderImpl类的成员函数GenBuffersHelper就可以调用OpenGL函数glGenBuffersARB生成n个Buffer ID了。这些Buffer ID称为Service ID,它们需要与参数client_ids描述的Client ID一一对应起来。
Buffer的Service ID和Client ID的对应关系是通过调用GLES2DecoderImpl类的成员函数CreateBuffer建立起来的,它的实现如下所示:
class GLES2DecoderImpl : public GLES2Decoder,
public FramebufferManager::TextureDetachObserver,
public ErrorStateClient {
public:
......
BufferManager* buffer_manager() {
return group_->buffer_manager();
}
......
void CreateBuffer(GLuint client_id, GLuint service_id) {
return buffer_manager()->CreateBuffer(client_id, service_id);
}
......
private:
......
scoped_refptr group_;
......
}; GLES2DecoderImpl类的成员函数CreateBuffer首先调用成员函数buffer_manager获得一个BufferManager对象,接着调用该BufferManager对象的成员函数CreateBuffer为参数client_id和service_id描述的Client ID和Service ID建立对应关系。
GLES2DecoderImpl类的成员函数buffer_manager返回的BufferManager对象是通过调用成员变量group_描述的一个ContextGroup对象的成员函数buffer_manager获得的。前面提到,在GPU进程,资源共享组是通过ContextGroup类描述的。这意味着在同一个资源共享组中的OpenGL上下文使用相同的BufferManager对象管理Buffer资源。
接下来,我们继续分析BufferManager类的成员函数CreateBuffer的实现,如下所示:
void BufferManager::CreateBuffer(GLuint client_id, GLuint service_id) {
scoped_refptr buffer(new Buffer(this, service_id));
std::pair result =
buffers_.insert(std::make_pair(client_id, buffer));
DCHECK(result.second);
} BufferManager类的成员函数CreateBuffer首先将参数service_id描述的Service ID封装在一个Buffer对象中,接着以参数client_id描述的Client ID为键值保存在成员变量buffers_描述的一个Buffer Map中,这样就将参数client_id和service_id描述的Client ID和Service ID建立起对应关系。
有了上述的Buffer Map之后,知道一个Buffer的Client ID,就可以通过调用BufferManager类的成员函数GetBuffer获得一个Buffer对象,如下所示:
Buffer* BufferManager::GetBuffer(
GLuint client_id) {
BufferMap::iterator it = buffers_.find(client_id);
return it != buffers_.end() ? it->second.get() : NULL;
}获得了一个Buffer对象之后,就可以调用它的成员函数service_id获得对应的Service ID,如下所示:
class GPU_EXPORT Buffer : public base::RefCounted {
public:
......
GLuint service_id() const {
return service_id_;
}
......
private:
......
GLuint service_id_;
......
}; 也就是说,给出一个Buffer的Client ID,如果它存在对应的Service ID,那么我们就可以通过调用BufferManager类的成同函数GetBuffer获得该Service ID。获得的Service ID是通过调用OpenGL函数glGenBuffersARB生成的,可以作为另外一个OpenGL函数glBindBuffer的参数使用。
以上就是GPU进程执行GenBuffersImmediate命令的过程,接下来我们继续分析GPU进程执行BindBuffer命令的过程,这是通过调用GLES2DecoderImpl类的成员函数HandleBindBuffer实现的,如下所示:
error::Error GLES2DecoderImpl::HandleBindBuffer(
uint32_t immediate_data_size,
const gles2::cmds::BindBuffer& c) {
GLenum target = static_cast(c.target);
GLuint buffer = c.buffer;
......
DoBindBuffer(target, buffer);
return error::kNoError;
} GLES2DecoderImpl类的成员函数HandleBindBuffer读出BindBuffer命令的参数target和buffer之后,就调用另外一个成员函数DoBindBuffer进行处理。
GLES2DecoderImpl类的成员函数DoBindBuffer的实现如下所示:
void GLES2DecoderImpl::DoBindBuffer(GLenum target, GLuint client_id) {
Buffer* buffer = NULL;
GLuint service_id = 0;
if (client_id != 0) {
buffer = GetBuffer(client_id);
if (!buffer) {
if (!group_->bind_generates_resource()) {
LOCAL_SET_GL_ERROR(GL_INVALID_OPERATION,
"glBindBuffer",
"id not generated by glGenBuffers");
return;
}
// It's a new id so make a buffer buffer for it.
glGenBuffersARB(1, &service_id);
CreateBuffer(client_id, service_id);
buffer = GetBuffer(client_id);
......
}
}
}
......
if (buffer) {
......
service_id = buffer->service_id();
}
......
glBindBuffer(target, service_id);
}参数client_id描述的是一个Buffer的Client ID。有了这个Client ID之后,GLES2DecoderImpl类的成员函数DoBindBuffer就可以调用另外一个成员函数GetBuffer检查它是否有一个对应的Service ID,如下所示:
class GLES2DecoderImpl : public GLES2Decoder,
public FramebufferManager::TextureDetachObserver,
public ErrorStateClient {
public:
......
Buffer* GetBuffer(GLuint client_id) {
Buffer* buffer = buffer_manager()->GetBuffer(client_id);
return buffer;
}
......
};GLES2DecoderImpl类的成员函数GetBuffer首先调用成员函数buffer_manager获得一个BufferManager对象,接着调用该BufferManager对象的成员函数GetBuffer检查参数九client_id描述的Client ID是否存在一个对应的Buffer对象。从前面的分析可以知道,如果一个我们已经为一个Buffer的Client ID生成一个对应的Service ID,那么就可以通过上述BufferManager对象的成员函数GetBuffer获得一个Buffer对象。
回到GLES2DecoderImpl类的成员函数DoBindBuffer中,如果调用成员函数GetBuffer获取不到一个与参数client_id对应的Buffer对象,那么就意味在Client端在请求GPU进程执行一个BindBuffer命令之前,没有先请求GPU进程执行一个GenBuffersImmediate命令。这时候分两种情况讨论。
第一种情况是当前激活的OpenGL上下文所属的资源共享组的bind_generates_resource属性为false,即调用当前正在处理的GLES2DecoderImpl对象的成员变量group_描述的一个 ContextGroup对象的成员函数bind_generates_resource获得的返回值为false。前面提到,这种情况是要求事先必须请求GPU进程执行一个GenBuffersImmediate命令的,否则的话就会报错,因此这时候GLES2DecoderImpl类的成员函数DoBindBuffer直接返回,并且在返回之前输出一条错误日志。
第二种情况是当前激活的OpenGL上下文所属的资源共享组的bind_generates_resource属性为true。前面提到,这种情况不要求事先请求GPU进程执行一个GenBuffersImmediate命令,因此这时候GLES2DecoderImpl类的成员函数DoBindBuffer就会模拟前面分析的GenBuffersImmediate命令的执行过程,调用OpenGL函数glGenBuffersARB生成一个Service ID,并且调用成员函数CreateBuffer建立该Service ID与参数client_id描述的Client ID的对应关系,即创建一个与参数client_id对应的Buffer对象。
另一方面,如果调用成员函数GetBuffer可以获取到一个与参数client_id对应的Buffer对象,那么处理方式与上面描述的第二种情况一样,接下来会通过调用前面获得的Buffer对象的成员函数service_id获得一个对应的Service ID。由于这个Service ID是通过OpenGL函数glGenBuffersARB生成的,因此GLES2DecoderImpl类的成员函数DoBindBuffer就可以调用另外一个OpenGL函数glBindBuffer将它与参数target描述的Buffer目标绑定起来。
以上就是GPU进程执行BindBuffer命令的过程,接下来我们继续分析GPU进程执行Flush命令的过程,这是通过调用GLES2DecoderImpl类的成员函数HandleFlush实现的,如下所示:
error::Error GLES2DecoderImpl::HandleFlush(uint32_t immediate_data_size,
const gles2::cmds::Flush& c) {
DoFlush();
return error::kNoError;
}GLES2DecoderImpl类的成员函数HandleFlush直接调用另外一个成员函数DoFlush对Flush命令进行处理。
GLES2DecoderImpl类的成员函数DoFlush的实现如下所示:
void GLES2DecoderImpl::DoFlush() {
glFlush();
......
}GLES2DecoderImpl类的成员函数DoFlush处理Flush命令的方式是调用OpenGL函数glFlush。
这样,我们就分析完成Client端请求GPU进程执行GenBuffersImmediate、BindBuffer和Flush的过程了。简单来说,就是这三个命令请求GPU进程分别执行glGenBuffersARB、glBindBuffer和glFlush三个OpenGL函数。
Client端除了通过GLES2Implementation类来请求GPU进程执行GPU命令外,还可以通过glXXX宏来请求GPU进程执行GPU命令。以前面分析的BindBuffer为例,Chromium为Client端定义了一个宏glBindBuffer,如下所示:
#define glBindBuffer GLES2_GET_FUN(BindBuffer)宏glBindBuffer又是通过另外一个宏GLES2_GET_FUN展开的,后者的定义如下所示:
#define GLES2_GET_FUN(name) gles2::GetGLContext()->name从这里看到,宏GLES2_GET_FUN(BindBuffer)展开后,就是首先调用函数gles2::GetGLContext获得一个GLES2Interface接口,然后再通过调用该GLES2Interface接口的成员函数BindBuffer请求GPU进程执行BindBuffer命令。
函数gles2::GetGLContext的实现如下所示:
gpu::gles2::GLES2Interface* GetGLContext() {
return static_cast(
gpu::ThreadLocalGetValue(g_gl_context_key));
} 函数gles2::GetGLContext从一个键值为g_gl_context_key的线程局部存储中获得一个GLES2Interface接口,并且将该GLES2Interface接口返回给调用者。
从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文可以知道,上述GLES2Interface接口是在初始化Client端的OpenGL上下文时设置的,如下所示:
bool WebGraphicsContext3DCommandBufferImpl::makeContextCurrent() {
if (!MaybeInitializeGL()) {
......
return false;
}
gles2::SetGLContext(GetGLInterface());
......
return true;
} WebGraphicsContext3DCommandBufferImpl类的成员函数makeContextCurrent会调用从父类WebGraphicsContext3DImpl继承下来的成员函数GetGLInterface获得的一个GLES2Interface接口,如下所示:
class WEBKIT_GPU_EXPORT WebGraphicsContext3DImpl
: public NON_EXPORTED_BASE(blink::WebGraphicsContext3D) {
public:
......
::gpu::gles2::GLES2Interface* GetGLInterface() {
return gl_;
}
......
private:
......
::gpu::gles2::GLES2Interface* gl_;
......
}; WebGraphicsContext3DImpl类的成员函数GLES2Interface返回的是成员变量gl_描述的一个GLES2Interface接口。
从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文可以知道,上述GLES2Interface接口是在初始化Client端的OpenGL上下文时设置的,如下所示:
bool WebGraphicsContext3DCommandBufferImpl::CreateContext(bool onscreen) {
......
real_gl_.reset(
new gpu::gles2::GLES2Implementation(gles2_helper_.get(),
gles2_share_group,
transfer_buffer_.get(),
bind_generates_resources,
lose_context_when_out_of_memory_,
command_buffer_.get()));
setGLInterface(real_gl_.get());
......
return true;
}WebGraphicsContext3DCommandBufferImpl类的成员函数CreateContext创建了一个GLES2Implementation对象后,就调用从父类WebGraphicsContext3DImpl继承下来的成员函数setGLInterface将其保存起来,如下所示:
class WEBKIT_GPU_EXPORT WebGraphicsContext3DImpl
: public NON_EXPORTED_BASE(blink::WebGraphicsContext3D) {
......
protected:
......
void setGLInterface(::gpu::gles2::GLES2Interface* gl) {
gl_ = gl;
}
......
};WebGraphicsContext3DImpl类的成员函数setGLInterface将参数gl描述的一个GLES2Implementation对象保存在成员变量gl_中。
回到前面分析的WebGraphicsContext3DCommandBufferImpl类的成员函数makeContextCurrent中,它获得了一个GLES2Interface接口之后,接下来会调用函数gles2::SetGLContext将该GLES2Interface保存在一个键值为g_gl_context_key的线程局部存储中,如下所示:
void SetGLContext(gpu::gles2::GLES2Interface* context) {
gpu::ThreadLocalSetValue(g_gl_context_key, context);
}从前面的分析可以知道,参数context指向的是一个GLES2Implementation对象,这意味着宏GLES2_GET_FUN(BindBuffer)展开后,实际上是通过调用GLES2Implementation类的成员函数BindBuffer请求GPU进程执行BindBuffer命令。也就是说,在Client端通过glXXX宏请求GPU进程执行GPU命令,最终也是通过GLES2Implementation类来请求GPU进程执行GPU命令的。
至此,我们就分析完成Client端,即WebGL端、Render端和Browser端,请求GPU进程执行GPU命令的过程了。我们知道,有些GPU命令附带的数据很大,例如glTexImage2D命令,它附带的纹理数据可能是非常大的。Chromium提供了同步和异步两种机制有效地将这些数据从Client端传递到GPU进程中去使用。在接下来一篇文章中,我们将以纹理数据为例,分析Client端和GPU进程之间的同步和异步数据传递机制,敬请关注!更多的信息也可以关注老罗的新浪微博:http://weibo.com/shengyangluo。