NLP-tutorial代码笔记1
现在每次后面都会加上一个Q&A部分,就是每次有人看完,讲完后的问题,或者是一些不全面的方面,以问答的形式呈现出来。
现在开的坑系列是Github上一个即将3k+Star的NLP-tutorial项目,里面是一些NLP方面的Deep-learning代码,框架Tensor和Torch都有,而且实现行数基本都控制在了100行以内,比较适合去研究一下。这样之后搭框架的时候就会明白许多了。
项目地址:https://github.com/graykode/nlp-tutorial
第一部分是基本的Embeddeding模型
这部分是基于非常经典的paper,A Neural Probabilistic Language Model,http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
这份代码就是展现了这个里面的模型代码。所以首先先介绍一下这个论文的内容。
A Neural Probabilistic Language Model 论文内容
论文的内容介绍参考了一下博客:
https://blog.csdn.net/hx14301009/article/details/80345449
https://www.jianshu.com/p/be242ed3f314
传统的语言模型缺点
1.由于维度灾难(特别是离散变量),在高维下,数据的稀缺性导致统计语言模型存在很多为0的条件概率,传统的统计语言模型也花费大量的精力来处理这个,包括平滑,插值,回退等方法
2.语言模型的参数个数随着阶数呈指数增长,所以一般这个模型的阶数不会很高,这样n-gram无法建立长远的关系
3.n-gram无法建模出多个相似词的关系,比如在训练集中有: the cat is walking in the bedroom,但是用n-gram预测时,遇到:the dog was running in a room这个句子,并不会因为两个句子相似就让该句子的概率变高
所以基于以上的问题,就想要引入别的模型来解决这个问题。
这篇NNLM使训练得到的模型比传统的统计语言模型使用n-gram能建模更远的关系,并且考虑到了词与词之间的相似性,一些相似的词获得了自然的平滑。前者是因为神经网络的结果使得,后者是因为使用了词向量。
词向量
在NLP任务中,第一步首先将自然语言转化成数学符号表示。一般常用的词汇表示方法:one-hot表示,这种方法是将每个单词表示为一个很长的向量,这个向量的长度是词汇表的大小,其中绝大数元素是0,只有一个元素是1,如“男人”表示为:[0 0 0 1 0 0 0 0 0 0…],“男孩”表示为:[0 1 0 0 0 0 0 0 0 0…]。one-hot方法采用稀疏的方式进行单词的表示,非常的简洁。即为每个单词分配一个数字ID号,数字ID号对应于每个单词在词汇表中的索引。比如“国王”这个词语在词汇表中的索引是3,“男孩”这个词语在词汇表中的索引是1。
one-hot编码单词存在的问题:每个one-hot向量之间是相互正交的,任意两个单词之间是相互独立的,仅从one-hot表示出的词向量中无法看出两个单词之间是否有关系,即使是同义词也是相互独立。
大多数NLP任务中,一般用到的词向量并不是one-hot表示出来的维数很长的词向量,而是采用一种"Distributed Representation"的表示方法来表示一种低维实数向量。这个词向量的表示一般是这样的:[0.792,-0.177,-0.107,0.109,-0.542,…],维度以5o和100维比较常见,这种向量的表示也不唯一。
Distributed Representation最大的贡献是让相关或相似的词,在距离上更接近。向量的距离可以是传统的欧式距离衡量,也可以使用余弦相似度cosine来衡量。
具体模型解释
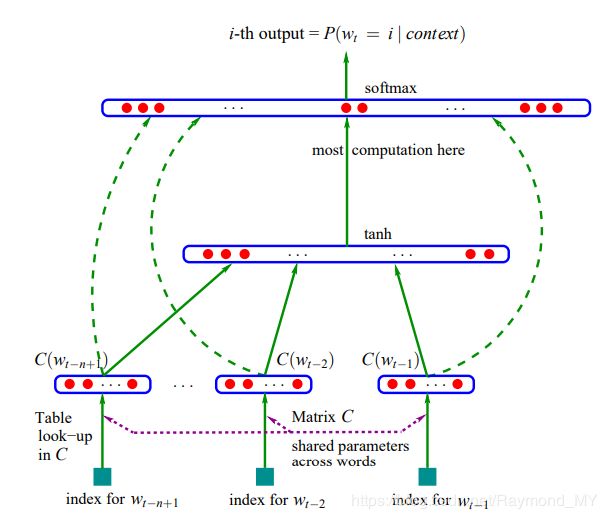
目标:上图中最下方的wt-n+1,…,wt-2,wt-1就是前n-1个单词,现在根据这已知的n-1个单词预测下一个单词wt。
数学符号说明:
C(w):表示单词w对应的词向量,整个模型中使用一套唯一的词向量。
C:词向量C(w)存在于矩阵C(|V|m)中,矩阵C的行数表示词汇表的大小;列数表示词向量C(w)的维度。矩阵C的某一行对应一个单词的词向量表示。
|V|:表示词汇表的大小,即语料库中的单词总数
m:表示词向量C(w)的维度,一般是50到100
w到C(w)的转化:从矩阵C中取出一行
d:隐藏层偏置bias(h)
H: 隐藏层的权重(h(n-1)m)
U:隐藏层到输出层的权重(|V|h)
b:输出层的偏置bias(|V|)
W:输入层到输出层权重(|V|(n-1)m)
h:隐藏层神经元的数量
网络的第一层(输入层)是将C(wt-n+1),…,C(wt-2),C(wt-1)这已知的n-1和单词的词向量首尾相连拼接起来,形成(n-1)w的向量,下面用x表示。
网络的第二层(隐藏层)直接用d+Hx计算得到,d是一个偏置项。之后,用tanh作为激活函数。
网络的第三层(输出层)一共有|V|个节点,每个节点yi表示下一个单词i的未归一化log概率。最后使用softmax函数将输出值y归一化成概率,最终y的计算公式如下:
y = b + Wx + Utanh(d+Hx)
最后,用随机梯度下降法把这个模型优化出来就可以了。
Torch代码实现+注释
以下是具体的模型代码实现,每行都有注释
# code by Tae Hwan Jung @graykode
import numpy as np
import torch
import torch.nn as nn # torch的神经网络库,里面有很多基本的神经网络基础代码,比如Conv2d,ReLU等
import torch.optim as optim # optimizer的简称,是实现各种优化算法的包,比如梯度下降,比如Adam
# 这个库中提供了类和函数用来对任意标量函数进行求导,引入Variable可以实现自动求导
from torch.autograd import Variable
# 在pyTorch中,基本的数据结构是Torch,包含了多维张量,可以就把它看作是n维矩阵的一个表示
dtype = torch.FloatTensor # 创建一个浮点tensor,还没有对其赋值和规定其维度大小
# 本次将要训练的句子集,也就是输入
sentences = [ "i like dog", "i love coffee", "i hate milk"]
# 以下两行代码是将上面sentences列表中的单词提取出来
word_list = " ".join(sentences).split() # 每句首先使用空格分割形成一个单词列表
word_list = list(set(word_list)) # 用一个小技巧,先让list变成set,然后再变回去,这样就提取出了单词列表
# 以下两行是建立单词对应序号的索引字典word_dict和序号对应单词的索引number_dict
# 使用了enumerate函数,使得在遍历的同时可以追踪到序号,i, w是元组,其实可以写成(i, w)
word_dict = {w: i for i, w in enumerate(word_list)} # w: i 单词对应序号键值对
number_dict = {i: w for i, w in enumerate(word_list)} # i: w 序号对应单词键值对
n_class = len(word_dict) # number of Vocabulary
# NNLM Parameter
n_step = 2 # n-1 in paper 根据前两个单词预测第三个单词
n_hidden = 2 # h in paper 隐藏层神经元个数
m = 2 # m in paper 词向量维数
# make_batch是将输入sentences中的前面的单词和最后一个单词分开
def make_batch(sentences):
input_batch = [] # 用于存放输入的单词
target_batch = [] # 用于存放最后一个单词,模拟预测的结果
for sen in sentences: # 对sentences中的每个句子
word = sen.split() # 默认空格分割
input = [word_dict[n] for n in word[:-1]] # 注意这里的切片不能切反了,[:-1]是刚好最后一个不要
target = word_dict[word[-1]] # 最后一个单词
# 将分离好的输入结果放到列表中存好
input_batch.append(input)
target_batch.append(target)
return input_batch, target_batch
# Model NNLM模型部分
class NNLM(nn.Module): # 定义网络时一般是继承torch.nn.Module创建新的子类
def __init__(self): # 构造函数
super(NNLM, self).__init__() # 子类构造函数强制调用父类构造函数
# 参数都是论文中的数学表示
# 以下是设置神经网络中的各项参数
# 一个嵌入字典,第一个参数是嵌入字典的大小,第二个参数是每个嵌入向量的大小
# C词向量C(w)存在于矩阵C(|V|*m)中,矩阵C的行数表示词汇表的大小;列数表示词向量C(w)的维度。矩阵C的某一行对应一个单词的词向量表示
self.C = nn.Embedding(n_class, m)
# Parameter类是Variable的子类,常用于模块参数,作为属性时会被自动加入到参数列表中
# 隐藏层的权重(h*(n-1)m)
self.H = nn.Parameter(torch.randn(n_step * m, n_hidden).type(dtype))
# 输入层到输出层权重(|V|*(n-1)m)
self.W = nn.Parameter(torch.randn(n_step * m, n_class).type(dtype))
# 隐藏层偏置bias(h)
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype))
# 隐藏层到输出层的权重(|V|*h)
self.U = nn.Parameter(torch.randn(n_hidden, n_class).type(dtype))
# 输出层的偏置bias(|V|)
self.b = nn.Parameter(torch.randn(n_class).type(dtype))
# 前向传播过程,如paper中描述
def forward(self, X):
X = self.C(X)
X = X.view(-1, n_step * m) # [batch_size, n_step * n_class]
tanh = torch.tanh(self.d + torch.mm(X, self.H)) # [batch_size, n_hidden]
output = self.b + torch.mm(X, self.W) + torch.mm(tanh, self.U) # [batch_size, n_class]
return output
model = NNLM() # 初始化模型
# 损失函数定义为交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 采用Adam优化算法,学习率0.001
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 以下三行将输入进行torch包装,用Variable可以实现自动求导
input_batch, target_batch = make_batch(sentences)
input_batch = Variable(torch.LongTensor(input_batch))
target_batch = Variable(torch.LongTensor(target_batch))
# Training 训练过程,5000轮
for epoch in range(5000):
optimizer.zero_grad() # 初始化
output = model(input_batch)
# output : [batch_size, n_class], target_batch : [batch_size] (LongTensor, not one-hot)
loss = criterion(output, target_batch)
if (epoch + 1)%1000 == 0: # 每1000轮查看一次损失函数变化
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
# 自动求导反向传播,使用step()来更新参数
loss.backward()
optimizer.step()
# Predict 预测值
predict = model(input_batch).data.max(1, keepdim=True)[1]
# Test 测试
print([sen.split()[:2] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
Q&A
Q:最开始的“语言模型的参数个数随着阶数呈指数增长,所以一般这个模型的阶数不会很高,这样n-gram无法建立长远的关系”,这句话不是很能理解:
A:在语言模型中,n-gram每增加一个gram,就需要增加一个维度,而且在one-hot向量的基础上,每增加一个维度,就会增加非常多的内容,比如一开始是2-gram,词库一共有10000个单词,这样就是210000,再加一个gram就是310000。这个增加的量级是很大的,所以导致的模型的阶数不能很高。
Q:这篇文章的主要贡献究竟是什么,为什么它的任务是预测,但是最终的contribution却是得到了词向量矩阵呢?
A:很多NLP方面的任务,基础都是词向量,有了词向量,才能进一步去做其它任务。这篇论文主要讲的是预测,代码写的也是预测。但是它的重点是通过神经网络的方法来搭建了一个训练词向量的平台。也就是借助预测的方式,来训练词向量。代码中也可以很好的体现这一点。一开始的词向量是Embedding矩阵,也就是一个随机的矩阵,随着学习过程的不断进行,得到的词向量也就越来越符合本次任务运用的需要。