第一阶段-入门详细图文讲解tensorflow1.4 -(四)新手MNIST
MNIST:机器学习中的helloWorld。是一个入门级的计算机视觉数据集。
它包含各种手写数字图片:

上面这4张图片的标签是5,0,4,1。
官方的文档比较啰嗦,简而言之。
最终目的:使用tensorflow训练一个手写体图像识别模型,识别一张手写数字照片。
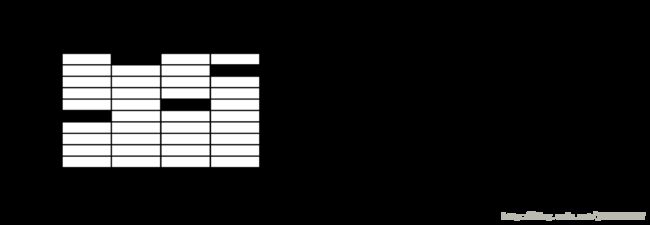
Step1:MNIST训练图片数据。
图片:28像素X28像素预处理之后的照片。
训练集:55000行
预测集:10000行
交叉验证集:5000行
mnist.train.images 是一个形状为 [55000, 784] 的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于0和1之间。

one-hot vectors数字n将表示成一个只有在第n维度(从0开始)数字为1的10维向量。
比如,标签0将表示成([1,0,0,0,0,0,0,0,0,0,0])。mnist.train.labels是一个形状 [55000, 10] 的张量。
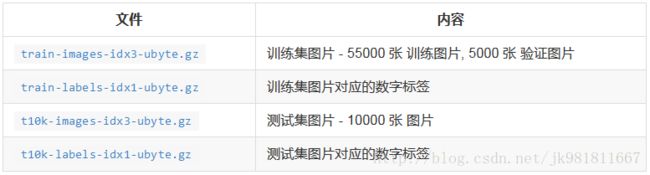
MNIST_data百度网盘地址:https://pan.baidu.com/s/1cjm7tc
input_data.py百度网盘地址:https://pan.baidu.com/s/1c21zu4C
input_data.py用于下载训练和测试的MNIST数据集的python源码。
step2:softmax regression讲解
我们希望得到10种分类的可能性probabilities,结果才能更好的理解。
就需要使用softmax回归。
第一步:加权求和(线性回归)
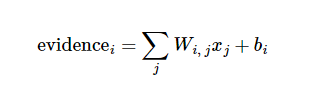
这个公式大家都很熟悉。
应用到MNIST上的解释:j是1到784,一共有784*10个权重和10偏移量需要确定。(不理解,给你看张图。)
i表示1到55000个训练样例。

写成公式:

784*10个权重就是每一行有784个权重,共分为10类。明白啦吧。
同理仅需要10个偏移量。
关于W权重怎么理解?蓝色表示负值,红色表示正值。
如果为负值,表示该像素点的灰度值很强的不属于这个类别划分。
如果为正值,表示该像素点的灰度值很强的属于这个类别划分。

第二步:softmax函数,( activation function or line function )
我们知道线性回归出来的结果是离散值,人们很难直接读懂结果的程度。大家想得到的是一种可能性,于是如何将离散值映射成概率。成为待解决的问题。
人们发现使用:
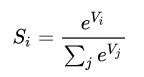
例如通过加权求和得到(8,2,1,2,1,3,2,0,2,2)进过softmax函数计算得到
(8/23,2/23,1/23,2/23,1/23,3/23,2/23,0/23,2/23,2/23)显然是一种概率结果。并且有更好的理解。
当然为了方便理解,没有加归一化操作。
ok,忽略一些细节,先记住这些能够能帮助你快速理解核心。深入理解softMax
step3:开始tensorflow编程实现MNIST
为了高效编程,(就好比盖房子,我们不用自己去做砖头,直接使用砖厂的砖头付点钱,这样盖房子就很高效。)我们需要使用函数库,比如NumPy。
没有装的话先安装。
conda install -n python35tf numpy
# 如果不用-n指定环境名称,则被安装在当前活跃环境如果觉得速度慢添加清华大学的TUNA源。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
ok.正式开始写代码。
首先导入它:
import tensorflow as tfx = tf.placeholder("float", [None, 784])x是一个占位符placeholder,不明白placeholder请看第一阶段-入门详细图文讲解tensorflow1.4 -(三)TensorFlow 编程基础知识。这个张量的形状是[None,784 ]。(这里的None表示此张量的第一个维度可以是任何长度的。)可以输入任意数量的MNIST图像。
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))我们赋予tf.Variable全为零的张量来初始化W和b。它们的初值可以随意设置。
注意,W的维度是[784,10],b的形状是[10]。不理解看上图。
y = tf.nn.softmax(tf.matmul(x,W) + b)我们的模型一行代码搞定。
如何运行我们的模型呢???
我们迭代运行的是模型的损失函数,不断改变W,b让损失函数的值趋近最小。
构建损失函数,是神经网络的核心。
我们使用交叉熵(cross-entropy),

先简单理解:存在一个是真实分布构建,一个是预测分布构建(交叉熵),(就是55000个样本图片分类结果的分布),记住一个结论:预测分布构建永远大于等于真实分布构建。只需要取得预测分布构建的最小值就能逼近真实分布啦。
后面有专题讲解:熵,交叉熵。
怎么计算交叉熵的最小值???
backpropagation algorithm and gradient descent algorithm 。
反向传播,梯度下降简单理解:反向传播是神经网络的基础。梯度下降是一种计算方式。
有专题讲解:神经网络的基础反向传播。
再回到最初的目的,运行我们的模型。
#预测结果y_,我们使用占位符表示。
y_ = tf.placeholder(tf.float32, [None, 10])
#构建交叉熵公式
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
#使用梯度下降计算交叉熵的最小值
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)目前还是不能直接运行。
还记得上节说过,首先我们要显示初始化Variable,接着定义一个Session。
#定义session
sess = tf.InteractiveSession()
#初始化所有全局变量
tf.global_variables_initializer().run()
#每一次随机选取100个训练样本,填充到train_step,迭代1000次。
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})终于可以运行模型了,我们好像得不到什么输出。
而且我们不知道模型的好坏???
评估我们的模型 。
#tf.equal做比较,tf.argmax在某一维上的其数据最大值所在的索引值。(one-hot vectors)设计的多么巧妙。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
#correct_prediction的结果[True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75,直接得到正确率。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
#accuracy应用在模型中。并打印每一步的准确率。
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})step4:总结一下上述代码
以下是mnist_softmax.py文件源码。
# -*- coding: utf-8 -*-
"""
A very simple MNIST classifier.
See extensive documentation at
http://tensorflow.org/tutorials/mnist/beginners/index.md
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
# Import data
#from tensorflow.examples.tutorials.mnist import input_data
import input_data
import tensorflow as tf
mnist = input_data.read_data_sets("Mnist_data/", one_hot=True)
sess = tf.InteractiveSession()
# Create the model
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
# Define loss and optimizer
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
# Train
tf.initialize_all_variables().run()
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
train_step.run({x: batch_xs, y_: batch_ys})
# Test trained model
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(accuracy.eval({x: mnist.test.images, y_: mnist.test.labels}))运行结果:

新手MNIST结束。
大家想想怎样提高准确率???