图像分割-综述2020.3.1
整理时间为2020.2.21
【传统分割方法】
1、基于阈值的分割:
思想:利用图像的灰度特征。
方法:单阈值分割、多阈值分割
特点:只考虑灰度特征、不考虑空间特征,鲁棒性不好
改进方向:将智能遗传算法应用于阈值筛选,选取最优阈值。
2、基于区域的分割:
思想:直接寻找区域
方法:区域生长、区域分裂合并、分水岭算法
区域生长算法需要解决的三个问题:
(1)选择或确定一组能正确代表所需区域的种子像素;
(2)确定在生长过程中能将相邻像素包括进来的准则;
(3)指定让生长过程停止的条件或规则。
区域分裂合并:区域生长的逆过程。如:四叉树分解法。
特点:复杂图像效果好、算法复杂、可能破坏区域边界。
分水岭算法:基于拓扑理论的数学形态学分割。对微弱边缘有良好响应。
3、基于边缘检测的分割:
思想:检测不同区域的边缘来分割
方法:串行边缘检测、并行边缘检测
串行边缘检测:确定当前像素点是否属于检测边缘上的一点
,取决于先前像素的验证结果。
并行边缘检测:一个像素点是否属于检测边缘的一点取决于当前正在检测的像素 点以及与该像素点的一些临近像素点。
最简单的方法是并行微分算子法,利用相邻区域的像素值不连续的性质,采用一阶或者二阶导数来检测边缘点。
近年来还提出了基于曲面拟合的方法、基于边界曲线拟合的方法、基于反应-扩散方程的方法、串行边界查找、基于变形模型的方法。
特点:边缘定位准确、速度快、不能保证连续性和封闭性、在高细节区域存在大量碎边缘
改进方向:提取初始边缘点的自适应阈值选取、图像的层次分割的更大区域的选取以及如何确认重要边缘以去除假边缘

- 基于特定工具的图像分割:
- 基于小波变换的图像分割
改进方向:将小波与其他方法结合,如一种局部自适应阈值法是将Hilbert图 像扫描和小波相结合,得到连续光滑的阈值曲线
- 基于遗传算法的图像分割
一种随机化搜索算法。
思想:模拟由一些基因串控制的生物群体的进化过程,把该过程的原理应用到 搜索算法中,以提高寻优的速度和质量
特点:擅长全局搜索、局部搜索能力不足、
改进方向:结合一些启发算法进行改进、充分利用遗传算法的并行机制
- 基于主动轮廓模型的分割
实现主动轮廓模型时,可以灵活的选择约束力、初始轮廓和作用域等,以得到更佳的分割效果。
思想:在给定图像中利用曲线演化来检测目标。先定义初始曲线C,然后根据图像数据得到能量函数,通过最小化能量函数来引发曲线变化,使其向目标边缘逐渐逼近,最终找到目标边缘。
特点:边缘曲线封闭、光滑
传统的主动轮廓模型分为参数主动轮廓模型和几何主动轮廓模型。
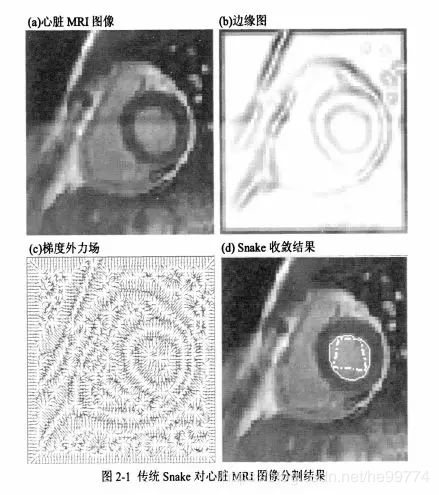
参数主动轮廓模型:将曲线或曲面的形变以参数化形式表达,Kass等人提出了经典的参数活动轮廓模型即“Snake”模型。其中Snake定义为能量极小化的样条曲线,它在来自曲线自身的内力和来自图像数据的外力的共同作用下移动到感兴趣的边缘,内力用于约束曲线形状,外力引导曲线到特征此边缘。
参数主动轮廓模型的特点:将初始曲线置于目标区域附近,无需人为设定曲线的的演化是收缩或膨胀。
优点:能够与模型直接进行交互,且模型表达紧凑,实现速度快;
缺点:难以处理模型拓扑结构的变化。比如曲线的合并或分裂等。使用水平集(level set)的几何活动轮廓方法恰好解决了这一问题
- 基于深度学习的分割:
- 基于特征编码
VGGNet:提取图像特征。特点,不会参数爆炸、学习能力强、占用更多内存。
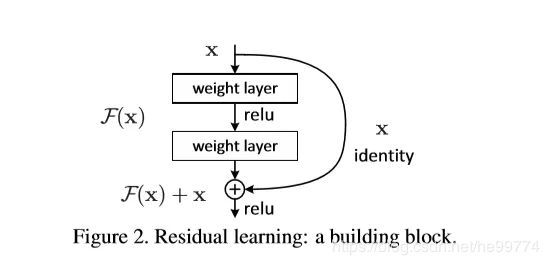
ResNet:思想,在网络中引入恒等映射,允许原始输入信息直接传到后面的层中,在学习过程中可以只学习上一个网络输出的残差F(x),ResNet又叫做残差网络。
特点:可以使网络更深、结构简单、解决深度越深,梯度可能消失的问题、训练时间长。
- 基于区域选择
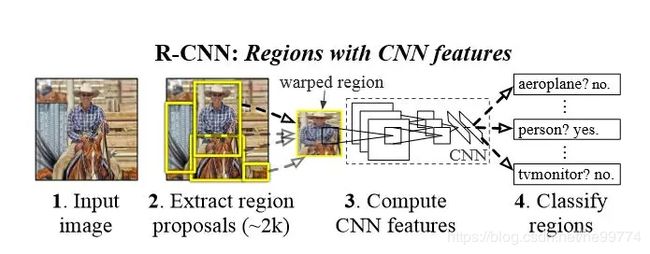
1.R-NN:(Region-based Convolutional Neural Network)使用selective search算法提取2000个候选框,然后通过卷积网络对候选框进行串行的特征提取,再根据提取的特征使用SVM对候选框进行分类预测,最后使用回归方法对区域框进行修正。
特点:首个将深度神经网络应用于目标检测、处理时间长、浪费时间
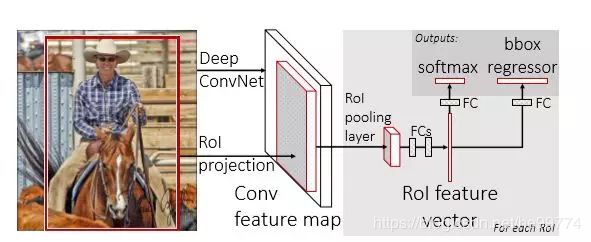
2.Fast R-CNN:R-CNN的改进版。直接使用一个神经网络对整个图像进行特征提取,接着使用一个RoI Pooling Layer在全图的特征图上摘取每一个RoI对应的特征,再通过FC进行分类和包围框的修正。
特点:节省了串行的时间、耗时的selective search算法依然存在。
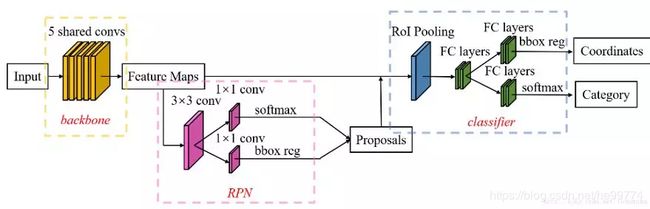
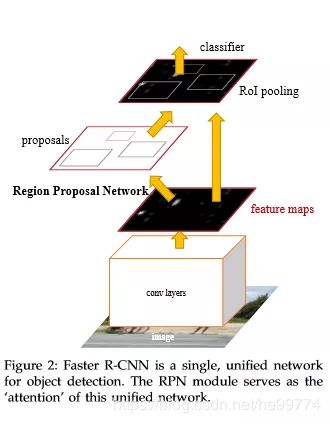
3.Faster R-CNN:将selective search算法替换成为RPN。
特点:目标检测、RPN比selective search速度更快,精度差一点。
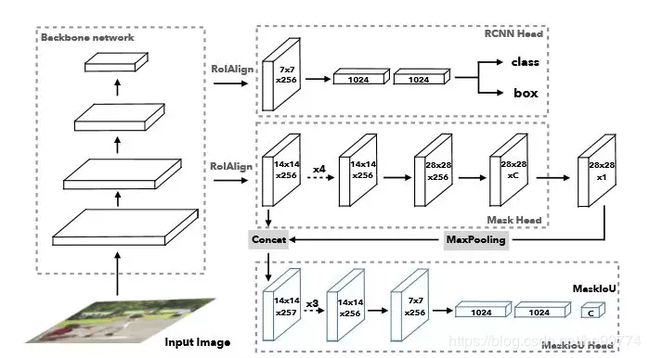
4.Mask R-CNN:基于Faster R-CNN模型的一种新型的分割模型。其主要工作为:目标检测,目标分类,像素级分割。
在Faster R-CNN的结构基础上加上了Mask预测分支,改良了ROI Pooling,提出了ROI Align。
特点:引入了预测用的Mask-Head,以像素到像素的方式来预测分割掩膜,并且效果很好;
用ROI Align替代了ROI Pooling,去除了RoI Pooling的粗量化,使得提取的特征与输入良好对齐;
分类框与预测掩膜共享评价函数,虽然大多数时间影响不大,但是有的时候会对分割结果有所干扰。
5.Mask Scoring R-CNN:在Mask R-CNN的网络基础上,添加了Mask-IoU。
Mask R-CNN评价函数只对目标检测的候选框进行打分,而不是分割模板,所以会出现分割模板效果很差但是打分很高的情况。
Mask Scoring R-CNN增加了对模板进行打分的MaskIoU Head。
特点:提高了预测模板的质量、网络结构有些复杂。
- 基于RNN的图像分割
ReSeg模型:语义分割方法。使用RNN去检索上下文信息,以FCN的不足作为分割的一部分依据。核心就是Recurrent Layer,它由多个RNN组合在一起,捕获输入数据的局部和全局空间结构
FCN的不足:没有考虑到局部或者全局的上下文依赖关系,在语义分割中这种依赖关系是非常有用的。
特点:考虑上下文信息关系。使用了中值频率平衡,它通过类的中位数(在训练集上计算)和每个类的频率之间的比值来重新加权类的预测。这就增加了低频率类的分数,这是一个更有噪声的分割掩码的代价,因为被低估的类的概率被高估了,并且可能导致在输出分割掩码中错误分类的像素增加

MDRNNs模型:(Multi-Dimensional Recurrent Neural Networks)将RNN扩展到多维空间领域,思想:将单个递归连接替换为多个递归连接,可以在一定程度上解决时间随数据样本的增加呈指数增长的问题。

- 基于上采样/反卷积的分割
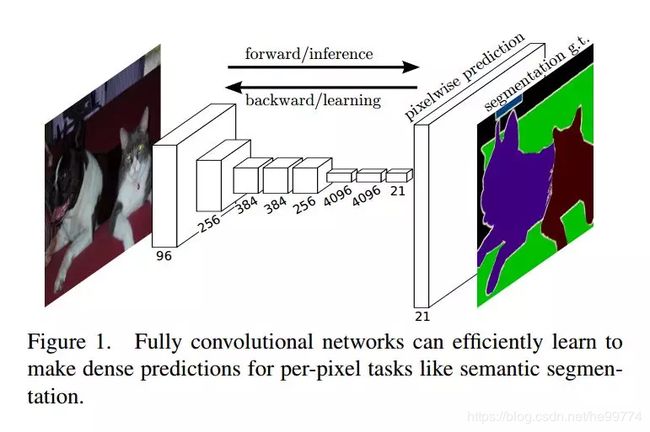
FCN:在FCN当中的反卷积-升采样结构中,图片会先进性上采样(扩大像素);再进行卷积—通过学习获得权值。
特点:进行了像素级的分类,解决了语义级别的图像分割问题、可以接受任意尺寸的输入图像、保留原始输入图像的空间信息、由于上采样结果比较模糊和平滑,对图像中的细节不敏感、没有充分考虑像素与像素的关系,缺乏空间一致性。
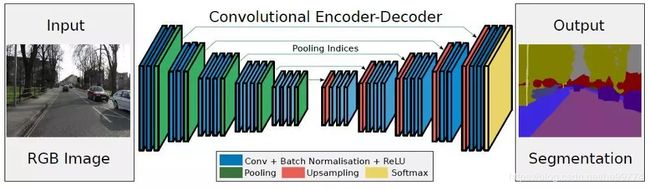
SetNet:解决自动驾驶或智能机器人的图像语义分割深度网络,基于FCN,其编码-解码器和FCN的稍有不同,其解码器中使用去池化对特征图进行上采样,并保持高频细节的完整性;而编码器不使用全连接层,因此网络的参数较少。
特点;保存了高频部分的完整性、网络参数少、分类的边界位置置信度低
- 基于提高特征分辨率的分割
恢复在深度卷积神经网络中下降的分辨率,从而获取更多的上下文信息。
DeepLab:结合了深度卷积神经网络和概率图模型,应用在语义分割的任务上,目的是做逐像素分类,其先进性体现在DenseCRFs(概率图模型)和DCNN的结合。是将每个像素视为CRF节点,利用远程依赖关系并使用CRF推理直接优化DCNN的损失函数。
FCN是先进行卷积再进行pooling,这样在降低图像尺寸的同时增大感受野,但是在先减小图片尺寸(卷积)再增大尺寸(上采样)的过程中一定有一些信息损失掉了,所以这里就有可以提高的空间。
DeepLab改进:Dilated/Atrous Convolution,它的采样方式是带有空洞的采样。在VGG16中使用不同采样率的空洞卷积,可以明确控制网络的感受野。
特点:内部数据结构丢失、小物体信息无法重建
- 基于特征增强的分割
提取多尺度特征或者从一系列嵌套的区域中提取特征。在图像分割领域,能够覆盖到更大部分的上下文信息的深度网络通常在分割的结果上更加出色,当然这也有更高的计算代价。
SLIC:(simple linear iterative cluster, 简单线性迭代聚类) 生成超像素的算法。与聚类的K-Means算法类似,最终得到K个超像素。
Zoom-Out:使用了SLIC,从多个不同的级别提取特征:局部级别的超像素本身、远距离级别的能够包好整个目标的区域;全局级别的整个场景。
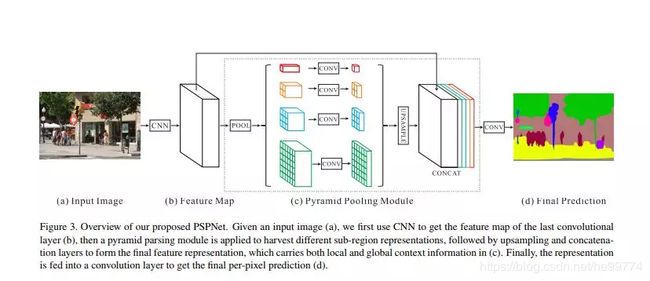
PSPNet:(Pyramid Scene Parsing Network, 金字塔场景解析网络),提出了一个具有层次全局优先级,包含不同子区域时间的不同尺度的信息,称之为金字塔池化模块。
FCN的典型问题:上下文推断能力不强、标签之间的关系处理不好、模型可能会忽略小的东西。
- 使用CRF/MRF的方法
MRF:(Marcov Random Field, 马尔可夫随机场) 基于统计的图像分割算法。
CRF:(Conditional Random Field, 条件随机场) 一种特殊的MRF。
DenseCRF:全连接条件随机场,运用CRF于图像分割领域。
特点:在精细部位分割效果好、考虑了像素点或图片区域之间的上下文关系、粗略的分割中可能会消耗不必要的算力、可用来恢复细致的局部结构,但是需要较高代价。
相关论文:
区域生长:选择合适的初始种子像素以及合理的生长准则
分水岭算法
小波变换
遗传算法
VGGNet
ResNet
Mask R-CNN
【部分名词解释】:
感受野:感受器受刺激兴奋时,通过感受器官中的向心神经元将神经冲动(各种感觉信息) 传到上位中枢,一个神经元所反应(支配)的刺激区域就叫做神经元的感受野。
掩膜:对处理的图像(全部或局部)进行遮挡,来控制图像处理的区域或处理过程。用于覆 盖的特定图像或物体称为掩模。
梯度消失/爆炸:https://dwz.cn/gZJDJymn
FCN:全卷积网络。
上采样:重采的采样率与原来获得该数字信号(比如从模拟信号采样而来)的采样率比较, 大于原信号的称为上采样,小于的则称为下采样。上采样的实质也就是内插或插值。
语义分割:将像素按照图像中表达语义含义的不同进行分组或分割。
置信度:在抽样对总体参数作出估计时,由于样本的随机性,其结论总是不确定的。置信度 即总体参数值落在样本统计值某一区域内的概率。
Dilated/Atrous Convolution
超像素:把像素级的图像划分成为区域级(district-level)的图像,把区域当成是最基本的处理单元,这就是超像素。