NLP入门-Task9 Attention原理
Attention原理
- 注意力机制
- 注意力机制应用
- 层级注意力模型
注意力机制
注意力机制(Attention Mechanism)是解决信息超载问题的一种资源分配方案,将计算资源分配给更重要的任务。
注意力机制的计算可以分为两步:一是在所有输入信息上计算注意力分布,二是根据注意力分布来计算输入信息的加权平均。
注意力分布采用一种“软性”的信息选择机制,首先计算在给定q和X下,选择第i个输入信息的概率αi:

其中αi 称为注意力分布(Attention Distribution),s(xi, q)为注意力打分函数。
加权平均采用一种“软性”的信息选择机制对输入信息进行汇总。
软性注意力机制(Soft Attention Mechanism):
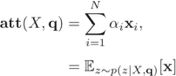
软性注意力选择的信息是所有输入信息在注意力分布下的期望。
硬性注意力(Hard Attention)只关注到某一个位置上的信息,有两种实现方式:一种是选取最高概率的输入信息,即 att(X, q) = xj , 其中j为概率最大的输入信息的下标,即![]()
另一种是通过在注意力分布式上随机采样的方式实现。
硬性注意力的一个缺点是基于最大采样或随机采样的方式来选择信息。最终的损失函数与注意力分布之间的函数关系不可导,因此无法使用在反向传播算法进行训练。为了使用反向传播算法,一般使用软性注意力来代替硬性注意力。
键值对注意力用键值对(key-value pair)格式来表示输入信息,其中“键”用来计算注意力分布 αi,“值”用来计算聚合信息。
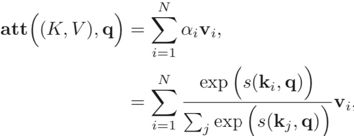
其中s(Ki,q)为打分函数当K = V时,键值对模式就等价于普通的注意力机制。
多头注意力(Multi-Head Attention)是利用多个查询Q = [q1, · · · , qM ],来平行地计算从输入信息中选取多个信息。每个注意力关注输入信息的不同部分。
结构化注意力,输入信息本身具有层次(hierarchical) 结构,比如文本可以分为词、句子、段落、篇章等不同粒度的层次,可以使用层次化的注意力来进行更好的信息选择。
注意力机制应用
注意力机制主要是用来做信息筛选,从输入信息中选取相关的信息。指针网络(Pointer Network) 只利用注意力机制中的第一步,将注意力分布作为一个软性的指针(pointer)来指出相关信息的位置。是一种序列到序列模型,输入是长度为n的向量序列X = x1, · · · , xn,输出是下标序列c1:m = c1, c2, · · · , cm, ci ∈[1,n],∀i。
当使用神经网络来处理一个变长的向量序列时,可以使用卷积网络或循环网络进行编码来得到一个相同长度的输出向量序列,基于卷积或循环网络的序列编码都是可以看做是一种局部的编码方式,只建模了输入信息的局部依赖关系。虽然循环网络理论上可以建立长距离依赖关系,但是由于信息传递的容量以及梯度消失问题,实际上也只能建立短距离依赖关系。
建立输入序列之间的长距离依赖关系有两种方法: 一种方法是增加网络的层数,通过一个深层网络来获取远距离的信息交互。另一种方法是使用全连接网络。全连接网络是一种非常直接的建模远距离依赖的模型,但是无法处理变长的输入序列。不同的输入长度,其连接权重的大小也是不同的。
自注意力模型(Self-Attention Model) 利用注意力机制来“动态”地生成不同连接的权重,自注意力模型可以作为神经网络中的一层来使用,既可以用来替换卷积层和循环层,也可以和它们一起交替使用。自注意力模型计算的权重αij只依赖,qi和kj的相关性,而忽略了输入信息的位置信息。在单独使用时,自注意力模型一般需要加入位置编码信息来进行修正。
层级注意力模型
层级注意力模型来自《Hierarchical Attention Networks for Document Classification》,文章主要内容有:利用文档原有的层次结构特性(句子是由单词组成,文档是由句子组成),先使用单词的词向量表示句子,再此基础上以句子向量构建文档的信息表示。在文档中,句子对文档的重要性贡献有差异,在句子中单词对句子的重要性贡献也有差异。而单词和句子的重要性依赖于上下文环境。相同的单词,在不同的上下文中所表现出的重要性是不一样的。为了描述这种情况,引入了Attention机制来描述这种重要性。分别从句子级和文档级两个层次使用Attention机制。Attention机制可以带来两个优点:一个可以提升分类性能,第二个可以提升识别出在影响最终分类决策的单词或句子的重要性。
Attention机制应用的假设是对句子的含义,观点,情感等任务,每个单词的贡献是不相同的。因此,使用Attention机制去抽取更重要的单词。模型网络结构如图所示:
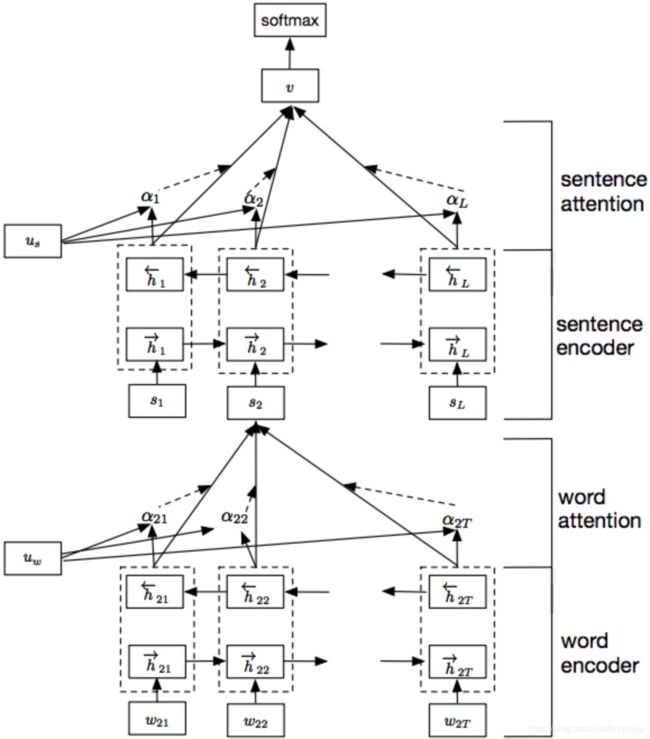
包括五层网络,词向量编码(GRU),词向量Attention层,句子向量编码(GRU),句子向量Attention层,softmax输出层.整个网络通过将一个句子分割为几部分,每部分都使用双向RNN结合“注意力”机制将小句子映射为一个向量,然后对于映射得到的一组序列向量,再通过一层双向RNN结合“注意力”机制实现对文本的分类。
单词词向量:查询词向量表(比如GloVe,Word2Vec等)生成句子中每个单词的词向量,并将句子表示为单词词向量的连接句子。

其中Xit为单词向量,表示的就是句子中每个单词的词向量表示,句子的总长度为T。
每个单词词向量的隐状态就表示为前向和后向单词隐状态的连接,这种表示方法就表示了以某个单词为中心的句子相关信息。
单词级Attention:因为句子中每个单词的重要性不相同,因此使用Attention机制描述每个单词的重要性,抽取相对句子含义重要的那些单词,使用这些重要的词的词向量组成句子的向量表示。

通过一个线性层对双向RNN的输出进行变换,然后通过softmax公式计算出每个单词的重要性,最后通过对双向RNN的输出进行加权平均得到每个句子的表示。其中uw在初始时随机初始化,在训练阶段学习获得。bw也是学习获得。
句子级向量:

句子级Attention:
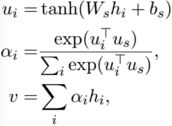
将最后句子级向量表示的文档输入softmax层,计算分类。
![]()
交叉熵损失函数:
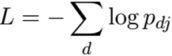
实现代码参考别人的github项目:
https://github.com/GeneralZh/hierarchical-attention-networks
参考
《神经网络与深度学习》
文献阅读笔记:Hierarchical Attention Networks for Document Classification
多层注意力模型:Hierarchical Attention Networks for Document Classification