【文末抽书】Java设计模式--单例模式

来源 :投稿 | 作者 : gyl-coder|原文:阅读原文
在介绍单例模式之前,我们先了解一下,什么是设计模式?
设计模式(Design Pattern):是一套被反复使用,多数人知晓的,经过分类编目的,代码设计经验的总结。
目的:使用设计模式是为了可重用性代码,让代码更容易被他人理解,保证代码可靠性。
本文将会用到的关键词:
单例:Singleton
实例:instance
同步:synchronized
类装载器:ClassLoader
单例模式:
单例,顾名思义就是只能有一个、不能再出现第二个。就如同地球上没有两片一模一样的树叶一样。
在这里就是说:一个类只能有一个实例,并且整个项目系统都能访问该实例。
单例模式共分为两大类:
懒汉模式:实例在第一次使用时创建
饿汉模式:实例在类装载时创建
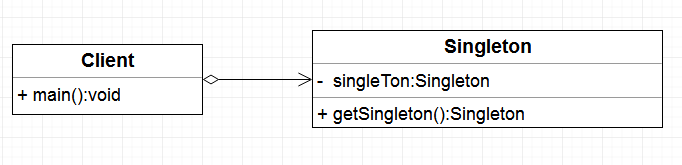
单例模式UML图
饿汉模式
按照定义我们可以写出一个基本代码:
public class Singleton {
// 使用private将构造方法私有化,以防外界通过该构造方法创建多个实例
private Singleton() {
}
// 由于不能使用构造方法创建实例,所以需要在类的内部创建该类的唯一实例
// 使用static修饰singleton 在外界可以通过类名调用该实例 类名.成员名
static Singleton singleton = new Singleton(); // 1
// 如果使用private封装该实例,则需要添加get方法实现对外界的开放
private static Singleton instance = new Singleton(); // 2
// 添加static,将该方法变成类所有 通过类名访问
public static Singleton getInstance(){
return instance;
}
//1和2选一种即可,推荐2
}对于饿汉模式来说,这种写法已经很‘perfect’了,唯一的缺点就是,由于instance的初始化是在类加载时进行的,类加载是由ClassLoader来实现的,如果初始化太早,就会造成资源浪费。
当然,如果所需的单例占用的资源很少,并且也不依赖于其他数据,那么这种实现方式也是很好的。
类装载的时机:
new一个对象时
使用反射创建它的实例时
子类被加载时,如果父类还没有加载,就先加载父类
JVM启动时执行主类 会先被加载
懒汉模式
懒汉模式的代码如下
// 代码一
public class Singleton {
private static Singleton instance = null;
private Singleton(){
}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}每次获取instance之前先进行判断,如果instance为空就new一个出来,否则就直接返回已存在的instance。
这种写法在单线程的时候是没问题的。但是,当有多个线程一起工作的时候,如果有两个线程同时运行到 if (instance == null),都判断为null(第一个线程判断为空之后,并没有继续向下执行,当第二个线程判断的时候instance依然为空),最终两个线程就各自会创建一个实例出来。这样就破环了单例模式 实例的唯一性
要想保证实例的唯一性就需要使用synchronized,加上一个同步锁
// 代码二
public class Singleton {
private static Singleton instance = null;
private Singleton() {}
public static Singleton getInstance() {
synchronized(Singleton.class){
if (instance == null)
instance = new Singleton();
}
return instance;
}
}加上synchronized关键字之后,getInstance方法就会锁上了。如果有两个线程(T1、T2)同时执行到这个方法时,会有其中一个线程T1获得同步锁,得以继续执行,而另一个线程T2则需要等待,当第T1执行完毕getInstance之后(完成了null判断、对象创建、获得返回值之后),T2线程才会执行执行。
所以这段代码也就避免了代码一中,可能出现因为多线程导致多个实例的情况。但是,这种写法也有一个问题:给getInstance方法加锁,虽然避免了可能会出现的多个实例问题,但是会强制除T1之外的所有线程等待,实际上会对程序的执行效率造成负面影响。
双重检查(Double-Check)
代码二相对于代码一的效率问题,其实是为了解决1%几率的问题,而使用了一个100%出现的防护盾。那有一个优化的思路,就是把100%出现的防护盾,也改为1%的几率出现,使之只出现在可能会导致多个实例出现的地方。
代码如下:
// 代码三
public class Singleton {
private static Singleton instance = null;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null){
synchronized(Singleton.class){
if (instance == null)
instance = new Singleton();
}
}
return instance;
}
}这段代码看起来有点复杂,注意其中有两次if(instance==null)的判断,这个叫做『双重检查 Double-Check』。
第一个 if(instance==null),其实是为了解决代码二中的效率问题,只有instance为null的时候,才进入synchronized的代码段大大减少了几率。
第二个if(instance==null),则是跟代码二一样,是为了防止可能出现多个实例的情况。
这段代码看起来已经完美无瑕了。当然,只是『看起来』,还是有小概率出现问题的。想要充分理解需要先弄清楚以下几个概念:原子操作、指令重排。
原子操作
简单来说,原子操作(atomic)就是不可分割的操作,在计算机中,就是指不会因为线程调度被打断的操作。比如,简单的赋值是一个原子操作:
m = 6; // 这是个原子操作假如m原先的值为0,那么对于这个操作,要么执行成功m变成了6,要么是没执行 m还是0,而不会出现诸如m=3这种中间态——即使是在并发的线程中。
但是,声明并赋值就不是一个原子操作:
int n=6;//这不是一个原子操作对于这个语句,至少有两个操作:①声明一个变量n ②给n赋值为6——这样就会有一个中间状态:变量n已经被声明了但是还没有被赋值的状态。这样,在多线程中,由于线程执行顺序的不确定性,如果两个线程都使用m,就可能会导致不稳定的结果出现。
指令重排
简单来说,就是计算机为了提高执行效率,会做的一些优化,在不影响最终结果的情况下,可能会对一些语句的执行顺序进行调整。比如,这一段代码:
int a ; // 语句1
a = 8 ; // 语句2
int b = 9 ; // 语句3
int c = a + b ; // 语句4正常来说,对于顺序结构,执行的顺序是自上到下,也即1234。但是,由于指令重排
的原因,因为不影响最终的结果,所以,实际执行的顺序可能会变成3124或者1324。
由于语句3和4没有原子性的问题,语句3和语句4也可能会拆分成原子操作,再重排。——也就是说,对于非原子性的操作,在不影响最终结果的情况下,其拆分成的原子操作可能会被重新排列执行顺序。
OK,了解了原子操作和指令重排的概念之后,我们再继续看代码三的问题。
主要在于singleton = new Singleton()这句,这并非是一个原子操作,事实上在 JVM 中这句话大概做了下面 3 件事情。
1. 给 singleton 分配内存
2. 调用 Singleton 的构造函数来初始化成员变量,形成实例
3. 将singleton对象指向分配的内存空间(执行完这步 singleton才是非 null了)
在JVM的即时编译器中存在指令重排序的优化。
也就是说上面的第二步和第三步的顺序是不能保证的,最终的执行顺序可能是 1-2-3 也可能是 1-3-2。如果是后者,则在 3 执行完毕、2 未执行之前,被线程二抢占了,这时 instance 已经是非 null 了(但却没有初始化),所以线程二会直接返回 instance,然后使用,然后顺理成章地报错。
再稍微解释一下,就是说,由于有一个『instance已经不为null但是仍没有完成初始化』的中间状态,而这个时候,如果有其他线程刚好运行到第一层if (instance ==null)这里,这里读取到的instance已经不为null了,所以就直接把这个中间状态的instance拿去用了,就会产生问题。这里的关键在于线程T1对instance的写操作没有完成,线程T2就执行了读操作。
对于代码三出现的问题,解决方案为:给instance的声明加上volatile关键字
代码如下:
public class Singleton {
private static volatile Singleton instance = null;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null){
synchronized(Singleton.class){
if (instance == null)
instance = new Singleton();
}
}
return instance;
}
}volatile关键字的一个作用是禁止指令重排,把instance声明为volatile之后,对它的写操作就会有一个内存屏障,这样,在它的赋值完成之前,就不用会调用读操作。
注意:volatile阻止的不是singleton = new Singleton()这句话内部[1-2-3]的指令重排,而是保证了在一个写操作([1-2-3])完成之前,不会调用读操作(if (instance == null))。
其它方法
静态内部类
public class Singleton {
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
private Singleton (){}
public static final Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}这种写法的巧妙之处在于:对于内部类SingletonHolder,它是一个饿汉式的单例实现,在SingletonHolder初始化的时候会由ClassLoader来保证同步,使INSTANCE是一个真单例。
同时,由于SingletonHolder是一个内部类,只在外部类的Singleton的getInstance()中被使用,所以它被加载的时机也就是在getInstance()方法第一次被调用的时候。
它利用了ClassLoader来保证了同步,同时又能让开发者控制类加载的时机。从内部看是一个饿汉式的单例,但是从外部看来,又的确是懒汉式的实现
枚举
public enum SingleInstance {
INSTANCE;
public void fun1() {
// do something
}
}// 使用SingleInstance.INSTANCE.fun1();是不是很简单?而且因为自动序列化机制,保证了线程的绝对安全。三个词概括该方式:简单、高效、安全
这种写法在功能上与共有域方法相近,但是它更简洁,无偿地提供了序列化机制,绝对防止对此实例化,即使是在面对复杂的序列化或者反射攻击的时候。虽然这中方法还没有广泛采用,但是单元素的枚举类型已经成为实现Singleton的最佳方法。
文末福利:
内容提要:
《可伸缩服务架构:框架与中间件》以高可用服务架构为主题,侧重于讲解高可用架构设计的核心要点:可伸缩和可扩展,从应用层、数据库、缓存、消息队列、大数据查询系统、分布式定时任务调度系统、微服务等层面详细讲解如何设计可伸缩、可扩展的框架,并给出在各个领域解决特定问题的方法论和实践总结。随着《可伸缩服务架构:框架与中间件》的出版,我们还开源了4个行之有效的互联网可伸缩框架,包括数据库分库分表dbsplit、缓存分片redic、专业的发号器vesta和消息队列处理机框架kclient,每个框架都开箱即用,也可以作为学习互联网平台化框架搭建的素材,更可以作为开发开源项目的示例。
《可伸缩服务架构:框架与中间件》的上册《分布式服务架构:原理、设计与实战》详细介绍了如何解决线上高并发服务的一致性、高性能、高可用、敏捷等痛点,《可伸缩服务架构:框架与中间件》与上册结合后可覆盖保证线上高并发服务的各个主题:一致性、高性能、高可用、可伸缩、可扩展、敏捷性等,每个主题都是一个方法论。充分理解这些主题,可保障线上服务健壮运行,对实现服务稳定性的n个9有着不可估量的作用。
无论是对于互联网的或者传统的软件工程师、测试工程师、架构师,还是对于深耕于IT的其他管理人员,《可伸缩服务架构:框架与中间件》都有很强的借鉴性和参考价值,是值得每个技术人员阅读的架构级技术书。
目录
第1章 如何设计一款永不重复的高性能分布式发号器 1
1.1 可选方案及技术选型 2
1.1.1 为什么不用UUID 2
1.1.2 基于数据库的实现方案 2
1.1.3 Snowflake开源项目 3
1.1.4 小结 4
1.2 分布式系统对发号器的基本需求 4
1.3 架构设计与核心要点 6
1.3.1 发布模式 6
1.3.2 ID类型 7
1.3.3 数据结构 7
1.3.4 并发 9
1.3.5 机器ID的分配 9
1.3.6 时间同步 10
1.3.7 设计验证 11
1.4 如何根据设计实现多场景的发号器 11
1.4.1 项目结构 12
1.4.2 服务接口的定义 14
1.4.3 服务接口的实现 15
1.4.4 ID元数据与长整型ID的互相转换 22
1.4.5 时间操作 25
1.4.6 机器ID的生成 27
1.4.7 小结 32
1.5 如何保证性能需求 32
1.5.1 嵌入发布模式的压测结果 33
1.5.2 中心服务器发布模式的压测结果 33
1.5.3 REST发布模式(Netty实现)的压测结果 33
1.5.4 REST发布模式(Spring Boot + Tomcat实现)的压测结果 34
1.5.5 性能测试总结 34
1.6 如何让用户快速使用 35
1.6.1 REST发布模式的使用指南 35
1.6.2 服务化模式的使用指南 38
1.6.3 嵌入发布模式的使用指南 41
1.7 为用户提供API文档 43
1.7.1 RESTful API文档 44
1.7.2 Java API文档 45
第2章 可灵活扩展的消息队列框架的设计与实现 49
2.1 背景介绍 50
2.2 项目目标 50
2.2.1 简单易用 50
2.2.2 高性能 51
2.2.3 高稳定性 51
2.3 架构难点 51
2.3.1 线程模型 51
2.3.2 异常处理 53
2.3.3 优雅关机 53
2.4 设计与实现 54
2.4.1 项目结构 54
2.4.2 项目包的规划 55
2.4.3 生产者的设计与实现 57
2.4.4 消费者的设计与实现 58
2.4.5 启动模块的设计与实现 67
2.4.6 消息处理器的体系结构 76
2.4.7 反射机制 79
2.4.8 模板项目的设计 80
2.5 使用指南 82
2.5.1 安装步骤 82
2.5.2 Java API 83
2.5.3 与Spring环境集成 84
2.5.4 对服务源码进行注解 85
2.6 API简介 87
2.6.1 Producer API 87
2.6.2 Consumer API 88
2.6.3 消息处理器 88
2.6.4 消息处理器定义的注解 90
2.7 消息处理机模板项目 91
2.7.1 快速开发向导 91
2.7.2 后台监控和管理 92
第3章 轻量级的数据库分库分表架构与框架 93
3.1 什么是分库分表 94
3.1.1 使用数据库的三个阶段 94
3.1.2 在什么情况下需要分库分表 95
3.1.3 分库分表的典型实例 96
3.2 三种分而治之的解决方案 97
3.2.1 客户端分片 97
3.2.2 代理分片 100
3.2.3 支持事务的分布式数据库 101
3.3 分库分表的架构设计 102
3.3.1 整体的切分方式 102
3.3.2 水平切分方式的路由过程和分片维度 106
3.3.3 分片后的事务处理机制 107
3.3.4 读写分离 119
3.3.5 分库分表引起的问题 119
3.4 流行代理分片框架Mycat的初体验 123
3.4.1 安装Mycat 123
3.4.2 配置Mycat 124
3.4.3 配置数据库节点 128
3.4.4 数据迁移 129
3.4.5 Mycat支持的分片规则 129
3.5 流行的客户端分片框架Sharding JDBC的初体验 138
3.5.1 Sharding JDBC简介 138
3.5.2 Sharding JDBC的功能 139
3.5.3 Sharding JDBC的使用 141
3.5.4 Sharding JDBC的使用限制 152
3.6 自研客户端分片框架dbsplit的设计、实现与使用 153
3.6.1 项目结构 154
3.6.2 包结构和执行流程 155
3.6.3 切片下标命名策略 159
3.6.4 SQL解析和组装 167
3.6.5 SQL实用程序 168
3.6.6 反射实用程序 173
3.6.7 分片规则的配置 177
3.6.8 支持分片的SplitJdbcTemplate和SimpleSplitJdbcTemplate接口API 179
3.6.9 JdbcTemplate的扩展SimpleJdbcTemplate接口API 184
3.6.10 用于创建分库分表数据库的脚本工具 187
3.6.11 使用dbsplit的一个简单示例 192
3.6.12 使用dbsplit的线上真实示例展示 199
第4章 缓存的本质和缓存使用的优秀实践 201
4.1 使用缓存的目的和问题 202
4.2 自相似,CPU的缓存和系统架构的缓存 203
4.2.1 CPU缓存的架构及性能 205
4.2.2 CPU缓存的运行过程分析 206
4.2.3 缓存行与伪共享 208
4.2.4 从CPU的体系架构到分布式的缓存架构 218
4.3 常用的分布式缓存解决方案 221
4.3.1 常用的分布式缓存的对比 221
4.3.2 Redis初体验 225
4.4 分布式缓存的通用方法 229
4.4.1 缓存编程的具体方法 229
4.4.2 应用层访问缓存的模式 233
4.4.3 分布式缓存分片的三种模式 235
4.4.4 分布式缓存的迁移方案 238
4.4.5 缓存穿透、缓存并发和缓存雪崩 244
4.4.6 缓存对事务的支持 246
4.5 分布式缓存的设计与案例 248
4.5.1 缓存设计的核心要素 248
4.5.2 缓存设计的优秀实践 250
4.5.3 关于常见的缓存线上问题的案例 253
4.6 客户端缓存分片框架redic的设计与实现 257
4.6.1 什么时候需要redic 258
4.6.2 如何使用redic 258
4.6.3 更多的配置 258
4.6.4 项目结构 260
4.6.5 包结构 261
4.6.6 设计与实现的过程 261
第5章 大数据利器之Elasticsearch 268
5.1 Lucene简介 269
5.1.1 核心模块 269
5.1.2 核心术语 270
5.1.3 检索方式 271
5.1.4 分段存储 273
5.1.5 段合并策略 275
5.1.6 Lucene相似度打分 278
5.2 Elasticsearch简介 286
5.2.1 核心概念 286
5.2.2 3C和脑裂 289
5.2.3 事务日志 291
5.2.4 在集群中写索引 294
5.2.5 集群中的查询流程 295
5.3 Elasticsearch实战 298
5.3.1 Elasticsearch的配置说明 298
5.3.2 常用的接口 300
5.4 性能调优 305
5.4.1 写优化 305
5.4.2 读优化 308
5.4.3 堆大小的设置 313
5.4.4 服务器配置的选择 315
5.4.5 硬盘的选择和设置 316
5.4.6 接入方式 318
5.4.7 角色隔离和脑裂 319
第6章 全面揭秘分布式定时任务 321
6.1 什么是定时任务 322
6.2 分布式定时任务 341
6.2.1 定时任务的使用场景 342
6.2.2 传统定时任务存在的问题 342
6.2.3 分布式定时任务及其原理 344
6.3 开源分布式定时任务的用法 347
6.3.1 Quartz的分布式模式 347
6.3.2 TBSchedule 356
6.3.3 Elastic-Job 365
第7章 RPC服务的发展历程和对比分析 377
7.1 什么是RPC服务 378
7.2 RPC服务的原理 379
7.2.1 Sokcet套接字 379
7.2.2 RPC的调用过程 380
7.3 在程序中使用RPC服务 382
7.4 RPC服务的发展历程 383
7.4.1 第一代RPC:以ONC RPC和DCE RPC为代表的函数式RPC 384
7.4.2 第二代RPC:支持面对象的编程 388
7.4.3 第三代RPC:SOA和微服务 398
7.4.4 架构的演进 402
7.5 主流的RPC框架 403
7.5.1 Thrift 403
7.5.2 ZeroC Ice 410
7.5.3 gRPC 418
7.5.4 Dubbo 430
第8章 Dubbo实战及源码分析 436
8.1 Dubbo的四种配置方式 437
8.1.1 XML配置 437
8.1.2 属性配置 440
8.1.3 API配置 441
8.1.4 注解配置 443
8.2 服务的注册与发现 446
8.2.1 注册中心 446
8.2.2 服务暴露 449
8.2.3 引用服务 451
8.3 Dubbo通信协议及序列化探讨 455
8.3.1 Dubbo支持的协议 455
8.3.2 协议的配置方法 456
8.3.3 多协议暴露服务 457
8.3.4 Dubbo协议的使用注意事项 458
8.3.5 Dubbo协议的约束 459
8.4 Dubbo中高效的I/O线程模型 459
8.4.1 对Dubbo中I/O模型的分析 459
8.4.2 Dubbo中线程配置的相关参数 460
8.4.3 在Dubbo线程方面踩过的坑 461
8.4.4 对Dubbo中线程使用的建议 462
8.5 集群的容错机制与负载均衡 462
8.5.1 集群容错机制的原理 462
8.5.2 集群容错模式的配置方法 464
8.5.3 六种集群容错模式 464
8.5.4 集群的负载均衡 465
8.6 监控和运维实践 467
8.6.1 日志适配 467
8.6.2 监控管理后台 467
8.6.3 服务降级 473
8.6.4 优雅停机 475
8.6.5 灰度发布 475
8.7 Dubbo项目线上案例解析 477
8.7.1 线上问题的通用解决方案 477
8.7.2 耗时服务耗尽了线程池的案例 480
8.7.3 容错重试机制引发服务雪崩的案例 481
8.8 深入剖析Dubbo源码及其实现 483
8.8.1 Dubbo的总体架构设计 483
8.8.2 配置文件 486
8.8.3 Dubbo的核心RPC 488
8.8.4 Dubbo巧妙的URL总线设计 491
8.8.5 Dubbo的扩展点加载SPI 492
8.8.6 Dubbo服务暴露的过程 493
8.8.7 服务引用 502
8.8.8 集群容错和负载均衡 503
8.8.9 集群容错 504
8.8.10 负载均衡 509
第9章 高性能网络中间件 512
9.1 TCP/UDP的核心原理及本质探索 513
9.1.1 网络模型 513
9.1.2 UDP、IP及其未解决的问题 515
9.1.3 TCP详解 519
9.1.4 是否可以用UDP代替TCP 527
9.1.5 网络通信的不可靠性讨论 529
9.2 网络测试优秀实践 530
9.2.1 网络测试的关键点 530
9.2.2 那些必不可少的网络测试工具 532
9.2.3 典型的测试报告 539
9.3 高性能网络框架的设计与实现 544
9.3.1 对代理功能的测试及分析 545
9.3.2 网络中间件的使用介绍 549
9.3.3 内存和缓存的优化 551
9.3.4 快速解析流数据 554
支持作者直接购买

赠书说明:
活动对象:公众号读者
抽奖规则,长按小程序抽奖二维码参与即可
中奖后在抽奖小程序填写好收货信息
周一到周五都有抽书活动,每日书籍不一样,敬请期待
