python爬取unsplash壁纸
前几天想写一个爬虫,无意间发现这个https://unsplash.com/这个壁纸网站
感觉还不错,就试着爬一下,虽然并没有什么意义,因为壁纸有一张就好了,没必要爬好多。
分析页面:
页面中有search这个窗口,搜索一次发现url的格式,这样就可以构造任何想下载类型的壁纸了。
![]()
审查元素发现每张照片都有自己独特的id
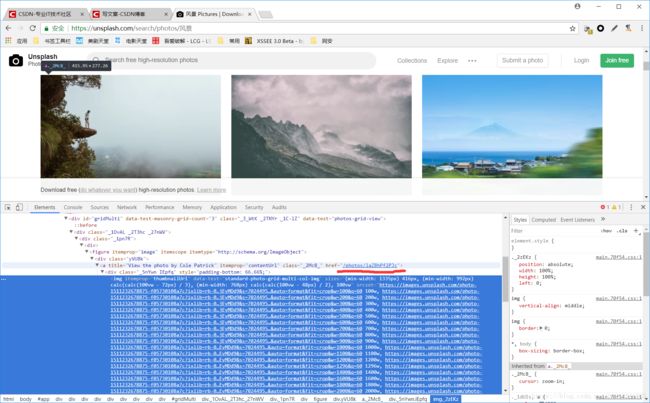 而且下载链接格式为
而且下载链接格式为
https://unsplash.com/photos/'+id+'/download
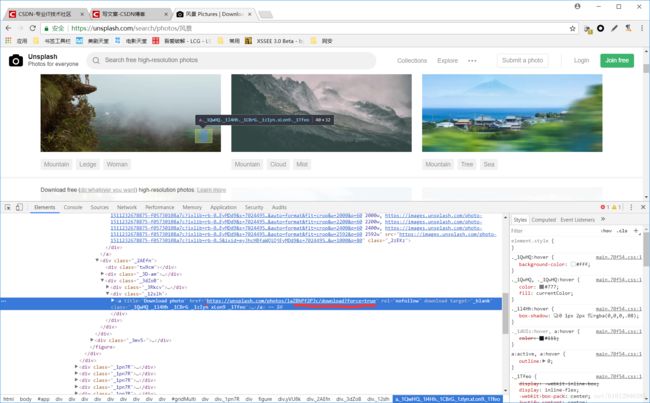
就开始用正则表达式来提取图片id,用固定格式来下载。
但是在使用过程中发现这样只能搜索到10个图片id,也就是只能下载10张图片,这样爬虫显得就毫无意义了。
为什么搜索结果那么多,然而只能正则找到10个图片呢?
因为这个页面使用了动态加载,在用户下拉到一定位置触发js的一个事件,来获取下面照片的信息。
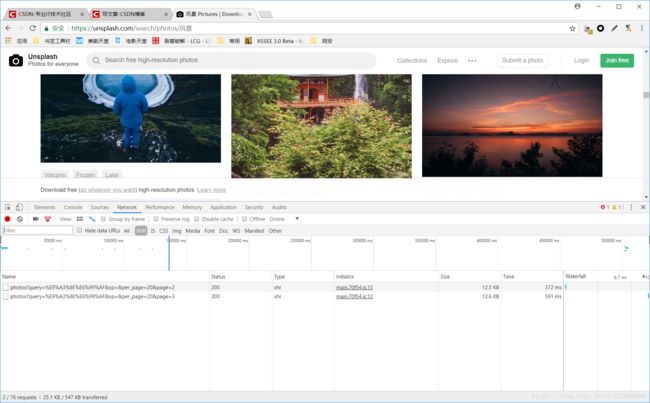
在控制台可以看到下拉的时候发送的数据:
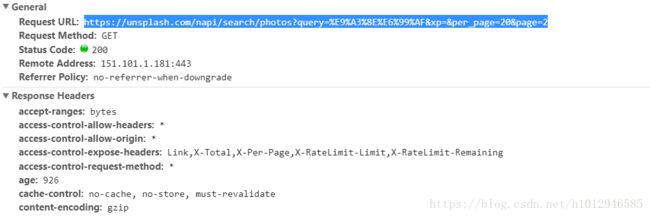
url解码看看。

发现也是具有固定格式的,而且每一页包含20张图片,page=x ,这个x是递增的。
进入url发现这里面同样有图片id:
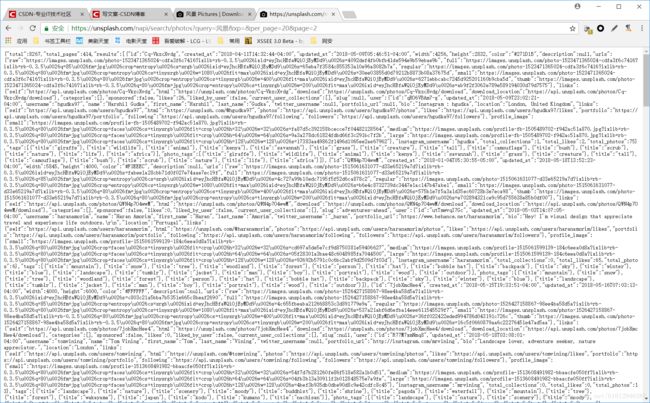
这样就可以每次请求这个url,通过变换page=来得到每页的图片id,再通过下载url进行下载。
写代码。
import requests
import re,os
import time,random
def tupian(leixing):
page=1 #初始page=1
i=1 #记录图片个数
while True: #爬到地老天荒
url = 'https://unsplash.com/napi/search/photos?query='+leixing+'&xp=&per_page=20&page='+str(page)
r = requests.get(url) #获取网页代码
r.headers={
'Pragma' : 'no-cache',
'Cache-Control' : 'no-cache',
'Upgrade-Insecure-Requests' : '1',
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36',
'Accept' : 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Language' : 'zh-CN,zh;q=0.9',
'Connection' : 'close',
} #设置requests的一些特征,防止反爬虫机制
#print(r.text)
key = '\"download\":\"https://unsplash.com/photos/(.*?)/download\"' #下载图片的固定url
c = re.findall(key,r.text, re.S) #提取图片id
# print(c)
for id in c:
time.sleep(random.uniform(0,1)) #为了尽量友好,设置超时时间
if i%10==0: #也是为了友好。
time.sleep(10)
try:
fp=open('E:\\图片\\'+leixing+"\\"+id+'.jpg',"wb") #打开文件
except:
os.makedirs('E:\\图片\\' + leixing + "\\") #没有此文件夹的话,新建文件夹
print("正在下载第{}张图片".format(i))
d = requests.get('https://unsplash.com/photos/'+id+'/download') #获取图片数据
try:
fp.write(d.content) #将数据写入文件
fp.close()
print("完成!")
except:
print("无法连接!")
continue
page = page + 1 #page数量变换达到重复爬取的目的
i = i + 1 #爬取数量计数
leixing=input("输入你想要的图片类型:") #输入图片类型
tupian(leixing)成果:
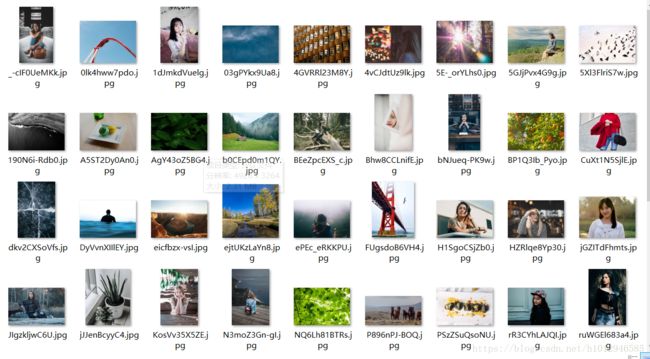
由于硬盘数量有限,就爬了一点。
希望大家共同交流,不当之处还请指出,谢谢!