【Python】批量给PDF添加目录
零:参考
如何给PDF文件加目录? - Emrys的回答 - 知乎
注:本文代码在原文基础上修改。增加了去除其他符号、对gbk编码pdf支持等新功能,亲测可用
一、环境准备
0.为方便对pdf资料进行学习,对pdf增加目录索引(影印版也可以使用)
1.python 2或3 环境
2.操作PDF的第三方库:PYPDF2
pip install PyPDF2
3.目录结构txt文件
使用一个txt文件,内容如下:每行写一个索引,前面写索引名,后面写pdf中的实际页码。行与行之间按照目录级别进行缩进,同级目录缩进相同。每行后面使用任意大于一个空格或者制表符接页码
可以使用OCR(可以使用Adobe Acr0bat DC软件等)将原文目录转成文档,自行缩进编辑成txt,代码自动去除各种符号
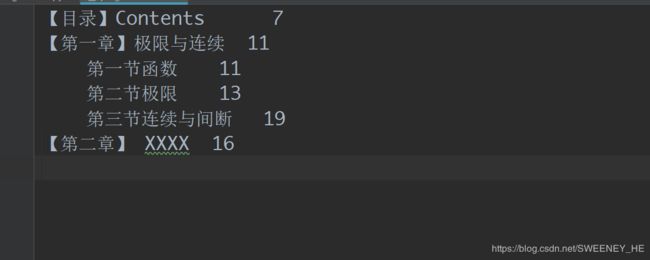
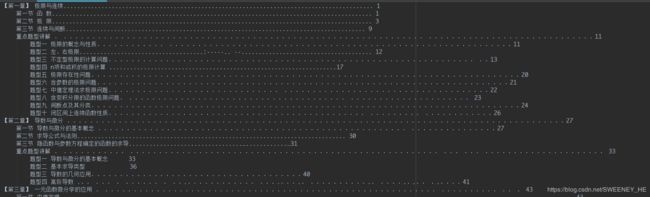
识别+手动缩进+数字改正后的效果
最终效果:


二.实现代码
1.代码
import re
import string
import sys
from distutils.version import LooseVersion
from os.path import exists, splitext
from PyPDF2 import PdfFileReader, PdfFileWriter
is_python2 = LooseVersion(sys.version) < '3'
def _get_parent_bookmark(current_indent, history_indent, bookmarks):
'''The parent of A is the nearest bookmark whose indent is smaller than A's
'''
assert len(history_indent) == len(bookmarks)
if current_indent == 0:
return None
for i in range(len(history_indent) - 1, -1, -1):
# len(history_indent) - 1 ===> 0
if history_indent[i] < current_indent:
return bookmarks[i]
return None
def addBookmark(pdf_path, bookmark_txt_path, page_offset):
if not exists(pdf_path):
return "Error: No such file: {}".format(pdf_path)
if not exists(bookmark_txt_path):
return "Error: No such file: {}".format(bookmark_txt_path)
with open(bookmark_txt_path, 'r',encoding='utf-8') as f:
bookmark_lines = f.readlines()
reader = PdfFileReader(pdf_path)
writer = PdfFileWriter()
writer.cloneDocumentFromReader(reader)
maxPages = reader.getNumPages()
bookmarks, history_indent = [], []
# decide the level of each bookmark according to the relative indent size in each line
# no indent: level 1
# small indent: level 2
# larger indent: level 3
# ...
#排除特殊符号
#保留字母、数字、中文、中文括号,其他自定义需要保留的可以自行添加到此处
rule = re.compile(r"[^a-zA-Z0-9()【】\u4e00-\u9fa5]")
for line in bookmark_lines:
line2 = rule.sub(' ',line)
line2 = re.split(r'\s+', unicode(line2.strip(), 'utf-8')) if is_python2 else re.split(r'\s+', line2.strip())
if len(line2) == 1:
continue
indent_size = len(line) - len(line.lstrip())
parent = _get_parent_bookmark(indent_size, history_indent, bookmarks)
history_indent.append(indent_size)
title, page = ' '.join(line2[:-1]), int(line2[-1]) - 1
if page + page_offset >= maxPages:
return "Error: page index out of range: %d >= %d" % (page + page_offset, maxPages)
new_bookmark = writer.addBookmark(title, page + page_offset, parent=parent)
bookmarks.append(new_bookmark)
out_path = splitext(pdf_path)[0] + '-new.pdf'
with open(out_path,'wb') as f:
writer.write(f)
return "The bookmarks have been added to %s" % pdf_path
if __name__ == "__main__":
import sys
args = sys.argv
if len(args) != 4:
print("Usage: %s [pdf] [bookmark_txt] [page_offset]" % args[0])
print(addBookmark(pdfPath,contentStructPath, offset))
2.参数介绍:
pdfPath:pdf路径
contentStructPath:目录txt的路径
offset:pdf实际页数与书籍页码的偏移(对于目录页和正文偏移不同的可以按大的偏移来设置,在txt中对偏移小的将页码设置为负数来补偿)