说明:
项目主要爬取英语外教与中国老师招聘数据,并对数据进行比较分析。
外教的招聘信息(JobLeadChina网站):http://www.jobleadchina.com/job?job_industry=Teaching
中国老师的招聘信息(万行教师人才网站):http://www.job910.com/search.aspx
分为:爬虫+数据分析
一、爬虫【爬取外教和中国教师的招聘信息】
-->存入CSV 【有两种方法】
- 简单的with open方法
- 使用pandas进行保存csv文件
1、爬取英语外教的招聘信息(JobLeadChina网站)
import requests
from bs4 import BeautifulSoup
import os
import csv
import pandas as pd
class JobLeadChina(object):
def __init__(self):
self.headers={'user-agent':'Mozilla/5.0'}
self.base_url='http://www.jobleadchina.com/job?job_industry=Teaching'
self.flag=True #用于pandas写入csv文件时,加不加第一行的名字
def get_page(self,url):
try:
r=requests.get(url,headers=self.headers)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def get_pagenum(self): #基于self.base_url得到页数
html=self.get_page(self.base_url)
soup=BeautifulSoup(html,'html.parser')
ul=soup.find('ul',{'class':{'pagination'}})
pagenum=int(ul('li')[-2]('a')[0].text.strip())
return pagenum
def parse_page(self,url): #解析网页,并存入csv文件中
html=self.get_page(url)
soup=BeautifulSoup(html,'html.parser')
jobs=soup.find_all('div',{'class':{'jobThumbnail'}})
for job in jobs:
title=job.find('h3',{'class':{'positionTitle'}})('a')[0].text.strip()
link=job.find('h3',{'class':{'positionTitle'}})('a')[0]['href']
salary=job.find('h3',{'class':{'salaryRange'}}).text.strip()
company=job.find('h3',{'class':{'companyName'}})('a')[0].text.strip()
com_type=job.find('div',{'class':{'jobThumbnailCompanyIndustry'}})('span')[0].text.strip()
area=job.find('div',{'class':{'jobThumbnailCompanyIndustry'}})('span')[-1].text.strip()
update_time=job.find('div',{'class':{'timestamp'}})('span')[0].text.strip()
education=job.find('div',{'class':{'jobThumbnailPositionRequire'}})('span')[0].text.strip()
exp_title = job.find('div', {'class': {'jobThumbnailPositionRequire'}})('span')[2].text.strip()
#print(title,link,salary,company,com_type,area,update_time,education,exp_title)
filename = 'jobleadchina.csv' # 文件名
"""
#将数据存入csv文件中【方法1】
with open(filename,'a+',newline="",encoding='utf-8')as csv_f:
csv_write=csv.writer(csv_f)
if os.path.getsize(filename)==0:
csv_write.writerow(['title','link','salary','company','com_type','area','update_time','education','exp_title'])
csv_write.writerow([title,link,salary,company,com_type,area,update_time,education,exp_title])
"""
#将数据存入csv文件中【方法2】 --->使用pandas
info={'title':[title],'link':[link],'salary':[salary],'company':[company],'com_type':[com_type],'area':[area],'update_time':[update_time],'education':[education],'exp_title':[exp_title]}
data=pd.DataFrame(info)
data.to_csv(filename,index=False,mode='a+',header=self.flag)
self.flag=False
print('{}-Successfuly'.format(title))
def main(self):
page_num=self.get_pagenum()
for i in range(1,page_num+1):
url=self.base_url+"&page={}".format(i)
self.parse_page(url)
jobleadchina=JobLeadChina()
jobleadchina.main()
数据保存在:jobleadchina.csv文件中
2、爬取英语中国教师的招聘信息(万行教育人才网)
"""万行教育人才网
需要指定funtype和pageIndex
英语老师-幼儿园:http://www.job910.com/search.aspx?funtype=10&keyword=英语老师&pageSize=20&pageIndex=1
http://www.job910.com/search.aspx?funtype=10&keyword=英语老师&pageSize=20&pageIndex=2
...
http://www.job910.com/search.aspx?funtype=10&keyword=英语老师&pageSize=20&pageIndex=37
funtype=10 最大pageIndex=37
英语老师-中小学:http://www.job910.com/search.aspx?funtype=11&keyword=英语老师&pageSize=20&pageIndex=1
http://www.job910.com/search.aspx?funtype=11&keyword=英语老师&pageSize=20&pageIndex=2
...
http://www.job910.com/search.aspx?funtype=11&keyword=英语老师&pageSize=20&pageIndex=472
funtype=11 最大pageIndex=472
英语老师-职业院校:http://www.job910.com/search.aspx?funtype=13&keyword=英语老师&pageSize=20&pageIndex=1
http://www.job910.com/search.aspx?funtype=13&keyword=英语老师&pageSize=20&pageIndex=2
funtype=13 最大pageIndex=2
英语老师-外语培训:http://www.job910.com/search.aspx?funtype=19&keyword=英语老师&pageSize=20&pageIndex=1
http://www.job910.com/search.aspx?funtype=19&keyword=英语老师&pageSize=20&pageIndex=2
...
http://www.job910.com/search.aspx?funtype=19&keyword=英语老师&pageSize=20&pageIndex=53
funtype=19 最大pageIndex=53
"""
import requests
import os
import csv
import pandas as pd
from bs4 import BeautifulSoup
class Job910(object):
def __init__(self,funtype,pageIndex):
self.funtype=funtype
self.pageIndex=pageIndex
self.keyword='英语老师'
self.pageSize=20
self.base_url='http://www.job910.com/search.aspx'
self.headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400'}
self.flag=True #利用pandas将数据写入文件时,是否加第一行
def get_page(self,url,params=None):
try:
r=requests.get(url,headers=self.headers,params=params)
#print(r.url)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def parse_page(self,url,params=None):
html=self.get_page(url,params)
soup=BeautifulSoup(html,'html.parser')
lis=soup.find('ul',{'class':{'search-result-list'}})('li')
for li in lis:
title=li.find('div',{'class':{'position title'}})('a')[0].text.strip()
link='http://www.job910.com'+li.find('div',{'class':{'position title'}})('a')[0]['href']
area=li.find('div',{'class':{'area title2'}}).text.strip()
salary=li.find('div',{'class':{'salary title'}}).text.strip()
company=li.find('a',{'class':{'com title adclick'}}).text.strip()
update_time=li.find('div',{'class':{'time title2'}}).text.strip()
exp_title=li.find('div',{'class':{'exp title2'}}).text.strip()
#print(title,link,area,salary,company,update_time,exp_title)
filename_dict={
10:'幼儿园.csv',
11:'中小学.csv',
13:'职业院校.csv',
19:'外语培训.csv'
}
filename=filename_dict[self.funtype]
#保存到csv文件【方法1】
with open(filename,'a+',encoding='utf8',newline="")as csv_f:
csv_write=csv.writer(csv_f)
if os.path.getsize(filename)==0:
csv_write.writerow(['title','link','area','salary','company','update_time','exp_title'])
csv_write.writerow([title,link,area,salary,company,update_time,exp_title])
print('{}-successfully'.format(title))
"""
#保存到csv文件 ---->使用pandas保存数据
info={'title':[title],'link':[link],'area':[area],'salary':[salary],'company':[company],'update_time':[update_time],'exp_title':[exp_title]}
data=pd.DataFrame(info)
data.to_csv(filename,index=False,mode='a+',header=self.flag)
self.flag=False #之后csv文件就不加标题
"""
def main(self):
for i in range(1,self.pageIndex+1):
try:
print('开始爬取第{}页'.format(i))
params={'funtype':self.funtype,'keyword':self.keyword,'pageSize':self.pageSize,'pageIndex':i}
self.parse_page(self.base_url,params)
except:
print('爬取第{}页失败'.format(i))
continue
job_yey=Job910(10,19) #幼儿园的英语老师
job_yey.main()
job_zxx=Job910(11,472) #中小学的英语老师
job_zxx.main()
job_zyyx=Job910(13,2) #职业院校的英语老师
job_zyyx.main()
job_wypx=Job910(19,53) #外语培训的英语老师
job_wypx.main()
数据保存在:幼儿园.csv、中小学.csv、外语培训.csv、职业院校.csv
二、数据分析【对比英语外教和中国教师招聘信息(薪资、经验、学历.....)】
采用:Jupyter notebook代码,对招聘进行分析
导入的基础库:
import re
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('ggplot')
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei'] #解决seaborn中文字体显示问题
plt.rc('figure',figsize=(10,10)) #把plt默认的图片size调大一点
plt.rcParams['figure.dpi']=mpl.rcParams['axes.unicode_minus']=False
%matplotlib inline
导入数据:
data_yey=pd.read_csv('幼儿园.csv')
data_zxx=pd.read_csv('中小学.csv')
data_zyyx=pd.read_csv('职业院校.csv')
data_wypx=pd.read_csv('外语培训.csv')
data_jlc=pd.read_csv('jobleadchina.csv')
#把来自万行教师的四个数据集组合成一个DataFrame data_yey['type']='幼儿园' data_zxx['type']='中小学' data_zyyx['type']='职业院校' data_wypx['type']='外语培训' data_wx=pd.concat([data_yey,data_zxx,data_zyyx,data_wypx]) data_wx.shape #(11103, 8)
数据清洗:
(1)对来自万兴教师的数据进行清洗:省份、城市、经验、学历、工资
#清洗出省份、城市 #data_wx['area'].head(5) 省-市-区 或 省-市 data_wx['province']=data_wx['area'].str.split('-',expand=True)[0] #省 data_wx['city']=data_wx['area'].str.split('-',expand=True)[1] #市 #把北京、天津、上海、重庆的城市改为原来的名字 data_wx.loc[data_wx['province']=='北京','city']='北京' data_wx.loc[data_wx['province']=='天津','city']='天津' data_wx.loc[data_wx['province']=='上海','city']='上海' data_wx.loc[data_wx['province']=='重庆','city']='重庆'
#清洗出经验、学历 #data_wx['exp_title].head(5) 经验/学历 应届毕业生/大专以上 data_wx['exp']=data_wx['exp_title'].str.split('/',expand=True)[0] #经验 data_wx['degree']=data_wx['exp_title'].str.split('/',expand=True)[1] #学历 data_wx['exp'].unique() """ array([ '在读学生', '应届毕业生','不限', '一年以上', '两年以上', '三年以上', '四年以上','五年以上', '六年以上', '七年以上', '八年以上', '九年以上','十年以上'], dtype=object) """ exp_map={'在读学生':'经验不限','应届毕业生':'经验不限','不限':'经验不限','一年以上':'一到三年','两年以上':'一到三年', '三年以上':'三到五年','四年以上':'三到五年','五年以上':'五到十年','六年以上':'五到十年','七年以上':'五到十年', '八年以上':'五到十年','九年以上':'五到十年','十年以上':'十年以上'} data_wx['exp']=data_wx['exp'].map(exp_map) data_wx['exp'].unique() #array(['经验不限', '一到三年', '三到五年', '五到十年', '十年以上'], dtype=object) data_wx['degree'].unique() """ array(['大专', '大学本科以上', '大专以上', '不限', '中专以上', '大学本科', '不限以上', '硕士', '硕士以上', '高中以上', '职高 ', '中专'], dtype=object) """ degree_map={'大专':'大专','大学本科以上':'本科','大专以上':'大专','不限':'学历不限','中专以上':'中专','大学本科':'本科', '不限以上':'学历不限','硕士':'硕士','硕士以上':'硕士','高中以上':'高中','职高':'高中','中专':'中专'} data_wx['degree']=data_wx['degree'].map(degree_map) data_wx['degree'].unique() #array(['大专', '本科', '学历不限', '中专', '硕士', '高中', nan], dtype=object)
#清洗出工资
#data_wx['salary'].sample(5) #6K-8K/月 5W-8W/年 面议 '享公办教师薪资待遇'
def get_salary(data):
pat_K=r"(.*?)K-(.*?)K"
pat_W=r"(.*?)W-(.*?)W"
pat=r"(.*?)-(.*?)/"
if '面议' in data:
return np.nan
elif '享公办教师薪资待遇' in data:
return np.nan
elif 'K' in data and '月' in data:
low,high=re.findall(pattern=pat_K,string=data)[0]
return (float(low)+float(high))/2
elif 'W' in data and '年' in data:
low,high=re.findall(pattern=pat_W,string=data)[0]
return (float(low)+float(high))/2
else:
low,high=re.findall(pattern=pat,string=data)[0]
return (float(low)+float(high))/2
data_wx['salary_clean']=data_wx['salary'].apply(get_salary)
data_wx['salary_clean']=np.round(data_wx['salary_clean'],1)
data_wx=data_wx.drop(columns=['area','exp_title','salary'])
data_wx.drop(data_wx[data_wx['salary_clean']>40].index,inplace=True)
data_wx.columns
"""
Index(['title', 'link', 'company', 'update_time', 'type', 'province', 'city',
'exp', 'degree', 'salary_clean'],
dtype='object')
"""
(2)对来JobLeadChina数据进行清洗:exp_title和salary
#清洗出 exp_title
#data_jlc['exp_title'] #Experience: Executive
data_jlc['exp_title_clean']=data_jlc['exp_title'].str.split(': ',expand=True)[1]
data_jlc['exp_title_clean'].unique()
"""
array(['Executive', 'Mid-Senior Level', 'Entry Level', 'Internship',
'Associate', 'Director'], dtype=object)
"""
#清洗出 salary
#data_jlc['salary'].unique() 16K/MTH - 22K/MTH
def get_salary_jlc(data):
pat_jlc=r"(.*?)K/MTH - (.*?)K/MTH"
if "00" in data:
low,high=re.findall(pattern=pat_jlc,string=data)[0]
return (float(low)+float(high))/2/1000
else:
low,high=re.findall(pattern=pat_jlc,string=data)[0]
return (float(low)+float(high))/2
data_jlc['salary_clean']=data_jlc['salary'].apply(get_salary_jlc)
data_jlc=data_jlc.drop(columns=['exp_title','salary'])
data_jlc.columns
"""
Index(['area', 'com_type', 'company', 'education', 'link', 'title',
'update_time', 'exp_title_clean', 'salary_clean'],
dtype='object')
"""
问题:
-
洋外教的工资真的高吗?
-
市场对于洋外教的经验和学历要求如何?
-
哪些地区对洋外教的需求多?
-
什么机构在招聘洋外教?
问题1:洋外教的工资真的很高吗?
data_wx['teacher_type']='中教'
data_jlc['teacher_type']='外教'
data_salary=pd.concat([data_wx[['salary_clean','teacher_type']],data_jlc[['salary_clean','teacher_type']]])
data_salary.rename(columns={'salary_clean':'工资','teacher_type':'教师类型'},inplace=True) #更换名字
#画图
g=sns.FacetGrid(data_salary,row='教师类型',size=4,aspect=2,xlim=(0,30))
g.map(sns.distplot,'工资',rug=False)
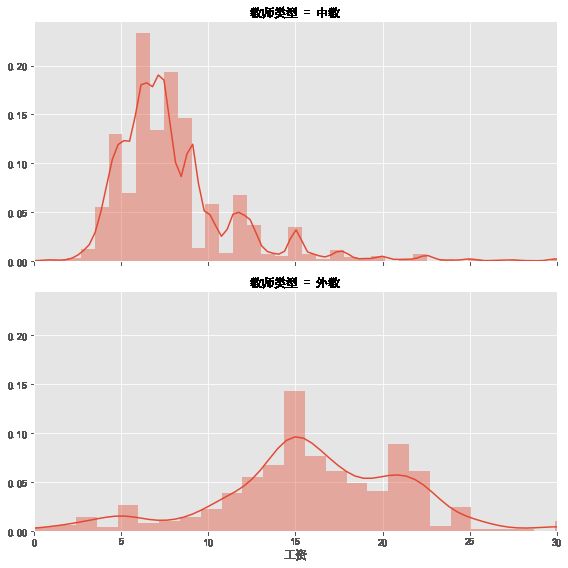
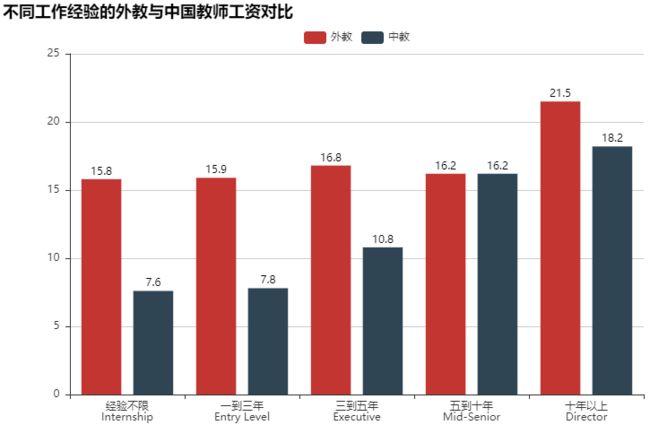
#洋外教的平均薪资 np.round(data_jlc['salary_clean'].mean(),1) #16.1 #中国老师的平均薪资 np.round(data_wx['salary_clean'].mean(),1) #8.1 #中国老师根据城市划分平均工资 查看的是第15-20 np.round(data_wx.groupby('city')['salary_clean'].mean().sort_values()[15:20],1) """ city 驻马店 5.0 文昌市 5.2 秦皇岛 5.2 常德 5.2 邢台 5.3 Name: salary_clean, dtype: float64 """ #通过经验进行比较 #洋外教根据经验划分薪资 data_jlc['exp_title_clean'].unique() """ array(['Executive', 'Mid-Senior Level', 'Entry Level', 'Internship', 'Associate', 'Director'], dtype=object) """ data_jlc.loc[data_jlc['exp_title_clean']=='Associate','exp_title_clean']='Entry Level' #修改元素 data_jlc['exp_title_clean'].unique() """ array(['Executive', 'Mid-Senior Level', 'Entry Level', 'Internship', 'Director'], dtype=object) """ np.round(data_jlc.groupby('exp_title_clean')['salary_clean'].mean(),1) """ exp_title_clean Director 21.5 Entry Level 15.9 Executive 16.8 Internship 15.8 Mid-Senior Level 16.2 Name: salary_clean, dtype: float64 """ #中国老师根据经验划分薪资 np.round(data_wx.groupby('exp')['salary_clean'].mean(),1) """ exp 一到三年 7.8 三到五年 10.8 五到十年 16.2 十年以上 18.2 经验不限 7.6 Name: salary_clean, dtype: float64 """ #绘制Bar图:不同经验的英语外教和中国教师的薪资对比 from pyecharts import Bar attr=['经验不限\nInternship','一到三年\nEntry Level','三到五年\nExecutive', '五到十年\nMid-Senior','十年以上\nDirector'] value1=[15.8,15.9,16.8,16.2,21.5] #外教按照经验的平均薪资 value2=[7.6,7.8,10.8,16.2,18.2] #中国教师按照经验的平均薪资 bar=Bar('不同工作经验的外教与中国教师工资对比',width=800,height=500) bar.add('外教',attr,value1,xaxis_label_textsize=18,legend_top=30,yaxis_label_textsize=20,is_label_show=True) bar.add('中教',attr,value2,xaxis_label_textsize=18,legend_top=30,yaxis_label_textsize=20,is_label_show=True) bar.render('不同工作经验的外交和中国教师工资对比.html')
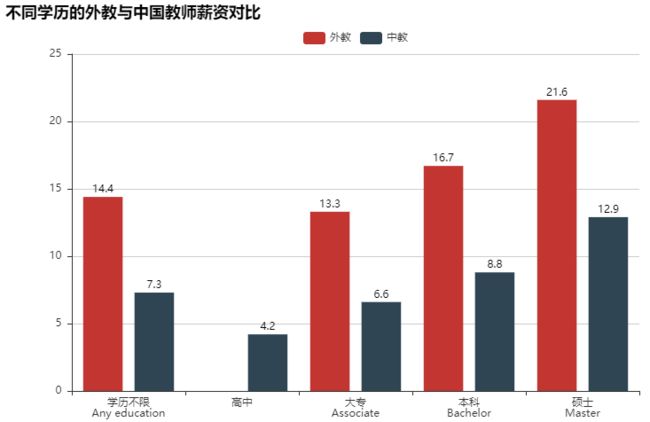
#通过学历进行比较 #外教根据学历划分薪资 np.round(data_jlc.groupby('education')['salary_clean'].mean(),1) """ education Any education 14.4 Associate 13.3 Bachelor 16.7 Master 21.6 Name: salary_clean, dtype: float64 """ #中国教师按照学历划分薪资 data_wx.loc[data_wx['degree']=='中专','degree']='高中' np.round(data_wx.groupby('degree')['salary_clean'].mean(),1) """ degree 大专 6.6 学历不限 7.3 本科 8.8 硕士 12.9 高中 4.8 Name: salary_clean, dtype: float64 """ #绘制Bar图:根据学历绘制外教和中国教师的薪资对比 attr=['学历不限\nAny education','高中','大专\nAssociate','本科\nBachelor','硕士\nMaster'] value1=[14.4,np.nan,13.3,16.7,21.6] #外教基于学历的薪资 value2=[7.3,4.2,6.6,8.8,12.9] #中国教师基于学历的薪资 bar=Bar('不同学历的外教与中国教师薪资对比',width=800,height=500) bar.add('外教',attr,value1,xaxis_label_textsize=15,legend_top=30,yaxis_label_textsize=20,is_label_show=True) bar.add('中教',attr,value2,xaxis_label_textsize=15,legend_top=30,yaxis_label_textsize=20,is_label_show=True) bar.render('不同学历的外教与中国教师薪资对比.html')
问题2:市场对于洋外教的经验和学历要求如何?
#外教基于经验的百分比分布 exp_demand=np.round(data_jlc['exp_title_clean'].value_counts()/data_jlc['exp_title_clean'].value_counts().sum()*100,1) exp_demand """ Entry Level 67.6 Mid-Senior Level 22.1 Executive 6.9 Internship 1.9 Director 1.6 Name: exp_title_clean, dtype: float64 """ #外教基于经验的饼状图分布 from pyecharts import Pie pie=Pie(title='不同经验外教需求百分比%') pie.add("",['入门','中高级','管理','实习','主任'],exp_demand.values,is_label_show=True) pie.render('不同经验外教需求百分比.html') #外教基于学历的百分比分布 education_demand=np.round(data_jlc['education'].value_counts()/data_jlc['education'].value_counts().sum()*100,1) education_demand """ Bachelor 75.1 Any education 22.9 Associate 1.4 Master 0.7 Name: education, dtype: float64 """ #外焦急与学历的饼状分布 pie=Pie(title='不同学历外教需求百分比%') pie.add("",['本科','学历不限','社区大学','硕士'],education_demand.values,is_label_show=True) pie.render('不同学历外教需求百分比.html')
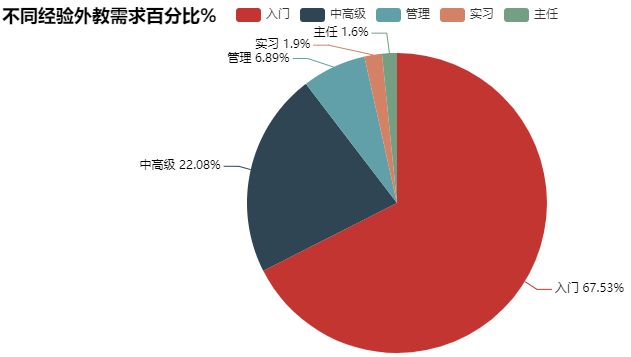
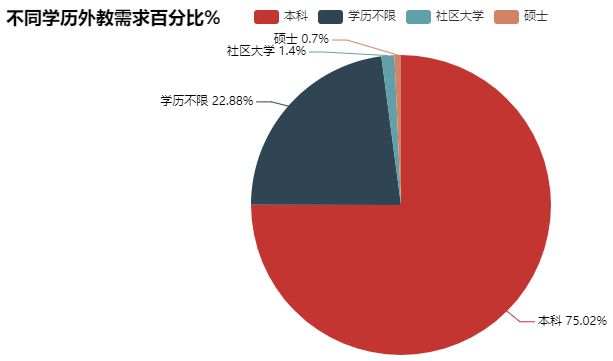
问题3:哪些地区对洋外教的需求多?
#对外教需求前10的城市 【取的是11个,有一个Others,将其剔除】
area_demand=data_jlc['area'].value_counts().nlargest(11).drop('Others')
area_demand
"""
Beijing 527
Shanghai 121
Hangzhou 100
Shenzhen 63
Guangzhou 51
Wuhan 31
Chengdu 26
Chongqing 24
Nanjing 19
Qingdao 17
Name: area, dtype: int64
"""
#绘图
bar=Bar('外教需求前10城市排名',width=800,height=500)
city10=['北京','上海','杭州','深圳','广州','武汉','成都','重庆','南京','青岛']
bar.add('',city10,area_demand.values,
xaxis_label_textsize=20,yaxis_label_textsize=20,is_label_show=True)
bar.render('外教需求前10城市排名.html')
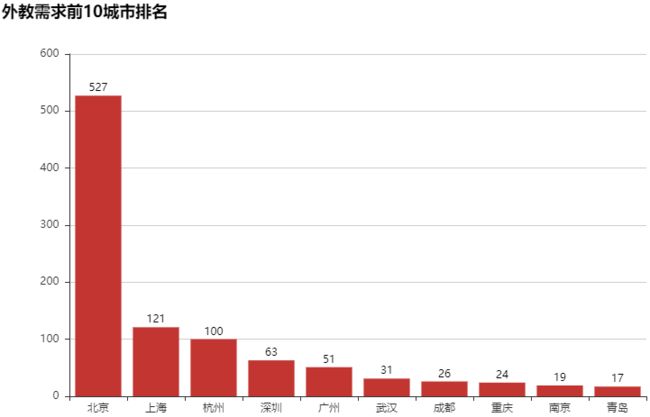
#外教前10城市的平均薪资 salary_clean=np.round(data_jlc.groupby('area')['salary_clean'].mean()[area_demand.index],1) salary_clean """ Beijing 16.8 Shanghai 16.8 Hangzhou 15.5 Shenzhen 17.8 Guangzhou 16.5 Wuhan 16.1 Chengdu 17.1 Chongqing 12.8 Nanjing 12.8 Qingdao 16.7 Name: salary_clean, dtype: float64 """ #中国教师对应城市(外键前10的城市)的平均薪资 np.round(data_wx[data_wx['city'].isin(city10)].groupby('city')['salary_clean'].mean(),1) """ city 上海 9.2 北京 9.7 南京 8.1 广州 8.1 成都 7.2 杭州 8.5 武汉 6.8 深圳 8.8 重庆 6.8 青岛 7.2 Name: salary_clean, dtype: float64 """ #绘图:对于外教需求前10的外教和中国教师的平均薪资 bar=Bar('对外教需求前10城市的外教和中国教师的平均薪资',width=800,height=500) bar.add('外教',city10,salary_clean.values,xaxis_label_textsize=18,yaxis_label_textsize=20,is_label_show=True) bar.add('中教',city10,[9.7,9.2,8.5,8.8,8.1,3.8,7.2,6.8,8.1,7.2]) bar.render('对外教需求前10城市的外教和中国教师的平均薪资.html')
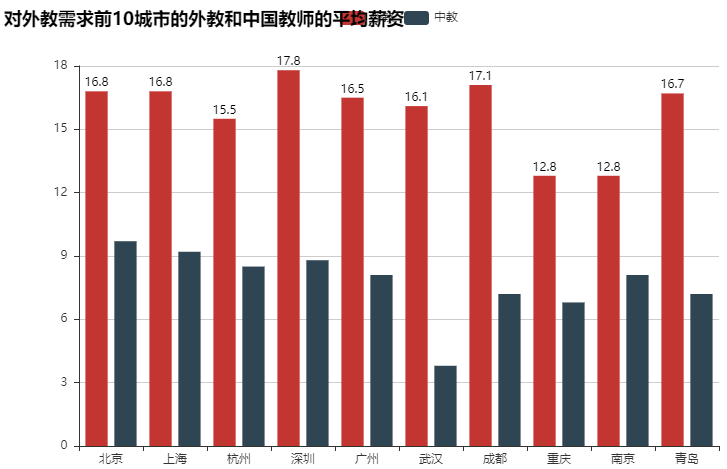
问题4:什么机构在招洋外教?
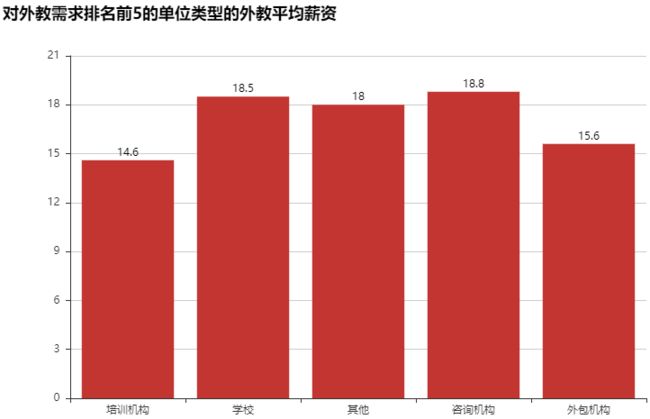
#对外教需求前5的公司类型 com_type_demand=data_jlc['com_type'].value_counts().nlargest(5) com_type_demand """ Teaching Center 678 School 340 Others 104 Consultancy/Legal/Admin 69 Outsourcing 13 Name: com_type, dtype: int64 """ bar=Bar('对外教需求排名前5的单位类型',width=800,height=500) bar.add('',['培训机构','学校','其他','资讯机构','外包机构'],com_type_demand.values, xaxis_label_textsize=18,yaxis_label_textsize=20,is_label_show=True) bar.render('对外教需求前5的单位类型.html') salary_com_type=np.round(data_jlc.groupby('com_type')['salary_clean'].mean()[com_type_demand.index],1) salary_com_type """ Teaching Center 14.6 School 18.5 Others 18.0 Consultancy/Legal/Admin 18.8 Outsourcing 15.6 Name: salary_clean, dtype: float64 """ bar=Bar('对外教需求排名前5的单位类型的外教平均薪资',width=800,height=500) bar.add('',['培训机构','学校','其他','咨询机构','外包机构'],salary_com_type.values, xaxis_label_textsize=18,yaxis_label_textsize=20,is_label_show=True) bar.render('对外教需求排名前5的单位类型的外教平均薪资.html') #Teacher Center 培训机构对外教学历的要求 百分比 np.round(data_jlc.loc[data_jlc['com_type']=='Teaching Center','education'].value_counts()/678*100,1) """ Bachelor 70.6 Any education 27.1 Associate 1.6 Master 0.6 Name: education, dtype: float64 """ company=data_jlc['company'].value_counts().nlargest(50) from pyecharts import WordCloud wordcloud=WordCloud(width=800,height=500) wordcloud.add('',company.index,company.values,word_size_range=[20,100]) wordcloud.render('外教公司的词云展示.html')