10亿级数据规模的半监督图像分类模型,Imagenet测试精度高达81.2% | 技术头条...

译者 | linstancy
作者| I. Zeki Yanlniz, Herve Jegou, Kan Chen, Manohar Paluri, Dhruv Mahajan
编辑 | 蓝色琥珀鱼,Rachel
出品 | AI科技大本营(ID:rgznai100)
【导读】本文提出了一种十亿级数据规模的半监督图像分类模型,通过使用教师-学生架构以及一个小规模的带标签数据集,作者提出了一个基于卷积神经网络的半监督学习方法。另外,作者对模型的不同架构和模型参数进行了消融实验,并提出了一些构建半监督学习模型的建议。
摘要
本文基于教师-学生架构(teacher-student schema),利用大规模无标签图像数据集 (多达十亿张),提出了一种基于大规模卷积神经网络的半监督学习方法,旨在改善给定目标模型架构的性能,如 ResNet-50 或 ResNext。随后,作者通过大量的评估分析了本文所提出方法的成功因素,提出了一些用于构建高性能半监督图像分类学习模型的建议。总的来说,本文的方法在构建图像、视频及细粒度分类的标准模型架构方面有着重要的意义,如利用一个含十亿张未标记的图像数据集训练得到的 vanilla ResNet-50 模型,在 Imagenet 数据集的基准测试中取得了 81.2% 的 top-1 精度。
简介
当前,利用网络弱监督数据集,图像和视频分类技术在诸如图像分类、细粒度识别等问题上取得了非常好的表现。但是,弱监督学习的标签存在一些缺陷。首先,非视觉性标签、缺失标签和不相关标签会导致噪声,这将对模型的训练造成很大影响。第二,弱监督的网络数据集通常遵循齐普夫定律,存在大量长尾(long-tail)标签,这使得模型只会对那些最显著的标签有良好的性能。最后,这些弱监督方法假定其可用于目标任务所使用的大型弱监督数据集,然而在许多现实情况中并非如此。
针对这些问题,本文利用数十亿张未标记的图像以及一个针对特定任务的相对较小的标签数据集,提出了一个用于网络规模数据的半监督深度学习模型,如图1所示:
(1)在标签数据集上训练以获得初始的教师模型 (teacher model); (2) 对于每个 class/label 对,使用该教师模型来对未标记的图像打标签并进行打分,选择每一标签类别的 top-K 个图像来构建新的训练数据; (3)使用新构建的数据来训练学生模型 (student model)。通常来说,学生模型与教师模型存在一定的差异,因此在测试时可以降低模型的复杂性; (4) 在初始的标签数据集上,对预训练的学生模型进行微调 (fine-tuning) ,以避免一些可能存在的标签错误。
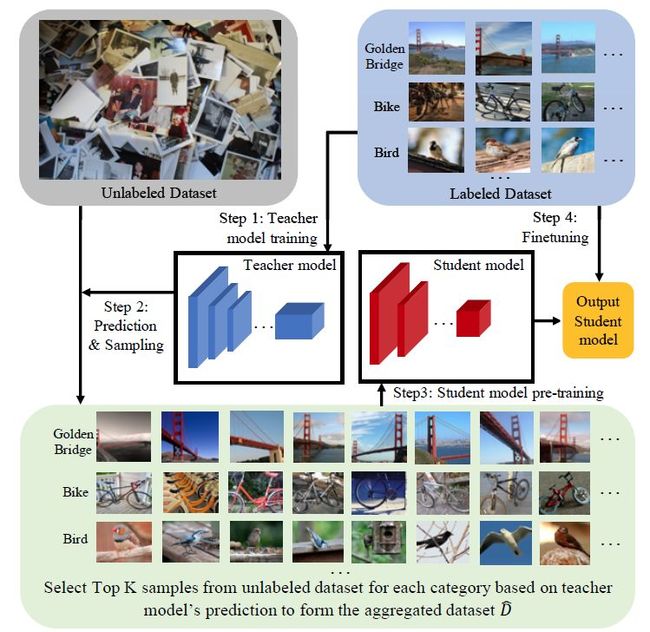
图1 半监督学习方法说明:通过一个优秀的教师模型,从一个非常大型的无标签图像数据集 (亿级) 构建一个新的训练集。随后,在这个带噪声的数据集上训练学生模型,再在原始的数据集上进行微调。
除此模型之外,本研究还尝试了几种其他的模型结构,一是移除教师 - 学生模型并使用自训练模型,二是在进行模型微调时使用推断出的标签作为训练数据。在实验分析部分,作者讨论了几个影响模型性能的敏感因素,如用于标签排名的教师模型的性能,无标签数据的规模以及性质,教师模型和学生模型之间的关系等。研究结果表明,利用主题标签或查询作为弱监督信号来收集无标签数据能够显著地提升模型的性能。
本文的贡献如下:
提出了一个用于大规模亿级无标签数据集的半监督深度学习方法,并展示了在标签数据上训练得到的教师模型能够有效地指导学生模型在无标签图像数据上的训练学习过程。
总结了这种学习策略在何种情况下能带来最大收益,如图2。
对多种模型架构进行消融实验并做详细分析,如教师/学生模型的强度,无标签数据集的性质,所选择样本的标签数等。
展示了这种半监督学习方法在视频分类和细粒度识别任务中的表现。

图2 用于构建大规模半监督学习模型的建议
半监督学习方法
本文所提出的半监督学习方法主要包含四个部分,如图3所示:

图3 半监督学习方法流程
这与当前的一些蒸馏研究流程相类似,不同之处如下:(1) 联合利用无标签和标签数据的方法;(2) 构建标签数据集 D 的方法;(3) 使用的数据规模以及针对 Imagenet 数据集的改进。
教师模型训练
这一步骤在标签数据集上训练一个教师模型,以便对无标签数据集的图像打标签。这种方法的一大优点在于推理过程是高度可并行的,这意味着不论是在 CPU 还是在 GPU 上,对大规模亿级数据的计算也能在很短时间内完成。该阶段训练一个性能优秀的教师模型,以便为无标签数据生成可靠的标签信息,且不引入多余的标签噪声。
数据选择和标签
这一步旨在收集大量的图像数据,并对标签噪声进行控制。由于无标签数据的规模很大,因此对于每个目标标签,从无标签数据集中选用 top-K 个样本。首先,用无标签数据集的每个样本来训练教师模型,以获得 softmax 预测向量。而对于每张图像而言,只能得到与类别相关的 P 个最高分数,其中 P 是一个用来反映我们期望出现在每个图像中的最多的类别数量。随后,基于相关的类别分数,对图像进行排名 (ranking),并选择用于多类别半监督图像分类的新的图像数据。图4展示了在 ImageNet-val 数据集上基于 ResNet-50 训练出的教师模型在 YFCC100M 数据上的排名结果,其中 P = 5 。排名越高的图像,所带的标签噪声越少。

图4 通过本文方法从 YFCC100M 上所收集的图像样本
学生模型的训练与微调
这一步用新的标签数据集数据来训练学生模型,旨在得到一个更简单通用的模型。实际上,这里可以选用与教师模型相同结构的学生模型。值得注意的是,虽然为标签数据集中每个图像分配多个类别标签信息是可以实现的,但这里仍通过图像复制的方式将问题视为一种多类别分类任务。之后,在原始标签数据集上对学生模型微调并进行评估,在预训练和微调过程都采用 softmax 损失函数。
图像分类实验与分析
这一部分,作者通过在 ImageNet1K 数据集上的一系列图像分类实验评估了该模型的效果。
实验设置
数据集:使用下面两个网络规模的数据集作为无标签数据,用于半监督学习实验。
YFCC-100M :这一数据集是从 Flickr 网站提取得到的一个含9千万张图像的公开数据集。移除数据集中的重复样本后,作者将该数据集用于后续大部分的实验。
IG-1B-Targeted :这一数据集是作者从社交媒体网站上收集的,包含10亿张公共图像数据。
除非有特别的说明,这里统一采用标准的1000个类别的 ImageNet 作为标签数据集。
模型:对于教师和学生模型,分别采用残差网络(residul network) ResNet-d ,其中 d = {18, 50} ,以及使用群卷积(group convolution)的残差网络 ResNeXt-101 32XCd ,其中分组宽度 C = {4, 8, 16, 48} 。具体的模型参数如图5所示:

图5 改变教师模型容量并用所提出的方法来训练 ResNet-50 学生模型,这里的收益是相对于监督学习基准准确度的绝对提升值。
训练细节:实验过程通过使用同步随机梯度下降算法(synchronous stochastic gradient descent, SGD) 在8台机器的64个 GPU 上训练模型。每个 GPU 一次处理24张图像,并对所有的卷积层采用批正则化策略(batch normalization)。权重衰减参数设置为0.0001,训练过程的学习率设置采用带 warm-up 的缩放策略,整体的 minibatch 大小为 64 * 24 = 1536 。
对于模型预训练,采用 0.1 到 0.1/256×1536 的 warm-up 策略,这里的 0.1 和 256分别是 ImageNet 训练中使用的标准学习率和 minibatch 尺寸。此外,采用二等分间隔的学习率衰减策略,使得在训练过程中学习率减少次数共为13次。在基于 ImageNet 数据集对模型进行微调时,将学习率设为 0.00025 / 256 × 1536,并在30 个 epochs 期间采用三等分间隔减少学习率。
不同模型的实验分析
本文方法 vs 监督学习方法 图6比较了本文方法与监督学习方法在 ImageNet 数据集上的效果。可以看到,相比于监督学习,本文方法训练的教师模型取得了显著的性能改进。
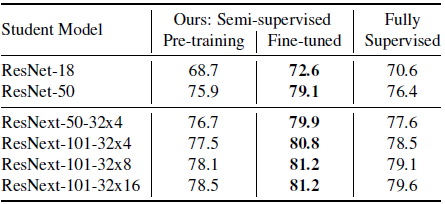
图6 本文方法与监督学习方法在不同容量的学生模型上微调前后的 ImageNet1k-val top-1 精度
模型微调的重要性 由于预训练的数据集和标签数据集的标签信息是一样的,作者比较了模型在标签数据上微调前后的性能。如上图6所示,可以看到在标签数据上进行微调对于模型性能有着至关重要的影响。
学生和教师模型容量的影响 如上图5、图6所示,可以看到对于容量更低的学生模型,识别的精度有显著地提高。而对于教师模型而言,增大模型的容量并不会对学生模型的性能造成显著影响。
自训练:教师/学生模型的消融实验 (ablation) 图7展示了在自训练模式下,模型在ImageNet 数据集上训练得到的不同模型在推断时的准确度。可以看到,对于容量更大的模型,所取得的准确度表现相对更好。
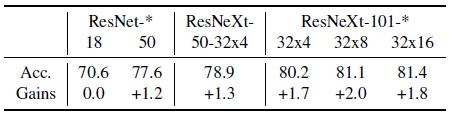
图7 自训练模式下 ResNet 和 ResNeXt 模型在 YFCC 数据集上的 top-1 准确度,这里的收益是相对于监督学习基准的提升值。
参数分析
无标签数据集的大小 下图8展示不同规模的无标签数据集上半监督学习模型的准确度表现。可以看到,在数据集规模达到2千5百万之前,每当数据集规模成倍增加时,模型能够取得稳定的准确度提升。总的来说,采用大型的无标签数据对于模型性能的提升是有帮助的。
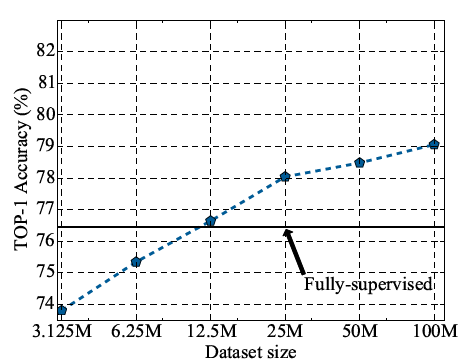
图8 ResNet-50 学生模型在不同规模的无标签数据上的精度
预训练迭代次数 图9展示了不同预训练迭代次数下的模型性能表现。可以看到,当迭代次数为10亿次时,模型能够实现良好的识别准确度和计算资源的权衡。
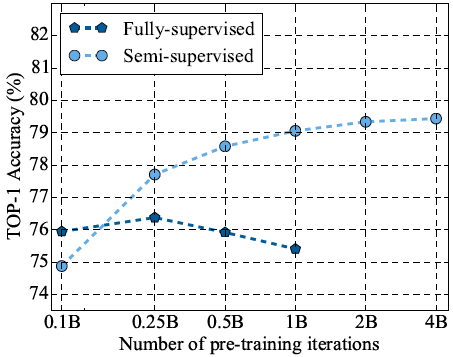
图9 不同预训练步数对完全监督和半监督的 ResNet-50 学生模型性能的影响
参数 K 和 P 图10展示了当 P = 10 时,每个类别选择的图片数 K 的变化对模型性能的影响。作者发现,在所收集的无标签数据集规模不是很大时,令 P = 10 能获得较好的模型表现。
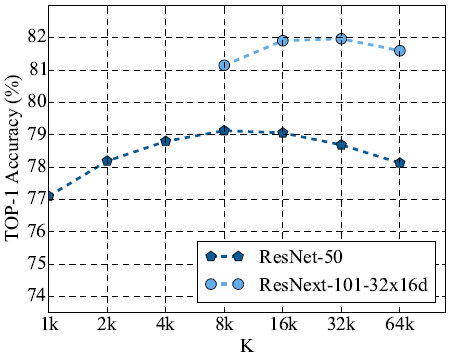
图10 对于超参数 K 的不同取值,学生模型的精度表现。
此外,实验还对一些不同的半监督学习的方法进行了分析,并将模型的表现与当前最先进的模型性能进行对比。除了图像分类实验外,本研究还进一步探究在视频分类、迁移学习等不同应用中该半监督学习方法的性能。具体的分析内容和说明可参见原论文。
总结
本文研究利用大规模的无标签图像数据集,探究了半监督学习在图像识别方面的应用,并提高了 CNN 模型的性能表现。通过一系列的实验分析,作者提出,联合使用大型标签数据集和小规模有标签数据集能够有助于构建效果更好的卷积神经网络模型。此外,研究还对一些模型参数和模型变体进行了实验分析,并总结了一些构建半监督图像分类模型的经验方法。
原文链接:
https://arxiv.org/abs/1905.00546
(本文为 AI科技大本营编译文章,转载请微信联系 1092722531)
◆
CTA核心技术及应用峰会
◆
5月25-27日,由中国IT社区CSDN与数字经济人才发展中心联合主办的第一届CTA核心技术及应用峰会将在杭州国际博览中心隆重召开,峰会将围绕人工智能领域,邀请技术领航者,与开发者共同探讨机器学习和知识图谱的前沿研究及应用。
更多重磅嘉宾请识别海报二维码查看,目前会议早鸟票发售中(原票价1099元),点击阅读原文即刻抢购。添加小助手微信15101014297,备注“CTA”,了解票务以及会务详情。

推荐阅读
Yann LeCun推荐!自监督学习、全景FPN...内容平台的四大技术指南
如何确定最佳训练数据集规模?6 大必备“锦囊”全给你了 | 技术头条
如何在Python中轻松使用CVS,JSON,XML
一篇文章讲清楚Python虚拟环境
华为员工年薪 200 万!真相让人心酸!
什么是云计算基础设施? | 技术头条
Facebook数据泄漏受害者: 既然无法阻止个人数据被卖, 不如我自己先卖
@程序员,不是你选择加班,而是 KPI 驯化你
全球 AI 报告出炉:美国称王,中国砸 80W 年薪抢人才紧追!
