2019年CS224N课程笔记-Lecture 1: Introduction and Word Vectors
资源链接:https://www.bilibili.com/video/BV1r4411f7td?p=1(中英文字母版,不过可能由于up主不了解专业术语,许多专业术语翻译的不是很好,不过也要感谢up的辛苦劳作了~)
(2019的感觉相对于之前的少了许多类似前言介绍的内容,我在这里将总结一下之前版本的CS224N的本次课程没讲解的内容)
补充的前沿知识:
什么是自然语言处理 (NLP)?
NLP/Natural Language Processing= computer science + artificial intelligence + linguistics
自然语言处理可以视为多个领域的组合,涉及到计算机科学,AI人工智能,以及语言学知识,属于一个包含多学科的综合领域。
自然语言处理的目标:
使得计算机能够处理或者“读懂”自然语言,以完成一些有用的任务。
但是,完全理解或者展示语言所包含的意思(甚至是对语言进行定义)是一件非常困难的事情。
NLP 的应用:
- 中文自动分词(Chinese word segmentation)
- 词性标注(Part-of-speech tagging)
- 句法分析(Parsing)
- 自然语言生成(Natural language generation)
- 文本分类(Text categorization)
- 信息检索(Information retrieval)
- 信息抽取(Information extraction)
- 文字校对(Text-proofing)
- 问答系统(Question answering)
- 机器翻译(Machine translation)
- 自动摘要(Automatic summarization)
- 文字蕴涵(Textual entailment)
什么是深度学习 (DL)?
深度学习是机器学习的一个分支。机器学习就是让机器自动学习,而不是手工写代码,告诉机器应该怎么做。而深度学习与传统的机器学习不同。传统的机器学习其实就是让人类来审视一个特定的问题,找出解决问题的关键,然后设计出与该问题相关的特征,然后写代码来识别这些特征。这样实质上机器并没有学习什么,倒是人类学习了很多。他们仔细研究问题,做了大量的数据分析和理论研究,判断那些属性是重要的。看起来机器只做了一件事,就是数值优化。
机器学习几乎90%决定于人,而10%决定于计算机计算,而深度学习相反。(机器学习的成功更取决人设计的算法,而深度学习更倾向于数据集的好坏和大量时间的训练)
机器学习 vs. 深度学习:
机器学习: 用特征来描述数据,主要在于学习算法,最优化权值
深度学习: 自动学习好的特征。通过模型的输入的数据自动学习特征(本质上也是最优化权值)。
目前深度学习火热的原因:
在机器学习中,人为设计的特征往往过于特殊,对于某些数据集可能表现较好,但泛化能力差,并且模型特征构造不足会直接影响模型的效果,需要较长的时间来设计特征。
深度学习可以快速地学习特征,并根据不同的数据集及时进行改变
相较于两者来说,深度学习需要的数据量更大,这在之前是很难实现的,大家也都知道,大数据现在发展的非常迅速,也为深度学习一定程度上解决了这个问题,而且目前大公司也是打信息战,数据的存储也比以往更加重视。
而且深层的神经网络比机器学习理论上更容易捕捉数据的特征。
NLP难在哪里?
知识的表示,学习和使用都很复杂(举个例子:光词向量这个目前代表语言的一个计算机识别单位,还是没有一个非常完成的,例如图片、数据等,都是计算机直接可以识别的,但是语言不一样)
人类知识含义当中的不确定性(用一句名言来解释吧,一千个读者就有一千个哈姆雷特。日常中一句话,不同的人都有不同的理解,所以说语言是不确定的)
正课内容:
人类语言的特点
人类语言是一种混乱的,就是每个人的理解是不一样的,即使是同一句话。这也就是我们说的语义理解问题,我们交流时尽可能的让别人明白自己想要表达的意思。
词的表示:在语言中,可能是汉字、单词、或者其他语言的基本单位,那么在计算机中是怎么表示哪?之前普遍的做法是使用WordNet这个词典。
WordNet是一个由普林斯顿大学认识科学实验室在心理学教授乔治·A·米勒的指导下建立和维护的英语字典。由于它包含了语义信息,所以有别于通常意义上的字典。WordNet根据词条的意义将它们分组,每一个具有相同意义的字条组称为一个同义词集合。WordNet为每一个同义词集合提供了简短,概要的定义,并记录不同同义词集合之间的语义关系。在WordNet中,名词,动词,形容词和副词各自被组织成一个同义词的网络,每个同义词集合都代表一个基本的语义概念,并且这些集合之间也由各种关系连接。
但是存在很多问题,不能准确表述单词之间的相似性,以及需要人工进行维护,对于现在需要大量的词语来说,这无非是一个灾难性的工作。
在传统的NLP中,主要采用ont-hot向量来表达单词。
(课程中没有具体介绍one-hot,这里可以看一下我之前的文章,之前的文章很多都是自己也不太明白的情况下写的,但是one-hot这部分写的还是比较明白的https://blog.csdn.net/RHJlife/article/details/104893608,同时课程中也缺少TF-IDF文本向量化,有兴趣的可以看一下)
one-hot缺点:由于语料库比较大,导致向量过于庞大,有多少个词,向量就多长,而且不能表达单词之间的相似性,因为各个向量正交,无法计算余弦相似度。
解决的一个思路:一个单词的词向量可以通过上下文单词的含义决定。如果这个单词向量通过上下文单词找出来的,意味着这个单词可以很好的生成出自己的上下文单词(经常出现在自己上下文中的单词的生成概率大)。这也就是我们常说的分布式词向量,考虑语义的一种思路。
word2vec
其实word2vec分为两个模型分别为跳字模型(根据一个中心词生成上下文)和连续词袋模型(根据上下文生成一个中心词),课程中以词袋模型为例子讲的
实现思想:
- 我们有个很大的语料库
- 语料库中的词都可以用一个向量表示(训练过程是两个向量表示:中心词向量和背景词向量)
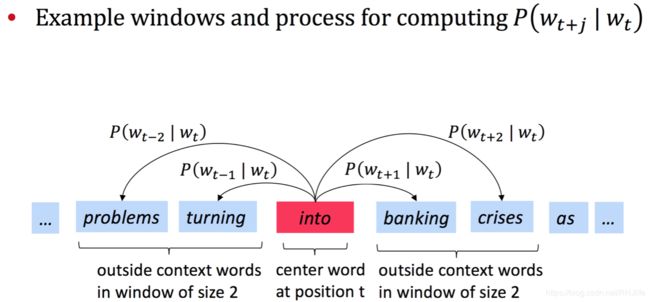
- 遍历一个文本,对于文本中的每个位置t,遍历到的位置t对应的词称为中心词c,中心词的上下文单词成为词o(选择中心词上下m个词作为背景词,m也叫窗口大小,是人为设定的超参数)
- 使用词向量c和词向量o的相似性来计算,当给定词c时词o出现的概率,即p(o|c)
word2vec目标函数和损失函数
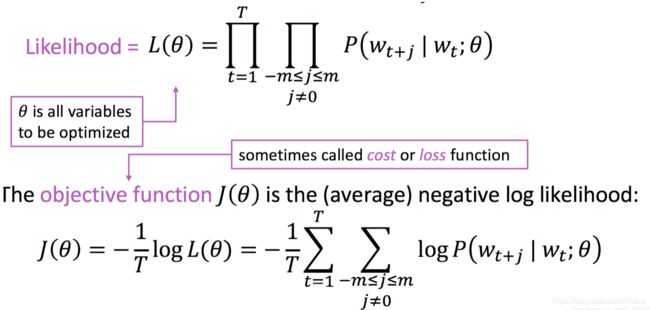
L为目标函数,具体含义就是,遍历该语句,语句长度为T,所以第一层为t=1->t=T,意味着中心词的移动;因为每次中心词时都要求该中心上下m个背景词和中心词的概率,所以背景词是t+j,j在-m到m之间,且不等于0(因为等于0就是中心词了);θ是超参数矩阵(因为后续要求到等,而且超参数非常多,所以用θ表示所有的超参数);我们希望目标函数的值最大化,但是往往最大化不容易求解,而最小值更容易求解,所以将上述L转化为J,J为损失函数,也就是L的等价变化的负值。
为什么等价哪?因为添加log是不影响最大值和最小值的,而且把乘转化为求和,更容易计算(如果还想问为什么变成求和更容易,后续自己可以不变化成log然后计算一下就知道了),加负号是将求最大值变成最小值,T的引入实际上把函数倍减,也不影响最大值和最小值,后续求导可能方便约分等。
那么,概率等于多少哪?也就是P函数函数如何设计?

u代表背景词向量,v代表中心词向量。解释一下为什么这么设计,首先橙色部分,为什么是中心词向量和背景词向量的点乘哪?因为点乘对两个向量有表示相似度的含义(具体可以查阅余弦相似度的概念);蓝色部分中V代表所有样本,也就是分母是分子的所有可能的和,为什么分母是对分子的求和?因为这样就可以表示概率了呀~不明白的话,我就这么解释:你抽中红球的概率是不是(红球/所有球之和),就这个意思,单个样本/所有样本就是该样本的概率;为什么用exp来对橙色部分进行处理?因为点乘可能正负,对于概率来说,是不合理的,所以加上exp,则分子一定是正数,分母更不用说了;其实p函数采取的是一种softmax的思想,有兴趣的可以了解下,softmax中的操作其实就是上述解释~
求loss函数的梯度
(课程推到,原理是链式法则,有兴趣的可以自己推到一下~)


(求和的话,可以发现如果求很多求导,例如u1,其他不含该项的其实是0的)


参数更新/梯度更新:

α是学习率(一个超参数,人为设定的)
优化的过程是怎么样的?
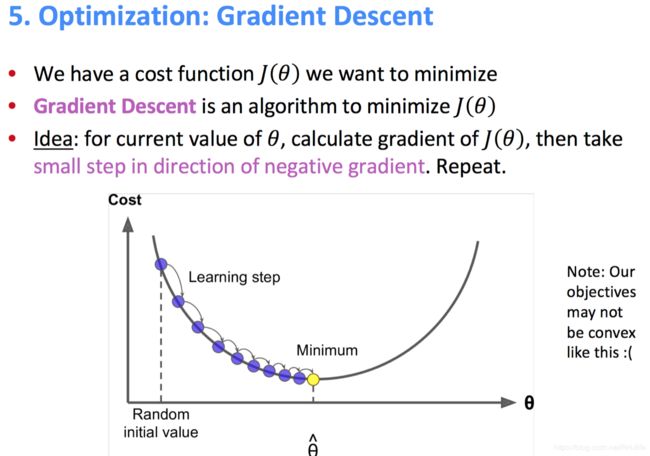
其实上述是不准确的,以往实际上曲线可能是曲曲折折的,这是一个比较理想的图。沿梯度方向不断下降,最终就会区域最小值(也有可能是局部最小值,这个ai知识有基础的话应该是的是咋回事~)
为什么采取两个词向量(背景词向量和中心词向量)呢?
第一点解释就是容易实现,因为word2vec有两套模型:跳字模型/skip-gram(通过中心词预测上下文单词)和连续词袋模型CBOW(通过上下文单词预测中心词),只用一个会很麻烦
最终的词向量选择是谁?答案:中心词向量+背景词向量,为什么呢?因为加权平均的思想,中心词向量+背景词向量其实与(中心词向量+背景词向量)/2是等价的,求平均和求和实际一样的(常数项不影响实际含义的~这句话一定要理解)
因为p函数分母和整个语料库有关系,所以时间复杂度是非常高的,所以可以采用随机梯度下降的方法,也就是随机抽取其中一些样本进行训练,而不必训练这个预料库。
大家可能有疑问:随机采样的话是不是不准》确实有一点点,但是随机采样的样本的数学期望其实和整体是一样的,理论上可以一定程度上代表整体样本(虽然是随机的,但是其实大部分样本都会训练到的,这么理解1000个样本,我每次取100,其实是一轮要进行10轮,每次100个,每次分母只计算这抽取的100个的;原先是1000个样本进行一轮,分母是计算全部的1000个;实际上都是训练了1000个数据,不会存在遗漏的,但是分母不太一样,可以细细品味~)
课程上没说,不过还有两套近似算法来优化上述p函数与整个语料库有关的问题,分别是:负采样和层序softmax