【转载】SELU 激活函数
说明
本文非本人所著,转载自 https://www.jianshu.com/p/3a43a6a860ef。
主要内容为李宏毅老师深度学习课程某次讲的 SELU 激活函数课程。由于课堂效果极好(实验部分),给我留下及其深刻的印象,所以特地挑选了一篇比较好的笔记备份到本博客上。
正文
要复现的一篇文章使用了一个奇怪的激活函数:the scaled exponential linear units, 相关论文发表在 NIPS 2017, 附录证明多达 70 余页。
刚刚发现超可爱的台湾李宏毅老师早在去年就对 SELU 做了介绍,跟着视频学习一下好了,至于实验效果等我成功复现那篇 未开源 的论文后再来补充。
B站视频地址: 【戳我】
课件地址: 【戳我】
SELU论文地址 :【Self-Normalizing Neural Networks】.
1. ReLu 变体
Leaky ReLU
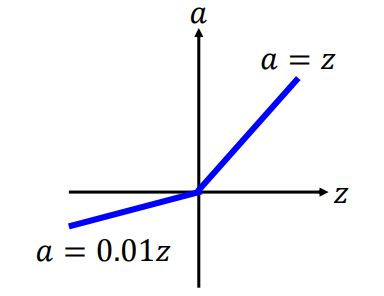
Parametric ReLU
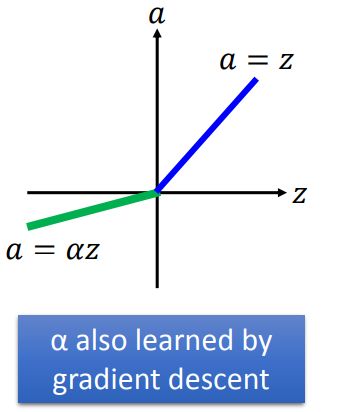
Exponential Linear
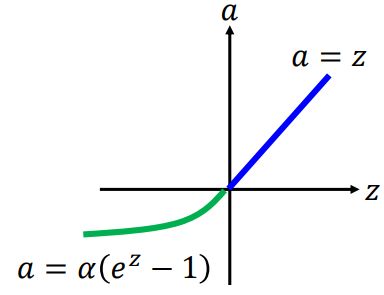
2 SELU
形式
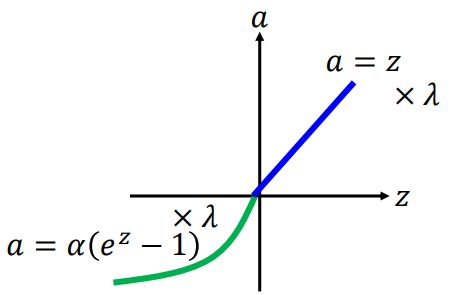
其中超参 α 和 λ 的值是 证明得到 的(而非训练学习得到):
α **= 1.6732632423543772848170429916717**
λ **= 1.0507009873554804934193349852946**
特点

即:
- 不存在死区
- 存在饱和区(负无穷时, 趋于 - `αλ`)
- 输入大于零时,激活输出对输入进行了放大
- 证明
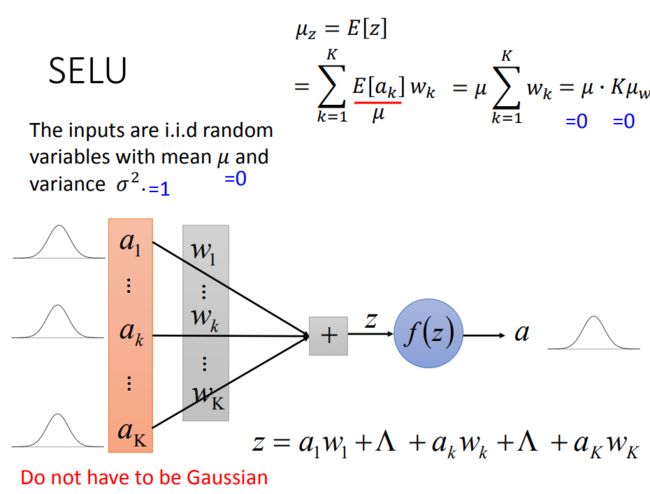
记输入 [ a1..ak...aK] 各维独立同分布, 每一维的分布均值为零,方差为 1, 注意: 该分部不一定是高斯分布,只需满足均值为零,方差为 1 即可。
我们的目标是: 寻找一个激活函数,使得神经元输出的激活值 a 也满足均值为零,方差为 1.
后续的证明视频里跳过去了,很遗憾。

根据 ppt 得出一个不严谨的观察:为了满足输出 a 符合 均值为 0, 标准差为 1 , 权重向量 [w1, w2,...wk, wK] 需满足均值为 0, 标准差为 1/K.
3. 老师做的实验
老师搭了一个包含 50 层隐含层的全连接网络。
input不做标准化 +relu函数

训练 3 个 epoch 后, 发现准确率没有提升。

input不做标准化 +selu函数
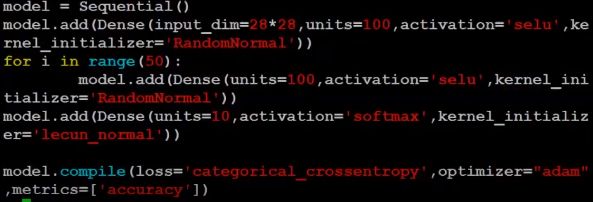
keras 已内建 selu 函数 ,训练 3 个 epoch 后, 发现准确率依然没有明显提升(只比 relu 好一点)。

input标准化 +selu函数
使用 selu 时,我们假设上一层的神经元输出符合均值为 0 , 方差为 1 的分布 ,所以需要将输入进行标准化。
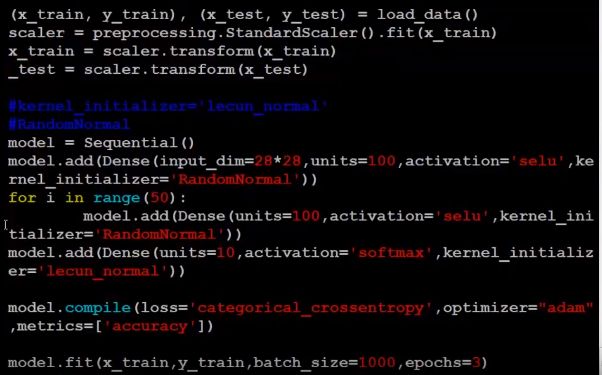
训练 3 个 epoch 后, 发现网络仍然没有 train 起来:

weight标准化 +selu函数
前面我们有一个不严谨的观察 : 权重需要满足均值为零,方差为 1/K, 在训练过程中我们无法保证权重满足这一条件, 但是我们可以让初始化时的权重满足这一条件,使用 lecunNorm 即可。
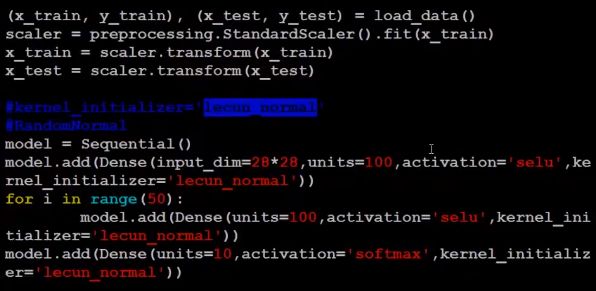
训练 3 个 epoch 后, 发现效果惊人!

weight标准化 +relu函数
我们可能有疑问: 训练效果的提升可能应该归功于 lecunNorm, 而非 selu, 所以老师做了一组对照实验:
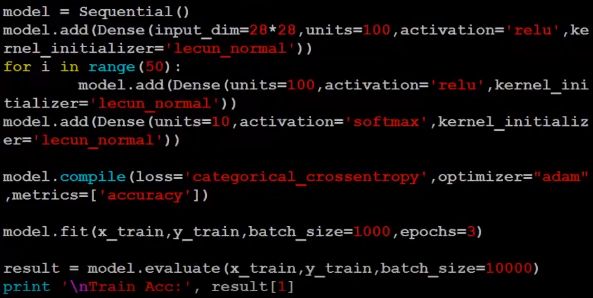
训练 3 个 epoch 后, 发现网络没有 train 起来。说明 selu + weight lecunNorm 才是真正的大杀器!!(李老师上课真的非常逗比)

4. Pytorch 实现 SELU
实现链接:【戳我】
import torch.nn.functional as F
def selu(x):
alpha = 1.6732632423543772848170429916717
scale = 1.0507009873554804934193349852946
return scale * F.elu(x, alpha)