Hadoop入门(1)安装配置篇(JDK、Hadoop分布式的安装,克隆服务器,SSH免密码登录等)
本章目的
- 介绍了基于Linux的Hadoop安装与配置。
- 包括虚拟机创建 、Linux系统和JDK安装、 Hadoop安装及Hadoop分布式安装。
- 还介绍了克隆服务器和SSH免密码登录。
目录
0、提前下载需知
1、在vmware上安装centos
2、给centos配置网络
3、克隆服务器
4、关闭防火墙
5、链接xshell
6、SSH免密码登录
7、安装java jdk
8、安装Hadoop
9、Hadoop分布式安装(配置HDFS)
0、提前下载需知
- 必要的软件:vmware workstation
- 需要的工具:centos(iso文件)、java jdk(rpm文件)
- 辅助的软件:xshell、xftp
- 需要的基础知识:会用linux指令、懂得编写java。
- 百度云链接(提取码:km1g)
1、在vmware上安装centos
- 很简单,不赘述,可参考别的博客。
- 就两点:记住你自己设置的密码,网络选择NAT模式。
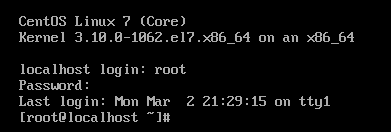
- 安装好了以后,用户名为root(除非你设置了其他用户名),输入密码即可(密码不显示)
2、给centos配置网络
2.1 进入编辑模式
- 继续输入(注意vi后面有空格)
vi /etc/sysconfig/network-scripts/ifcfg-eth0
- 回车确定后,再按键盘“i”,当底部出现“INSERT”字样时,说明已经进入编辑模式。(如果出现错误e325,是因为之前强制退出了vmware,导致还没完成的文本变成了临时文件swp,定位到该目录,利用rm指令删除该文件即可)
2.2 编辑更改文本信息

- 更改文件中的配置信息,其他信息不用修改。除了IP地址不需要一致以外,上图的其余信息要一致。如果没有这些内容,需要用户手动敲入。
- 注意!上图中IPADDR和GATEWAY中的IP地址的第三个数值不能乱填,点击vmware的“编辑”,找到“虚拟网络编辑器”
- 然后点击“ NAT设置 ”,查看自己的网关IP。
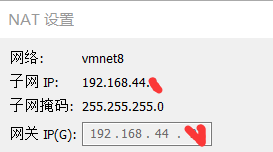
- IPADDR和GATEWAY中的IP地址的第三个数值要和网关IP的第三个数值一样才行(我这台机器是44),IPADDR的第四个数值建议填写100~500的数值。
2.3 保存更改并退出
- 按“esc”键后,输入‘:wq’回车,保存退出即可。
2.4 重启网卡,生效刚刚修改ip地址
- 输入以下指令。
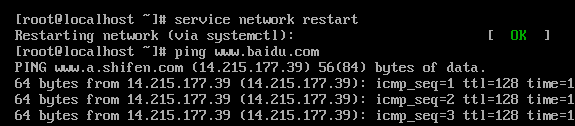
service network
restart命令重启网卡。等一会儿,如果出现ok,那就没问题了。
2.5 利用ping测试网络
- 输入以下指令。
ping www.baidu.com
如果没问题,那么centos就安装好了~。 (中断输出指令:‘ctrl’ + ‘c’)
3、克隆服务器
- 被克隆的机器也称主机、主节点,克隆机是从机、从节点。
3.1、克隆步骤
- 为了减少重复配置,可以直接将配置好的机器进行克隆,克隆时,被克隆的机器(主机)必须处于关机状态下。
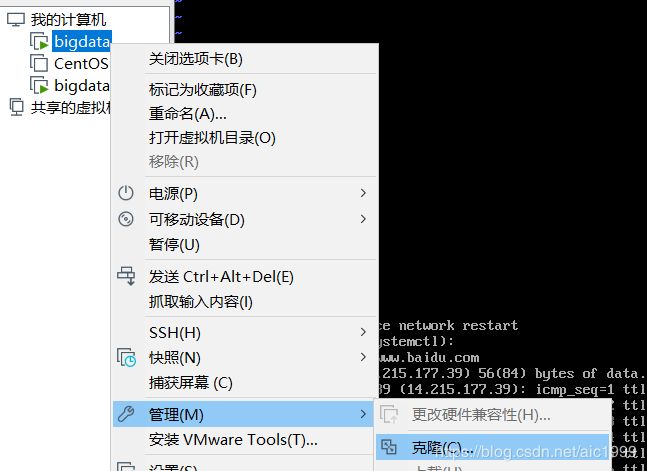
- 右键点击(已关机的)主机。
- 点击“管理”,然后点击“克隆”
- 注意克隆方法选择“创建完整克隆”,其余的跟着提示走,在此不赘述。
3.2、为克隆节点配置网络
- 输入下面的指令,并且按'i'进入编辑模式。
vi /etc/sysconfig/network-scripts/ifcfg-eth0
- 修改IPADDR的值,第四个数值不能和被克隆的机器一样,仍然建议数值为100~500。
- 删除UUID和HWADDR(如果没有就不用管),按“esc”键后,输入‘:wq’回车,保存退出即可。
- 删除文件‘ 70-persistent-net.rules ’,指令如下。
rm -rf /etc/udev/rules.d/70-persistent-net.rules
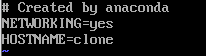
- 修改机器名,指令如下。
vi /etc/sysconfig/network
- 进入编辑模式以后,添加/修改一行:HOSTNAME=xxx(自命名)
- 然后保存退出即可。
3.3、重新启动克隆机
输入‘init 6’指令即可。
3.4、修改主机的host文件
- 目的:绑定了机器和它的IP地址,方便以后直接通过名字找到机器。
- 重新将主机开机。
vi /etc/hosts
- 进入编辑模式,添加两行信息。
- 格式如下:机器的IP地址(即机器对应的IPADDR值)(空格) 机器的别名。
![]()
- 保存退出。
3.5、修改从机的host文件
- 重启从机,剩下方法与上述3.4方法一致,不赘述。
3.6、测试主从机的连通性
在主机输入以下指令。
ping 自己设置的从机名
如果联通了,就可以了。

4、关闭防火墙
- 不关闭防火墙的话,后续就算搭建好环境,我们也无法通过web页面访问Hadoop服务的端口50070。
- 下面是检查防火墙是否开启的指令:
firewall-cmd --state
![]()
- 如果centos的防火墙开了,选择以下指令关闭即可。
systemctl stop firewalld.service

- 重启后生效指令
chkconfig iptables off
- 立刻生效,重启无效指令
service iptables stop
5、链接xshell
- 目的是为了更方便地操纵linux。
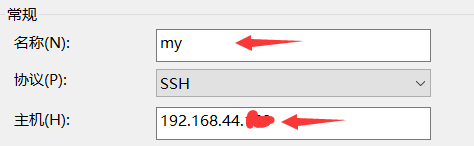
- 打开xshell,新建会话,修改名称、主机IP,点击确认。
- 打开会话时,用户名填"root",密码填主机的密码即可连接。(也可以在新建会话的时候点击左侧“用户身份验证”,输入用户名和密码信息)
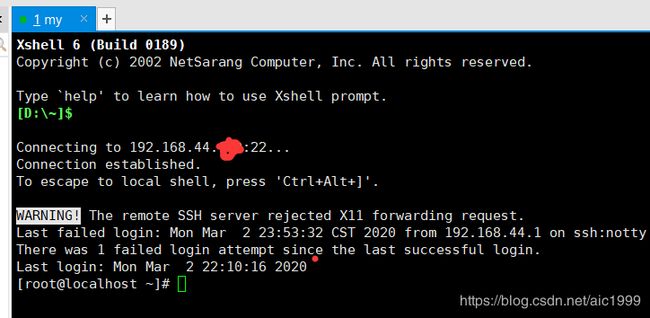
- 这时就可以在xshell里操作了。
- 从机也是同样操作
6、SSH免密码登录
- 当主机操作从机的时候,往往需要输入密码,这个步骤太麻烦了,利用SSH免密码登录即可。
6.1、生成密钥
- 在xshell中连接好主机从机后,直接在主机和从机里,赋值粘贴以下命令(也可以在vmware上输入命令,就是不方便而已)。
ssh-keygen -t rsa -P ''
- 注意,ssh-keygen之间没有空格。
- 中途会问保存的路径,直接点确认就行。
- 这时候密钥,ssh文件已经生成了。
- 输入以下指令,可以看到ssh文件中的其他东西。
cd .ssh
ls -la
- ls -l看不到隐藏文件,因此用ls -la命令。
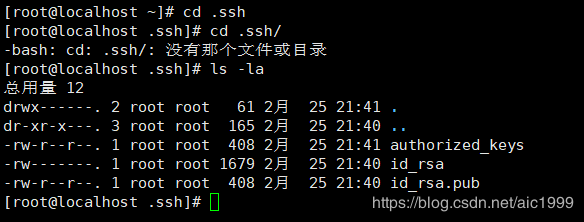
- 其中,"id_rsa.pub"文件是公钥,我们需要把公钥交给从机。公钥相当于身份证,给从机用来识别主机的身份。
6.2、移送公钥
- 利用远程拷贝命令,将公钥交给从机
scp id_rsa.pub [email protected]:~
- 这个xx请根据自己机器的IP地址数值填写。
- ~代表根,意思就是拷贝到从机的根目录下。
6.3、将公钥添加进信任列表
- 在从机中执行移动操作,将公钥放到可信任列表中。
cat id_rsa.pub>>.ssh/authorized_keys
6.4、测试是否连通
- 这时候主从机就相当于一台电脑了,我们可以免密码进从机操作。
- 在主机执行命令连接从机
ssh 自己从机的别名
![]()
- 可以看到的确成功了。
6.5、补充
- 如果使用了企业提供的服务器,例如腾讯云阿里云之类的,还需要更改其他配置,具体的多看服务器提供方的官方文档,以后接触了再说。
7、安装java jdk
注意,所有节点都需要配置jdk。
7.1、安装java jdk的rpm文件
- 点击打开xshell的xftp文件传输服务。(直接打开xftp软件新建对话也行)。
- 进入主机的/opt/software路径下。(直接放到根目录下也行,但不方便文件管理)
- 找到左侧本地已下载好的java,直接拖到右边即可。
- 然后打开xshell,输入以下命令。
- 先进入/opt/software。
cd /opt/software
- 然后再安装。
rpm -ivh 自己的jdk的文件名.rpm
- 可以看到安装成功。

7.2、配置环境变量
- 通过修改home目录下的隐藏文件.bash_profile(放环境变量的地方)来修改环境变量。我们设置JAVA_ HOME指向JDK的根目录,然后再使环境变量立刻生效。
- 先回到根目录
cd ~
- 在根目录下,再通过vi命令,按“i”进入.bash_profile文件的编辑模式。
题外话:用export命令配置环境变量也行
vi .bash_profile
![]()
- 编辑配置环境变量(如下图所示),编辑完后按“:wq”保存退出。
JAVA_HOME=/usr/java/jdk1.7.0_79
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin

- 保存退出回到根目录后,再执行source命令,修改环境变量之后立即生效
source .bash_profile
这时候再执行‘java -version’,可以看到java已经安装好了。

8、安装Hadoop
8.1、解压Hadoop
- 通过xshell上传hadoop的压缩包到虚拟机的/opt/software路径下。
- 利用解压命令tar,解压。
cd /opt/software
tar -zxvf hadoop的版本名.tar.gz
![]()
8.2、配置环境变量
- 把hadoop的bin和sbin配置到环境变量中。
- bin当中是常规命令,而sbin当中是管理命令。
- 和配置jdk一样的步骤,在根目录下,进入.bash_profile文件,编辑它。
![]()

HADOOP_HOME=/opt/software/hadoop-2.7.0
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 再执行source命令,修改环境变量之后立即生效
source .bash_profile
8.3、让hadoop找到jdk
- 这一步是必须的,hadoop是用java开发的,因此它需要jdk的jre环境,否则无法运行,会出错,例如下图。所以我们要在hadoop文件中重新配置jdk的路径信息,让hadoop找到jdk。
![]()
- 首先在根目录下进入以下路径,找到hadoop-env.sh这个文件,编辑它。
cd /opt/software/hadoop-2.7.0/etc/hadoop
vi hadoop-env.sh
- 找到这一行

- 修改它,将java的安装目录放进去,然后保存退出。
/usr/java/自己jdk的名字
- 记得':wq'保存退出。
8.4、测试hadoop是否已成功安装
- 直接执行查看版本号,可以看到已经安装成功了。
hadoop version

9、Hadoop分布式安装
- HDFS是hadoop的分布式文件系统,相当于一个将很多个电脑串起来的大硬盘。
- 一共支持三种模式,这里先用伪分布式。
- 本地(单节点)模式:本机一台电脑,不存在分布式的概念。(一般不用)
- 伪分布式模式:也是在本机上,但用了分布式的概念,构成了集群。(个人学习用)
- 完全分布式模式:多台电脑。(实际项目中用)
9.1、伪分布式安装
9.1.1、配置HDFS
- 在这里安装伪分布式的,根据官网提示,修改/etc/hadoop下的core-site.xml文件。

- 找到这一行。
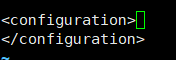
- 添加信息进去,保存退出。
fs.defaultFS
hdfs://localhost:9000
- core-site.xml文件主要配置了访问Hadoop集群的主要信息, 9000代表端口。 外部通过配置的hdfs: //主机IP: 9000, 就可以找到Hadoop集群。
- 同样的,找到/etc/hadoop下的hdfs-site.xml文件,修改它,修改完后保存退出。
vi core-site.xml
- 其中dfs.replication代表副本数,这里设置为1。
dfs.replication
1
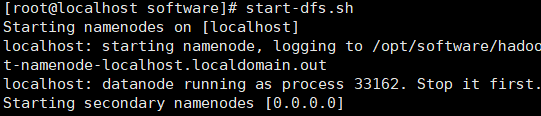
9.1.2、格式化并启动namenode
- 格式化的目的是为了初始化。
hdfs namenode -format
start-dfs.sh
如果中途出现输密码提示和Warnning,一般是因为公钥没有在可信任列表里(如果没有密钥就生成吧)。和之前的生成密钥教程一样,去到.ssh文件夹下,要用cat命令将密钥放进去,如下图。
- 可以看到执行成功了。
- 执行‘jps’命令查看当前java进程信息,会发现有namednode了。
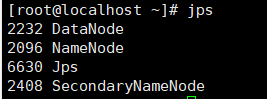
9.1.3、用web页面查看HDFS
- 在浏览器地址栏内输入网址:
192.168.xx.xxx:50070/
- 可以看到伪分布式的HDFS的确搭建起来了。
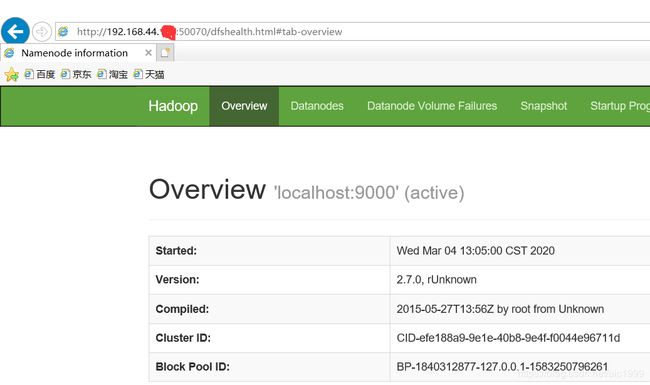
如果发现无法访问,换一个浏览器即可,比如我的IE浏览器可以访问,但是Edge浏览器则不行。
- 自此,所有东西都配置好了,以后每一次要重新启用服务,只需要运行namenode即可。(记得检查防火墙是否运行,防火墙若还在运行,则打不开)
start-dfs.sh9.2、完全分布式安装
9.2.1 填写xml配置信息
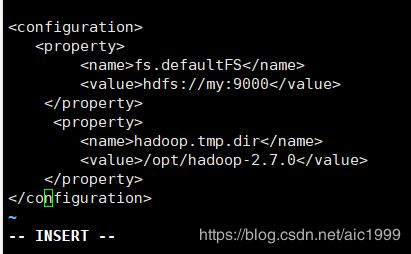
- 在伪分布式配置的基础上,在core-site.xml文件中添加下面语句即可(localhost最好换成自己的主机名,如下,我将localhost换成了my)。
hadoop.tmp.dir
/opt/hadoop-2.7.0
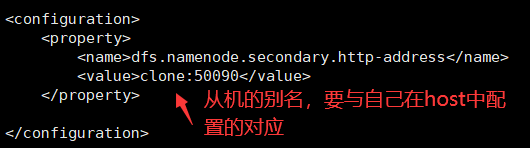
- 同样的,在hdfs-site.xml文件中如下修改。
9.2.2、生成节点文件
- 进入路径
cd /opt/software/hadoop-2.7.0/etc/hadoop
- 利用touch命令创建/修改文件
- 你的主节点(主机)和数据节点(从机)叫什么名字,就创建什么名字的文件,例如我在主机里执行了这条指令:"touch my"和“touch clone”。
touch xxx
- 修改文件,其中与主机同名的文件里面写个主机的名字即可。其余从机要写两行数据,主机名和自己的名字,如下。
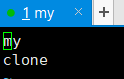
9.2.3、格式化并启动namenode
- 记得检查防火墙是否处于关闭状态。
hdfs namenode -format
start-dfs.sh
9.2.4、用web页面查看HDFS
- 在浏览器地址栏内输入网址,能打开
192.168.xx.xxx:50070/