前后端分离架构设计
本文为阅读http://frontenddev.org/link/full-stack-development-with-nodejs-1.html后总结而得
前后端分离的优点
划分清楚前后端职责
后端专注于:
- 服务层
- 数据格式、数据稳定
- 业务逻辑
前端专注于:
- UI层
- 控制逻辑、渲染逻辑
- 交互、用户体验
对前端发挥的局限
我们在对项目进行优化时候,其实前端给我们的优化空间有,但是很小,很多优化都是要在后端来进行的,而我们后台框架的限制,导致赋予我们前端的后端优化空间太小,几乎可以说没有,这样,很多优秀的技术方案无法使用,比如webpack、Comet、Bigpipe等。所以前端与后台相脱离在我来看很有必要,我们可以使用自己的框架,而不用在这样高度依赖于后台框架,这样,最起码我们写代码写的更自由,想怎么搞怎么搞,自由了心情就爽,心情爽了上班就high.....
前后端分离的缺点
- NodeJS代码如果异常处理不好容易直接挂掉进程。
- 增加了部署和维护成本
- 对前端开发者技术要求比较高
- 增加了一层NodeJS,提高了网络传输的开销
如何实现前后端分离
前端负责:view和controller层
后端负责:Model层
从以上分工可知,我们在后端与浏览器之间,多加了一层node,那么多了一层需要通讯,很明显,有一大缺点,在同等条件下,通讯的损耗更大,但同时还有一个明显的好处,我们可以通过node最大可能的降低损耗,比如,我们个人中心,首页是各个系统的数据集合,也就是说,我要显示出首页,需要连续发送6-7个请求,才能填补完整首页。在pc端上我们看到已经有很大的延迟了,而如果这个首页放到移动端呢?消耗资源更大,一个http的开销很大,如果我们前端拥有了node,就可以在我们的环境下,使用webpack、bigpipe等技术方案,将这些请求进行优化,很大程度上减少了资源的消耗。
渲染
在上面提到了,我们前后端分离,一个目的就是让后端专注于对业务逻辑/数据等内容的开发,因此,在渲染这方面,我倾向于前端通过node来渲染
接口配置建模框架
目前虽然我们做了前后端分离,但是,在前端调用后台提供的接口时,仍有以下问题:
1、开发人员仍需要自行通过mock生成假数据,并在页面编写完成后删除mock代码。
2、接口联调的成本仍然很高,前后端在这种联调情况下仍然被绑在一起。
3、关于接口调用的各种约定可能散落在代码的各个角落,导致当时协商外的其他成员对于接口调用规则不甚了解。
于是我们想要通过一种中间件,规范化统一化对于后台接口的调用,并且最好可以方便生成假数据。
Midway-ModelProxy就是这样的一个中间件。

如上图所示:首先,需要编写interface.json,该文件以json格式,描述了工程项目中所有依赖的后端接口描述。必要时,需要对每个接口编写一个规则文件,也即图中interface rules部分。该规则文件用于在开发阶段mock数据或者在联调阶段使用River工具集去验证接口。规则文件的内容取决于采用哪一种mock引擎(比如 mockjs, river-mock 等等)。配置完成之后,即可在代码中按照自己的需求创建自己的业务model。
举例说明:
第一步 在工程目录中创建接口配置文件interface.json, 并在其中添加主搜接口json定义
第二步 在代码中创建并使用model
{
"title": "pad淘宝项目数据接口集合定义",
"version": "1.0.0",
"engine": "mockjs",
"rulebase": "./interfaceRules/",
"status": "online",
"interfaces": [//定义需要跟后台对接的所有接口 {
"name": "主搜索接口",
"id": "Search.getItems",
"urls": {
"online": "http://s.m.taobao.com/client/search.do"
}
} ]
}第二步 在代码中创建并使用model
// 引入模块
var ModelProxy = require( 'modelproxy' );
// 全局初始化引入接口配置文件 (注意:初始化工作有且只有一次)
ModelProxy.init( './interface.json' );
// 创建model,并定义所有需要使用的model方法。
var searchModel = new ModelProxy( {
searchItems: 'Search.getItems' // 自定义方法名: 配置文件中的定义的接口ID
} );
// 使用model, 注意: 调用方法所需要的参数即为实际接口所需要的参数。通常是定义在路由中,当发送指定请求,执行model的指定方法。
searchModel.searchItems( { q: 'iphone6' } )
// !注意 必须调用 done 方法指定回调函数,来取得上面异步调用searchItems获得的数据!
.done( function( data ) {
console.log( data );
} )
.error( function( err ) {
console.log( err );
} );前后端分离下的安全性问题
跨站脚本攻击(XSS)的防御
其特点是不对服务器端造成任何伤害,而是通过一些正常的站内交互途径,例如发布评论,提交含有 JavaScript 的内容文本。这时服务器端如果没有过滤或转义掉这些脚本,作为内容发布到了页面上,其他用户访问这个页面的时候就会运行这些脚本。比如
while (true) {
alert("你关不掉我~");
}
要阻止这种攻击的实现,有一种方式,就是将$description的值进行html escape。
而如果是编辑器中提交的富文本,则需要一些其他的处理,这里不详细介绍。
跨站请求伪造攻击(CSRF)的预防
正常的用户修改请求:用户请求修改信息(1) -> 网站显示用户修改信息的表单(2) -> 用户修改信息并提交(3) -> 网站接受用户修改的数据并保存(4)
CSRF攻击修改服务器数据:直接跳到第2步(1) -> 伪造要修改的信息并提交(2) -> 网站接受攻击者修改参数数据并保存(3)
因此,我们需要确定的,就是,是否有‘用户请求修改信息’这一步。通过每个请求的特殊token的识别判断,可以实现以上判定
用户请求修改信息——服务器返回一个token以及表单信息给用户,同时将该token保存在session中——用户填写完要修改的信息,将修改信息和token发送给服务器——服务器判断是否为session中的token,若是,则说明确实是用户自己主动请求的修改信息,则对服务器数据进行对应的修改,并将修改结果返回给用户。
淘宝Midway流程:

除此之外,禁止get请求来修改服务器数据,也是需要采取,来阻止csrf攻击的措施。
Nginx + Node.js + Java 的软件栈部署实践
淘宝网线上应用的传统软件栈结构为 Nginx + Velocity + Java,即:
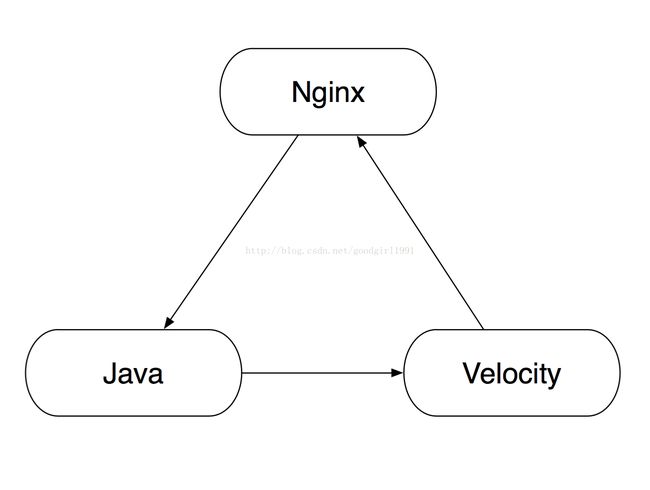
在这个体系中,Nginx 将请求转发给 Java 应用,后者处理完事务,再将数据用 Velocity 模板渲染成最终的页面。
按照淘宝团队的设计思路,Velocity 需要被 Node.js 取代,从而让这个结构变成: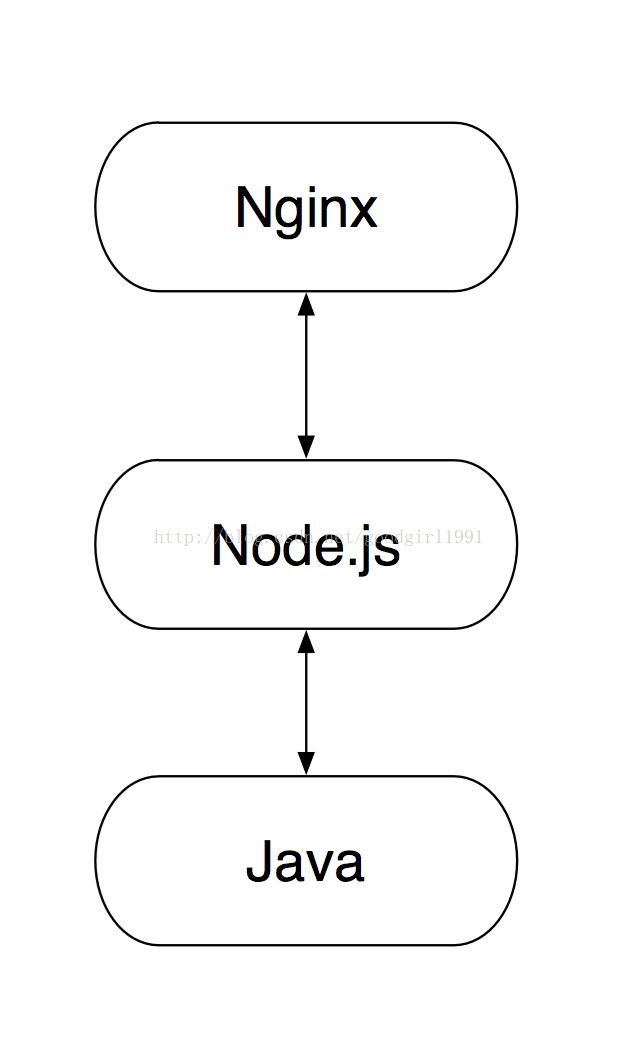
在这个体系中,Nginx 将请求转发给 Java 应用,后者处理完事务,再将数据用 Velocity 模板渲染成最终的页面。
按照淘宝团队的设计思路,Velocity 需要被 Node.js 取代,从而让这个结构变成:
由于首次采用该设计,为了稳妥起见,淘宝只将其收藏夹功能采用该设计来实现,其余功能皆沿用原设计。即
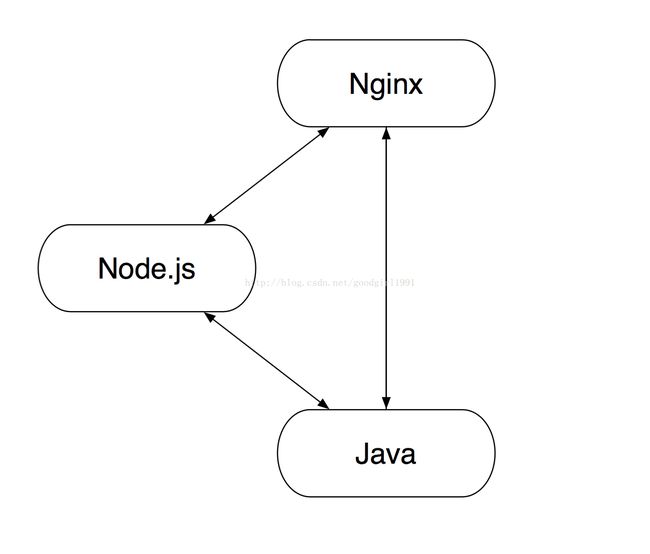
虽然所有的服务器上都跑着 Java + Node.js 的进程,但 Nginx 上有没有相应的转发规则,决定了获取这台服务器上请求宝贝收藏的请求是否会经过 Node.js 来处理。其中 Nginx 的配置为:
location = "/item_collect.htm" {
proxy_pass http://127.0.0.1:6001; # Node.js 进程监听的端口
}