中文文本纠错算法实现

向AI转型的程序员都关注了这个号????????????
机器学习AI算法工程 公众号:datayx
文本纠错又称为拼写错误或者拼写检查,由于纯文本往往来源于手打或者OCR识别,很可能存在一些错误,因此此技术也是一大关键的文本预处理过程,一般存在两大纠错类型。
1.拼写错误
第一种是Non-word拼写错误,表示此词汇本身在字典中不存在,比如把“要求”误写为“药求”,
2.少字多字
中文文本纠错比较难,不多说。上思路
方法有很多,本文讲解基于拼音
思路:
1首先:本地得有一个正确字词的数据库 。命名 数据库.txt
格式:第一列正确字词,第二列 词频 ,第三列 词性
本文只用词和词频。考虑词性太难啦。
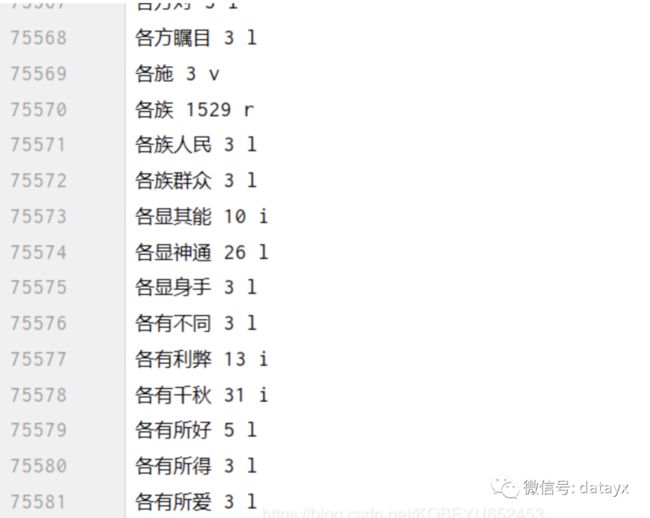
2.得有一个文档txt,供编辑距离函数操作的。命名 编辑距离.txt
如下图

3.加载 数据库.txt 和 编辑距离.txt
4 输入一个错误单词(句子分词得到的单词,或者单独一个错误单词),计算编辑距离,生成编辑距离词集。
编辑距离需要比对 数据库.txt 的单词,计算距离
然后对错误单词进行删除字,增加字,修改字,替换字。增加删除替换哪些字呀,肯定得从 编辑距离.txt 文档里选取字插入或替换到错误单词里。最后生成编辑距离词集
5 生成的编辑距离词集 肯定含有一些错误单词,找出同时在编辑距离词集和数据库.txt 的单词 ,即为我们候选正确词集
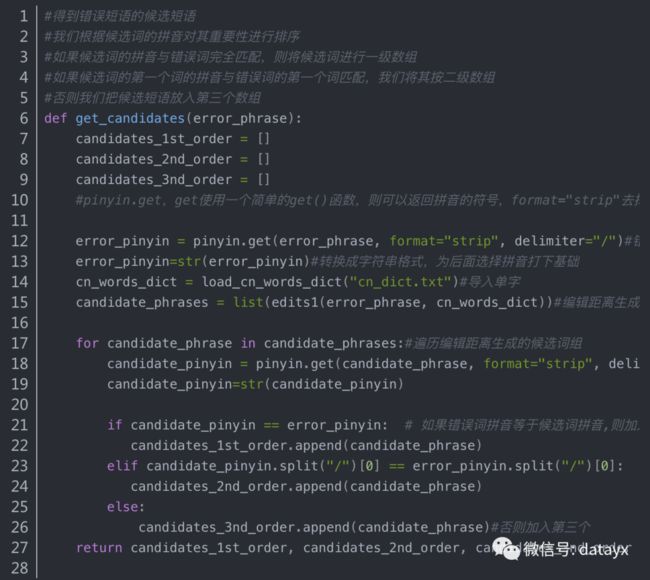
6. 对候选正确词进行分级。首先 pinyin.get得到错误词的拼音
然后遍历 候选正确词集的单词,求取得拼音。
我们根据候选词的拼音对其重要性进行排序
如果候选词的拼音与错误词完全匹配,则将候选词放入一级数组
#如果候选词的第一个词的拼音与错误词的第一个词匹配,我们将其按二级数组。否则我们把候选短语放入三级数组.
7.找到正确单词
如果一级数组存在, 得到 的正确字词是在 数据库.txt 中的。考虑到得到的词可能有多个,前文提到数据库.txt 第一列是词,第二列是词频 。我们应该返回一级数组中 词在数据库.txt 中词频最大的那个单词
如果一级数组不存在,二级数组存在,,返回词频最大的那个单词
否则:返回三级数组词频最大的那个单词。
本文代码 获取:
关注微信公众号 datayx 然后回复 纠错 即可获取。
AI项目体验地址 https://loveai.tech
代码:
1导入包 和标点符号

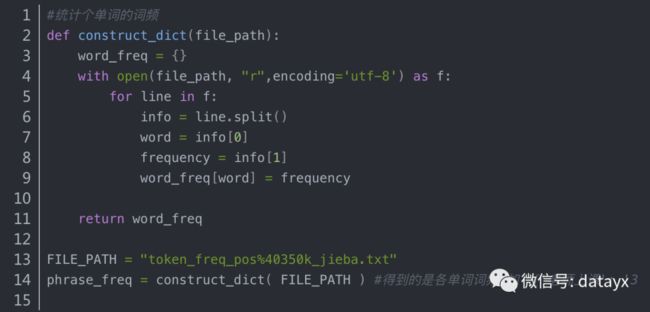
2读取 数据库.txt
只读取第一列和第二列 ,最后生成字典。
#得到的是各单词词频,如:{‘老师上课’: ‘3’, ‘老师傅’: ‘62’, ‘老师宿儒’: ‘老师上课’: ‘3’, ‘老师傅’: ‘62’, }
3.读取编辑距离.txt

4. 计算错误单词与数据库.txt里的单词的编辑距离

5.找到候选正确词集 。即编辑距离生成的词同时又在数据库.txt里的词

6.计算拼音,得到一级数组,二级数组,三级数据。对候选正确词进行分级
7.找到正确单词

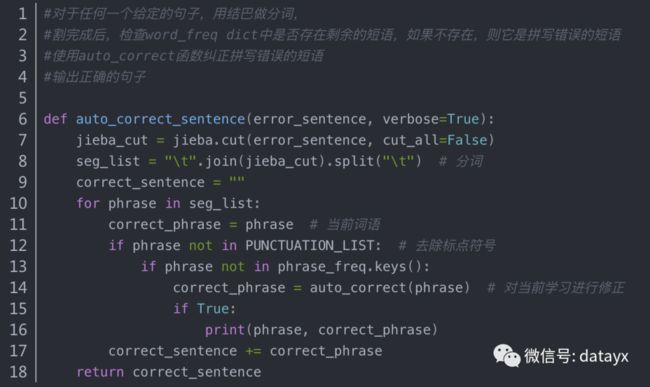
8.测试 对一个句子进行分词 ,然后每个单词 拿去寻找正确单词 ,最后将这些词拼接为正确句子
9.主函数


阅读过本文的人还看了以下文章:
TensorFlow 2.0深度学习案例实战
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《基于深度学习的自然语言处理》中/英PDF
Deep Learning 中文版初版-周志华团队
【全套视频课】最全的目标检测算法系列讲解,通俗易懂!
《美团机器学习实践》_美团算法团队.pdf
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
特征提取与图像处理(第二版).pdf
python就业班学习视频,从入门到实战项目
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
《Python数据分析与挖掘实战》PDF+完整源码
汽车行业完整知识图谱项目实战视频(全23课)
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

机大数据技术与机器学习工程
搜索公众号添加: datanlp

长按图片,识别二维码