《Hadoop》"呶呶不休"(五)Windows10下的Eclipse搭建Hadoop2.7.3开发环境
在这一章里,我们来学习如何在Windows操作系统下,搭建Hadoop2.7.3集群的Eclipse开发环境。
一、准备工作
1、安装Hadoop2.7.3集群
我们使用VMware工具安装多台Linux系统,然后在Linux系统上搭建我们所需要的Hadoop2.7.3完全分布式集群。具体步骤可以参考我写的《Hadoop》之"踽踽独行"(十)快速搭建一个Hadoop完全分布式集群或者是另一篇文章《Hadoop》之"踽踽独行"(四)CentOS 6.5搭建hadoop2.7.3集群环境。
2、安装Eclipse开发工具
在Windows操作系统下安装jdk开发环境和Eclipse开发工具。Jdk我选择的是"1.8.0_191",Eclipse是photon版本。你们在版本选择上,只要不是太旧就好。
3、下载Hadoop支持Eclipse的插件
hadoop-eclipse-plugin-2.7.3.jar。可以在https://download.csdn.net/download/michael__one/10919759这个地址下载。
4、在Windows操作系统下,安装Hadoop2.7.3
在windows系统下,安装一个Hadoop2.7.3(就是解压到某一个路径下)。在里面创建四个目录备用:如_jars,_tests,_sources,_confs。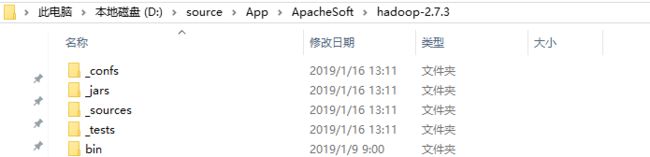
然后,在其share目录下搜索.jar文件,将查询出来的所有jar包 复制一份出来,放到_jars目录下,去重。

再从_jars目录下搜索test,将test的jar包剪切到_tests目录下。
然后继续从_jars目录下搜索sources,将sources的jar包剪切到_sources目录下。
再从share目录下搜索default.xml,将四个默认配置文件复制到_confs目录下。
这样我们就将hadoop的字节码jar包(_jars),源码(_sources),测试包(_tests),配置文件(_confs)提取出来了。
四、开始搭建Hadoop的Eclipse开发环境
第一步:关闭Eclipse,安置插件
将插件压缩包内的hadoop-eclipse-plugin-2.7.3.jar存放在eclipse的安装目录下的plugins目录内
![]()

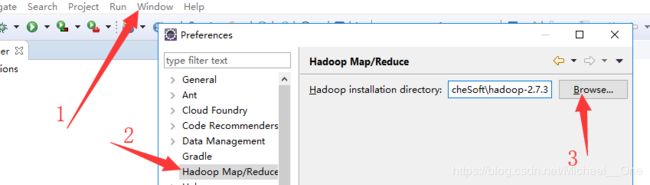
第二步:打开Eclipse,指定Hadoop2.7.3安装路径
打开后,出现DFS Locations说明上一步操作没有问题

按下图找到位置,配置windows操作系统上解压的hadoop2.7.3。即指定到hadoop的根目录。apply and close
第三步:显示Map/Reduce Locations窗口
Window->Show View->other->搜索Map/Reduce->open

第四步:配置Hadoop集群信息
右键点击Map/Reduce Locations窗口空白处->New Hadoop location:出现下面窗口,我们来填写信息
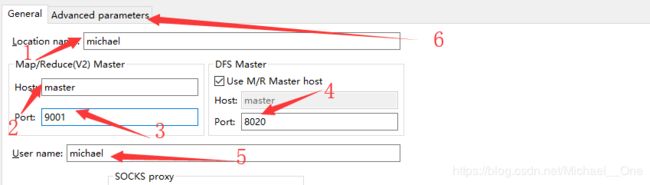
第1处、Location name:就是昵称,随便填写即可
第2处、Host: 填写Namenode的主机名或者是IP,如果你在Windows下的hosts配置了主机名和ip映射,就可以添加主机名。
第3处、Port:添加9001,或者是8021(mapreduce rpc端口号,不过大家可以随便填写一个端口进行测试,我发现都可以哦)
第4处、DFS Port:添加你在core-site.xml里配置的HDFS的默认端口号,可能是8020,也可能是9000。
第5处、User name:填写搭建hadoop集群时,使用的用户。
第五步:配置参数
点击上图中的第六处,我们会看到这样的窗口

然后,我们找到参数fs.defaultFS,配置你Hadoop集群的默认HDFS的端口:如下图
![]()
第二个参数hadoop.tmp.dir,检测一下是不是你的hadoop集群的设置,不是的话,改成你集群的设置
![]()
第三个参数dfs.namenode.name.dir,检测一下。
![]()
第四个参数dfs.datanode.data.dir,检测一下。
![]()
然后,选择finish,关闭窗口,我们会看到窗口多了一个蓝色的小象。

再看看左边的窗口,我们就可以展开后,看到HDFS集群上的文件数据了。
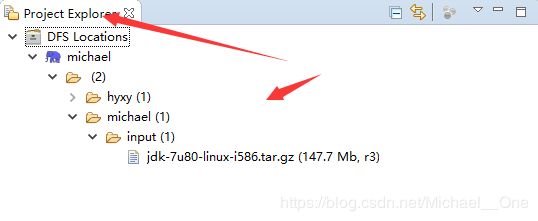
第六步:上传文件测试
在下图中标记为1的目录其实对应的就是HDFS文件系统的根目录。
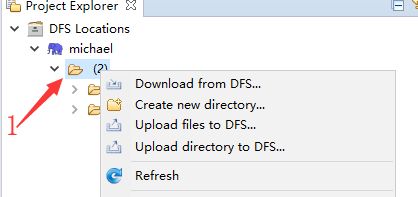
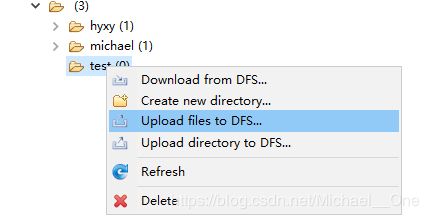
我们右键点击根目录,选择Create new directory 来创建一个子目录test,然后右键点击刷新,将test目录刷新出来。然后再选中test,右键点击Upload files to DFS,随便选择一个你本地的文件,进行上传即可。
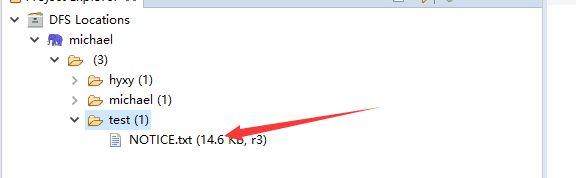
再刷新后,就可以看到你上传的文件信息了
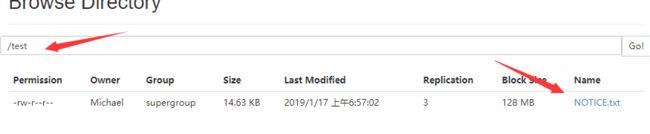
然后,我们通过浏览器,再查看一些HDFS文件系统:
到这里,我们就完美结束了,你也可以在eclipse写MapReduce程序了哦。
五:错误解析
当你在eclipse开发工具上写程序访问HDFS时,我们需要在windows环境下配置Hadoop的环境变量。
1、在系统变量或者是用户变量里,新建:HADOOP_HOME变量名,变量值就是Hadoop的安装路径。
2、在path变量里追加%HADOOP_HOME%\bin;
然后就可以使用API来操作HDFS了。
如果报以下错误:
Could not locate executable D:\Users\Michael\Apps\hadoop-2.7.3\bin\winutils.exe in the Hadoop binaries.
请将下载的插件包的bin目录下的hadoop.dll和winutils.exe,复制到hadoop的bin目录下即可。

-------------------------------如有疑问,敬请留言--------------------------------------------